This week we will finish working through the Olshanski-Vershik limit theorem, and explain how the tools we have developed along the way have set us up to prove other kinds of limit theorems about random matrices.
Recall the setting of the OV paper: we have an infinite triangular array of real numbers,

Assume the entries are sorted so that each row is non-increasing from left to right and let

be the 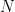 th row. Thinking of
th row. Thinking of  as a diagonal matrix, define a corresponding random Hermitian matrix by
as a diagonal matrix, define a corresponding random Hermitian matrix by

We know that in the characteristic function of 

we can assume without loss in generality that 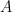 is diagonal, so what we are really looking at is the sequence of characteristic functions
is diagonal, so what we are really looking at is the sequence of characteristic functions

corresponding to our data set  given as
given as

or equivalently
![K_N(a_1,\dots,a_N) = \mathbb{E}\left[e^{i(a_1X_N(1,1)+\dots+a_NX_N(N,N))}\right], \quad A \in \mathbb{R}^N,](https://s0.wp.com/latex.php?latex=K_N%28a_1%2C%5Cdots%2Ca_N%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7Bi%28a_1X_N%281%2C1%29%2B%5Cdots%2Ba_NX_N%28N%2CN%29%29%7D%5Cright%5D%2C+%5Cquad+A+%5Cin+%5Cmathbb%7BR%7D%5EN%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where the diagonal matrix elements  are exchangeable (but not independent) real random variables. Part I of the Olshanski-Vershik theorem is concerned with finding necessary and sufficient conditions on the triangular array such that the characteristic function
are exchangeable (but not independent) real random variables. Part I of the Olshanski-Vershik theorem is concerned with finding necessary and sufficient conditions on the triangular array such that the characteristic function

of a single diagonal  converges as
converges as  Note that extracting the
Note that extracting the  -entry on either side of
-entry on either side of  we have
we have

showing explicitly how is built from the uniformly random unit vector  in
in  and the data
and the data 
The characteristic function  of has the power series expansion
of has the power series expansion

where ![K_N^d=\mathbf{E}[X_N^d(1,1)]](https://s0.wp.com/latex.php?latex=K_N%5Ed%3D%5Cmathbf%7BE%7D%5BX_N%5Ed%281%2C1%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002) are the moments of this real random variable. Olshanski-Vershik being by finding sufficient conditions on the data such that, for each fixed
are the moments of this real random variable. Olshanski-Vershik being by finding sufficient conditions on the data such that, for each fixed  the sequence of numbers
the sequence of numbers  converges to a limit
converges to a limit  as
as 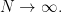 In other words, they begin by finding conditions on the data such that the random variable converges in moments. We will do the same thing, but in a different way, using the following consequence of Theorem 10.1 in Lecture 10.
In other words, they begin by finding conditions on the data such that the random variable converges in moments. We will do the same thing, but in a different way, using the following consequence of Theorem 10.1 in Lecture 10.
Theorem 12.1 (Leading Moments Formula). For each  we have
we have

where the inner sum is absolutely convergent and  is the number of
is the number of  -step monotone walks on the symmetric group of degree
-step monotone walks on the symmetric group of degree 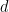 which begin at a permutation of cycle type
which begin at a permutation of cycle type 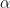 and end at a permutation of cycle type
and end at a permutation of cycle type 
The most efficient way to use this result is to take a logarithm, i.e. to work with the cumulants of . This is also the path followed by Olshanski-Vershik, but the method they use to do the calculation is different.
Let

be the log-characteristic function of  i.e. the cumulant generating function. The cumulant sequence
i.e. the cumulant generating function. The cumulant sequence  contains the same information as the moment sequence
contains the same information as the moment sequence  via the moment-cumulant relations
via the moment-cumulant relations




The cumulants  encode the “connected” version of the combinatorial problem encoded by the moments
encode the “connected” version of the combinatorial problem encoded by the moments 
Theorem 12.2 (Leading Cumulants Formula). For each we have

where  is the number of walks counted by which have the additional feature that their steps and endpoints generate a transitive subgroup of the symmetric group.
is the number of walks counted by which have the additional feature that their steps and endpoints generate a transitive subgroup of the symmetric group.
The Leading Cumulants Formula is identical to the Leading Moments formula except that the walk count has been replaced with the connected walk count . This seemingly minor change is in fact very advantageous.
Theorem 12.3 (Riemann-Hurwitz Formula). The number is nonzero if and only if there is  such that
such that

Due to the Riemann-Hurwitz formula it is more convenient to parameterize the numbers by the parameter  i.e. to set
i.e. to set

Theorem 12.4 (Optimized Leading Cumulants Formula). For each we have

Now we are in position to prove some interesting limit theorems. We begin by proving one such theorem corresponding to an explicit choice of the dataset (this corresponds to Remark 4.5 in Olshanski-Vershik).
Let  be a positive constant, and suppose our dataset has th row given by
be a positive constant, and suppose our dataset has th row given by

where the number of positive and negative entries is as near to equal as possible – equal if even and differing by 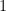 if odd, where we assume the data favors positive numbers in the latter case. In this situation we can establish the following
if odd, where we assume the data favors positive numbers in the latter case. In this situation we can establish the following  limit theorem for a single diagonal matrix element of
limit theorem for a single diagonal matrix element of
Theorem 12.5 (Gaussian Limit Theorem). Any diagonal matrix element of converges in distribution to a centered Gaussian random variable 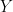 of variance
of variance 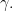
Proof: Let  be a partition of
be a partition of  Then, we have
Then, we have

and therefore

Thus, from the Optimized Leading Cumulants Formula we have

showing that converges to zero for all  This means that converges in cumulants (equivalently, in moments) to a Gaussian random variable
This means that converges in cumulants (equivalently, in moments) to a Gaussian random variable  whose mean and variance remain to be determined.
whose mean and variance remain to be determined.
The first cumulant of is

and this converges to  as For the second cumulant,
as For the second cumulant,

and

Thus, we have shown that converges in moments/cumulants to  In fact, this implies
In fact, this implies  in distribution as
in distribution as  thanks to the Method of Moments.
thanks to the Method of Moments.
-QED