The right way to set up the classical limit theorems of probability theory is to start with a triangular array of real random variables

Your first exposure to the law of large numbers and central limit theorem likely involved a different setup, namely an infinite sequence

of iid random variables, whose partial sums

are the main object of interest. There are some non-negligible advantages to the triangular array setup, for example the fact that the rows do not have to be defined on a common underlying probability space. The  behavior of the row sums
behavior of the row sums

is the topic of slightly more advanced and flexible versions of the central limit theorem. This result and other classical limit theorems apply to the situation when the random variables in each row of the triangular array are independent or nearly independent.
We are interested in triangular arrays of random variables as above which arise from an underlying deterministic data set

The triangular array of random variables associated to this data has rows defined by

where ![U_N=[U_{ij}]](https://s0.wp.com/latex.php?latex=U_N%3D%5BU_%7Bij%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is a uniformly random unitary matrix of rank
is a uniformly random unitary matrix of rank 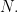 Thus, the random vector
Thus, the random vector  is a random linear transformation of the deterministic data
is a random linear transformation of the deterministic data  Because the entries of
Because the entries of  are highly correlated (rows are orthonormal, columns are orthonormal) the random variables
are highly correlated (rows are orthonormal, columns are orthonormal) the random variables  are far from independent. They are, however, exchangeable.
are far from independent. They are, however, exchangeable.
There are two ways to think about a Schur-Horn array. Geometrically, is a random point inside the permutahedron in  generated by Algebraically, is the diagonal of the random matrix
generated by Algebraically, is the diagonal of the random matrix  , where
, where 
We are interested in proving limit theorems for Schur-Horn arrays. Such theorems will describe behavior of the rows of the  -array in terms of prescribed behavior of the rows of the
-array in terms of prescribed behavior of the rows of the  -array. In particular, we are interested in the situation where the empirical distribution of the vector
-array. In particular, we are interested in the situation where the empirical distribution of the vector

converges in moments as 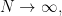 where
where  is a scaling exponent. The empirical distribution is the probability measure on
is a scaling exponent. The empirical distribution is the probability measure on  which places mass
which places mass 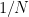 at each coordinate of the vector If we think of these data points as beads on a wire, then the empirical measure of
at each coordinate of the vector If we think of these data points as beads on a wire, then the empirical measure of  is the fraction of beads which lie in
is the fraction of beads which lie in 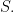 Convergence in moments of the empirical measure means that the the limit
Convergence in moments of the empirical measure means that the the limit

exists for each fixed  where
where  is the power sum polynomial of degree
is the power sum polynomial of degree 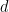 in
in 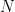 variables.
variables.
Let 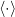 denote expected value, and let
denote expected value, and let

be the characteristic function of  Because the distribution of in is compactly supported,
Because the distribution of in is compactly supported,  is an analytic function on
is an analytic function on  The Maclaurin expansion of the characteristic function is
The Maclaurin expansion of the characteristic function is

where

and the sum is over all vectors  of nonnegative integers whose coordinates sum to Thus,
of nonnegative integers whose coordinates sum to Thus,  is a homogeneous degree polynomial in variables whose coefficients are, up to a transparent factor, the degree joint moments of the random variables . Since
is a homogeneous degree polynomial in variables whose coefficients are, up to a transparent factor, the degree joint moments of the random variables . Since  the logarithm of
the logarithm of  of the characteristic function is defined and analytic on an open neighborhood of the origin in We write the Maclaurin expansion of
of the characteristic function is defined and analytic on an open neighborhood of the origin in We write the Maclaurin expansion of  as
as

where  is a homogeneous degree polynomial in variables. The polynomials
is a homogeneous degree polynomial in variables. The polynomials  are called the cumulant polynomials of the random variables
are called the cumulant polynomials of the random variables  They are determined by the moment polynomials
They are determined by the moment polynomials  according to a certain recursion explained on pages 2 and 3 of these notes. We write the cumulant polynomials in the form
according to a certain recursion explained on pages 2 and 3 of these notes. We write the cumulant polynomials in the form

where the quantities  are the degree joint cumulants of the random variables as
are the degree joint cumulants of the random variables as 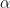 ranges over nonnegative integer vectors of sum . Note that this is a definition, not a proposition. In statistical mechanics and quantum field theory, joint cumulants are referred to as connected correlation functions.
ranges over nonnegative integer vectors of sum . Note that this is a definition, not a proposition. In statistical mechanics and quantum field theory, joint cumulants are referred to as connected correlation functions.
The main fact about Schur-Horn arrays that allows us to understand them is a second formula for the cumulant polynomials of the random variables in terms of the moments of the empirical distribution of the deterministic data
Theorem (Cumulant Formula for Schur-Horn Arrays). For each  we have
we have

where the sums are over nonnegative integer vectors and  with non-increasing coordinates which sum to
with non-increasing coordinates which sum to  and
and  and
and  are the number of nonzero coordinates of and
are the number of nonzero coordinates of and 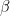 respectively. For each such pair
respectively. For each such pair  the polynomials
the polynomials  and
and  are the corresponding products of power sum symmetric polynomials, i.e.
are the corresponding products of power sum symmetric polynomials, i.e.

Finally,

is a convergent series in which the coefficients  are positive integers called monotone Hurwitz numbers which admit an explicit combinatorial description.
are positive integers called monotone Hurwitz numbers which admit an explicit combinatorial description.
The cumulant formula for Schur-Horn arrays looks complicated, but it is fairly easy to use in practice. For example, let us set our scaling exponent to  Then, we for any fixed
Then, we for any fixed  we have
we have

As we saw (twice) in lecture, you can calculate the limit of this polynomial. Assuming  and
and  the only nonzero limit is
the only nonzero limit is

This means that

unless  is a nonnegative integer vector with total sum
is a nonnegative integer vector with total sum 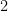 and only one nonzero coordinate. From this we conclude that for any fixed
and only one nonzero coordinate. From this we conclude that for any fixed 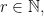 the random variables
the random variables  converge in joint distribution to
converge in joint distribution to  iid standard Gaussians.
iid standard Gaussians.
When our scaling exponent is  we do not get such a simple Gaussian limit. Rather, we find that
we do not get such a simple Gaussian limit. Rather, we find that

for each fixed where

where  Thus we still have a sum of pure powers indicating asymptotic independence between the random variables
Thus we still have a sum of pure powers indicating asymptotic independence between the random variables  but the cumulants of these random variables are asymptotically
but the cumulants of these random variables are asymptotically  We are going to see that
We are going to see that

is the free cumulant sequence corresponding to the moment sequence
