Tag Archives: 289A
Math 289A: Formalism of Schur-Horn Arrays
The right way to set up the classical limit theorems of probability theory is to start with a triangular array of real random variables

Your first exposure to the law of large numbers and central limit theorem likely involved a different setup, namely an infinite sequence

of iid random variables, whose partial sums

are the main object of interest. There are some non-negligible advantages to the triangular array setup, for example the fact that the rows do not have to be defined on a common underlying probability space. The 

is the topic of slightly more advanced and flexible versions of the central limit theorem. This result and other classical limit theorems apply to the situation when the random variables in each row of the triangular array are independent or nearly independent.
We are interested in triangular arrays of random variables as above which arise from an underlying deterministic data set

The triangular array of random variables associated to this data has rows defined by

where ![U_N=[U_{ij}]](https://s0.wp.com/latex.php?latex=U_N%3D%5BU_%7Bij%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
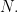




There are two ways to think about a Schur-Horn array. Geometrically, 


We are interested in proving limit theorems for Schur-Horn arrays. Such theorems will describe 


converges in moments as 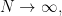


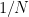

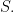

exists for each fixed 

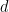
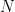
Let 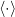

be the characteristic function of 



where

and the sum is over all vectors 





where 




where the quantities 
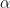
The main fact about Schur-Horn arrays that allows us to understand them is a second formula for the cumulant polynomials
Theorem (Cumulant Formula for Schur-Horn Arrays). For each 

where the sums are over nonnegative integer vectors 



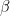




Finally,

is a convergent series in which the coefficients 
The cumulant formula for Schur-Horn arrays looks complicated, but it is fairly easy to use in practice. For example, let us set our scaling exponent to 


As we saw (twice) in lecture, you can calculate the 


This means that

unless 
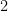
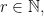


When our scaling exponent is 

for each fixed

where 



is the free cumulant sequence corresponding to the moment sequence

Math 289A: Lecture 15
Today we want to prove the “inverse Wigner theorem” we started discussing last time. Let 





exists for each 

with 





with
Theorem 15.1. For any fixed 



for any vector 
Here is a corollary which further explains why we are calling Theorem 15.1 an inverse Wigner theorem.
Corollary 15.1. For any 


Problem 15.1. Deduce Corollary 15.1 from Theorem 15.1.
The rest of the lecture consists of the proof of Theorem 15.1. First, let us explain the assumption that our deterministic data

So, assuming 
Now we start the proof. The joint distribution of

is an entire function of the complex variables 






where 

which in the standard monomial basis of homogeneous polynomials is

the sum being over all vectors 



the sum being over weak 
In fact, it is more convenient to work with the log-Laplace transform of 



Let

be the Maclaurin expansion of this analytic function, so 

We can write the polynomial 

except for the subscript on the expectation-like quantity $\langle X_{N1}^{\alpha_1} \dots X_{NN}^{\alpha_N}\rangle_c$, which is known as a degree
Problem 15.2. Show that 


Our discussion so far pertains to any finite family of random variables with compactly supported joint distribution. Now we will start invoking special features of the family
Theorem 15.2 (Leading Cumulants Formula). For any

where each sum is over the set of integer partitions of

is a convergent power series in 
The combinatorial coefficients
To leverage this, let us restrict to the cumulant polynomials of 


Ignore the factor of 

Reading from right to left, we have that 
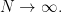

Finally, since

we have

as 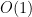

as 
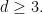


uniformly on compact subsets of 

Finally, the polynomial 

each of which converges to
Problem 15.3. Compute the joint cumulants of a finite family of centered iid Gaussians and complete the proof.
Math 289A: Lecture 14
In this lecture I wanted to connect our (admittedly meandering) discussion so far to the standard approach to limit theorems in random matrix theory. Let

This means precisely that the distribution of 
Definition 14.1. The Gaussian Unitary Ensemble is the sequence

The word “unitary” here means that the distribution of 
Theorem 14.1 (Wigner). For each

exits and is given by

In Theorem 14.1, 

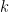
Concerning the meaning of Theorem 14.1, the random variable

is the degree 




is essentially a Bessel function. Then, a classical integral representation for Bessel functions allows one to determine that 
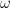
![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

You can find the details of this derivation here, towards the end of Lecture One.
Now we discuss how one can prove Theorem 14.1. The proof uses the fact that power sums in the eigenvalues of a matrix are also traces of powers of that matrix. This means that we have

the point being that the right hand side is also a polynomial in the elements 

where the sum is over all functions

Using the fact that the matrix elements of
Theorem 14.2 (Harer-Zagier). For each
![\mathbf{E}\left[\frac{1}{N} \mathrm{Tr} (\frac{1}{\sqrt{N}}X_N)^d\right] = \sum\limits_{g=0}^\infty N^{-2g} E_g^d,](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5Cleft%5B%5Cfrac%7B1%7D%7BN%7D+%5Cmathrm%7BTr%7D+%28%5Cfrac%7B1%7D%7B%5Csqrt%7BN%7D%7DX_N%29%5Ed%5Cright%5D+%3D+%5Csum%5Climits_%7Bg%3D0%7D%5E%5Cinfty+N%5E%7B-2g%7D+E_g%5Ed%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where 



There is something unsatisfying about the above sequence of ideas. We know that the entire distribution of

which are simply iid standard Gaussians. In fact, at this point in the course we know much more: the spectral analysis of unitarily invariant random Hermitian matrices is equivalent to the analysis of pairs

and

of triangular arrays of real random variables related by

where ![U_N=[U_N(i,j)]](https://s0.wp.com/latex.php?latex=U_N%3D%5BU_N%28i%2Cj%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

This point of view is why the paper of Olshanski-Vershik is so relevant for our purposes, and so far ahead of its time: they are proving inverse theorems of this kind. More precisely, they are considering the case where the
Theorem 14.3 (Olshanski-Vershik). Suppose that the limit

exists for each 

We have proved the one-dimensional version of this Gaussian limit theorem (the case 

Math 289A: Lecture 13
Let 





whose

consists of the diagonal elements of the random matrix 

This is superficially similar to the setup for the Central Limit Theorem, but it is different: 

In this lecture I will use the angled brackets notation favored by physicists to denote expectation. I will also use the angled bracket with a subscript “

Problem 13.1. Prove that 



Our Optimized Leading Cumulants Formula says that for any 

where

and

is 
What is nice about the Optimized Leading Cumulants Formula is that it almost immediately suggests the possibility of Gaussian limiting behavior: because of the factor 
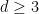
This is not so difficult. We have the finite sum

and the number of terms in the sum has no dependence on 

The denominator is literally just a power of

where 

We therefore have the cumulant bound

where 
Theorem 13.1. If the input sequence 

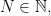


Proof: By definition the first cumulant of 


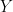

-QED
Math 289A: Lecture 12
This week we will finish working through the Olshanski-Vershik limit theorem, and explain how the tools we have developed along the way have set us up to prove other kinds of limit theorems about random matrices.
Recall the setting of the OV paper: we have an infinite triangular array of real numbers,

Assume the entries are sorted so that each row is non-increasing from left to right and let

be the 

We know that in the characteristic function of

we can assume without loss in generality that 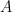

corresponding to our data set 

or equivalently
![K_N(a_1,\dots,a_N) = \mathbb{E}\left[e^{i(a_1X_N(1,1)+\dots+a_NX_N(N,N))}\right], \quad A \in \mathbb{R}^N,](https://s0.wp.com/latex.php?latex=K_N%28a_1%2C%5Cdots%2Ca_N%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7Bi%28a_1X_N%281%2C1%29%2B%5Cdots%2Ba_NX_N%28N%2CN%29%29%7D%5Cright%5D%2C+%5Cquad+A+%5Cin+%5Cmathbb%7BR%7D%5EN%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where the diagonal matrix elements 

of a single diagonal 


showing explicitly how 

The characteristic function 

where ![K_N^d=\mathbf{E}[X_N^d(1,1)]](https://s0.wp.com/latex.php?latex=K_N%5Ed%3D%5Cmathbf%7BE%7D%5BX_N%5Ed%281%2C1%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002)


Theorem 12.1 (Leading Moments Formula). For each

where the inner sum is absolutely convergent and 
The most efficient way to use this result is to take a logarithm, i.e. to work with the cumulants of
Let

be the log-characteristic function of 





The cumulants

Theorem 12.2 (Leading Cumulants Formula). For each

where 
The Leading Cumulants Formula is identical to the Leading Moments formula except that the walk count
Theorem 12.3 (Riemann-Hurwitz Formula). The number 

Due to the Riemann-Hurwitz formula it is more convenient to parameterize the numbers 

Theorem 12.4 (Optimized Leading Cumulants Formula). For each

Now we are in position to prove some interesting limit theorems. We begin by proving one such theorem corresponding to an explicit choice of the dataset
Let 

where the number of positive and negative entries is as near to equal as possible – equal if 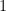
Theorem 12.5 (Gaussian Limit Theorem). Any diagonal matrix element of
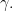
Proof: Let 

and therefore

Thus, from the Optimized Leading Cumulants Formula we have

showing that 

The first cumulant of

and this converges to 

and

Thus, we have shown that 

-QED
Math 289A: Lecture 10
We start with a brief recap of what we are trying to achieve – since things are getting complicated it might be helpful to step back for a moment before stepping further in.
Let 

where 

This group action is called unitary conjugation. Let

denote the orbit of a given Hermitian matrix 
Theorem 10.1 (Spectral Theorem). For every 
Let

We will refer to this orthant of 

where on the right hand side we are viewing
A standard problem in linear algebra is the following: we are given a matrix 




We are interested in solving a generic version of the inverse problem: given 


We want to solve this inverse problem by computing the characteristic function of
![\varphi_{X_N}(T) = \mathbf{E}\left[e^{i\langle T,U_NBU_N^*\rangle}\right]=\int\limits_{\mathbb{U}_N}e^{i \mathrm{Tr}TUBU^*} \mathrm{d}U.](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX_N%7D%28T%29+%3D+%5Cmathbf%7BE%7D%5Cleft%5Be%5E%7Bi%5Clangle+T%2CU_NBU_N%5E%2A%5Crangle%7D%5Cright%5D%3D%5Cint%5Climits_%7B%5Cmathbb%7BU%7D_N%7De%5E%7Bi+%5Cmathrm%7BTr%7DTUBU%5E%2A%7D+%5Cmathrm%7Bd%7DU.&bg=FFFFFF&fg=000&s=0&c=20201002)
We know that it is in fact sufficient to do this for 

in order to emphasize the fact that we can view this characteristic function as defining a bounded symmetric kernel

Furthermore, 
We can view
![K_N(A,B) = 1 + \sum\limits_{d=1}^\infty \frac{i^d}{d!} \sum\limits_{\gamma \in \mathsf{C}_N^d} a_1^{\gamma_1} \dots a_N^{\gamma_N} \mathbf{E}\left[ X_N^{\gamma_1}(1,1) \dots X_N^{\gamma_N}(N,N)\right] K_N(\gamma),](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+1+%2B+%5Csum%5Climits_%7Bd%3D1%7D%5E%5Cinfty+%5Cfrac%7Bi%5Ed%7D%7Bd%21%7D+%5Csum%5Climits_%7B%5Cgamma+%5Cin+%5Cmathsf%7BC%7D_N%5Ed%7D+a_1%5E%7B%5Cgamma_1%7D+%5Cdots+a_N%5E%7B%5Cgamma_N%7D+%5Cmathbf%7BE%7D%5Cleft%5B+X_N%5E%7B%5Cgamma_1%7D%281%2C1%29+%5Cdots+X_N%5E%7B%5Cgamma_N%7D%28N%2CN%29%5Cright%5D+K_N%28%5Cgamma%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where the internal sum runs over the set 




But, it is Haard (sorry, couldn’t resist) to see how to directly compute all mixed moments of the random variables 

which is obtained from 
But

where the internal (double) sum is over the set 





This leaves the problem of computing the coefficients 


Theorem 10.1. For every integer 

where the series is absolutely convergent and 

Clearly there is much to be unpacked here, but ultimately it is not so complicated, and moreover only a small amount of the information contained in this statement is needed to prove limit theorems about random matrices. A very basic observation is that in the range 
Now we have to explain what we mean by the Cayley graph of the symmetric group, and what we mean by a monotone walk on this graph. For this I am linking to a paper which hopefully provides a reasonably clear account of this combinatorial construction (all you need to read is Section 2.1 and 2.2, just a couple of pages). After you have read this you will know what the Cayley graph of the symmetric group is, what is meant by a strictly monotone walk on this graph. Furthermore, you will know the remarkable fact that there is a unique strictly monotone walk between any two permutations, and this walk is a geodesic.
As explained in lecture, it is often the case that the logarithm of the characteristic function is easier to work with than the characteristic function itself – it is a generating function for cumulants rather than moments. Let us consider the logarithm of the characteristic function of 

Math 289A: Lecture 9
This week we are looking at a landmark paper by Grigori Olshanski and Anatoly Vershik, “Ergodic Unitarily Invariant Measures on the Space of Infinite Hermitian Matrices.” This paper is among the first to consider characteristic functions in the context of random matrix theory. Namely, it considers the problem of approximating the function

defined by

where the integration is over the unitary group of rank 



of 
One way to simplify the question is to consider the restriction of 
![K_N(a_1,\dots,a_r,0,\dots,0;b_1,\dots,b_N) = \mathbb{E}\left[e^{i(a_1X_N(1,1) + \dots +a_r X_N(r,r))}\right]](https://s0.wp.com/latex.php?latex=K_N%28a_1%2C%5Cdots%2Ca_r%2C0%2C%5Cdots%2C0%3Bb_1%2C%5Cdots%2Cb_N%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7Bi%28a_1X_N%281%2C1%29+%2B+%5Cdots+%2Ba_r+X_N%28r%2Cr%29%29%7D%5Cright%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
of only the first 



The Olshanski-Vershik approach of computing the asymptotics of the characteristic function

is based on series expansion of this matrix integral. I am a big proponent of this approach, but it does require some quite extensive background from representation theory and algebraic combinatorics which is not traditionally found in the realm of probability. We will try not to get too bogged down in the algebra, and in order to do this it will be necessary to accept some results from representation theory as black boxes.
First, let us analytically continue the characteristic function 

by declaring

where 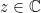






The analytic function 


where 

where 






Our objective then is to calculate the numerical coefficients 
Problem 9.1. Show that 

What is good about the Newton polynomials is that they connect us to point configurations, which is what we want. More precisely, if 

This means that writing the Maclaurin expansion of $K_N(z,A,B)$ in terms of Newton symmetric polynomials is exactly what we want to do, because it is expressing this function in terms of the empirical distributions of its arguments
Unfortunately, there is no obvious way to calculate the Newton coefficients 


This gives us the formula

which at least reduces our initial problem of computing an exponential integral over 

but still there is no obvious path forward.
At this point we should ask ourselves what integrals over 



Representation theory gives us analogous formulas for all 

Defintion 9.1. For each 
![s_\lambda(t_1,\dots,t_N) = \frac{\det [t_j^{N-i+\lambda_i}]}{\det[t_j^{N-i}]},](https://s0.wp.com/latex.php?latex=s_%5Clambda%28t_1%2C%5Cdots%2Ct_N%29+%3D+%5Cfrac%7B%5Cdet+%5Bt_j%5E%7BN-i%2B%5Clambda_i%7D%5D%7D%7B%5Cdet%5Bt_j%5E%7BN-i%7D%5D%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where 
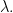
Out of the many equivalent definitions of Schur polynomials, we are taking this one because it is a fairly explicit and elementary formula. Indeed, the determinant in the denominator is the Vandermonde determinant, which has the property that it divides any other antisymmetric polynomial in 
Problem 9.2. Let 

The disadvantage of Definition 9.1 is that it makes the orthogonality relations for Schur polynomials, which are really consequences of the fact that these polynomials are characters of irreducible representations of 



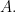
Theorem 9.1 (Schur orthogonality). For any two Young diagrams 


and

where 
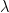

We also need a remarkable “multinomial formula” due to Frobenius. Let 
Theorem 9.2 (Frobenius formula). We have

where 
The reason the tableaux counts 



Theorem 9.3 (Schur expansion of

Proof: From the Theorem 9.2, we have

and applying the first integration formula in Theorem 9.1 this becomes

– QED
Problem 9.3. Compute the Schur expansion of 
Let us include the analogue of Theorem 9.3 for the quantum Bessel kernel

where 






where 
Theorem 9.4 (Schur expansion of

We close this lecture with a pointer to interesting work in the engineering literature which considers exactly these integrals in an applied context.