For nonabelian groups 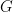 , the convolution algebra
, the convolution algebra  is noncommutative and we cannot hope for a Fourier basis. However, it is reasonable to hope that we can implement a Fourier transform on well-chosen commutative subalgebras of .
is noncommutative and we cannot hope for a Fourier basis. However, it is reasonable to hope that we can implement a Fourier transform on well-chosen commutative subalgebras of .
The first candidate to look at is the center  of . Despite the fact that is by definition a subalgebra of
of . Despite the fact that is by definition a subalgebra of  it is useful to think of the class algebra as a standalone algebra associated to every finite group. The starting point here is the fact that we have an explicit description of which is more workable than its initial definition as the center of
it is useful to think of the class algebra as a standalone algebra associated to every finite group. The starting point here is the fact that we have an explicit description of which is more workable than its initial definition as the center of 
Theorem Z1. The center of the convolution algebra of a finite group consists of functions satisfying  for all
for all  . Equivalently, central functions are those satisfying
. Equivalently, central functions are those satisfying  for all .
for all .
As a consequence of Theorem Z1, indicator functions of conjugacy classes in form a basis of , and this basis is orthogonal relative to the scalar product on in which the group basis is orthonormal. More precisely, let  be a set indexing the conjugacy classes of , and for each
be a set indexing the conjugacy classes of , and for each  let
let  be the corresponding conjugacy class. The indicator function of
be the corresponding conjugacy class. The indicator function of  is then
is then

and because distinct conjugacy classes are disjoint we have

Theorem Z2. The class basis  is an orthogonal basis of .
is an orthogonal basis of .
The problem we pose is to determine whether the class algebra contains a hidden Fourier basis. The answer is yes, though it requires substantial work to see why. Ultimately, we have the following generalization of the Fourier isomorphism on the convolution algebra of a finite abelian group.
Theorem Z3. The class algebra is isomorphic to the function algebra  of a finite set
of a finite set  equicardinal with
equicardinal with 
The proof of Theorem Z3 is based on a higher-dimensional generalization of the multiplicative characters of . A unitary representation of is a pair  consisting of a nonzero Hilbert space
consisting of a nonzero Hilbert space 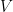 together with a group homomorphism
together with a group homomorphism

where  is the group of unitary elements in the endomorphism algebra
is the group of unitary elements in the endomorphism algebra  . Observe that if
. Observe that if  we can identify
we can identify 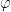 with a group homorphism
with a group homorphism  i.e. with a multiplicative character. To associate a function on to a general unitary representation of , we use the unique (up to scaling) trace on and define the character
i.e. with a multiplicative character. To associate a function on to a general unitary representation of , we use the unique (up to scaling) trace on and define the character

Then, by construction,  and by analogy with the Fourier transform on the convolution algebra we hope that developing the theory of characters will lead to a Fourier basis of the class algebra of an arbitrary finite group, leading to a proof of Theorem Z3. As a first step, we seek conditions under which the characters
and by analogy with the Fourier transform on the convolution algebra we hope that developing the theory of characters will lead to a Fourier basis of the class algebra of an arbitrary finite group, leading to a proof of Theorem Z3. As a first step, we seek conditions under which the characters  and
and  of two unitary representations and
of two unitary representations and  of will be orthogonal in
of will be orthogonal in  i.e. conditions on these unitary representations which will force
i.e. conditions on these unitary representations which will force

This is where the key notion of -equivariant linear transformations enters: we say that a linear transformation  intertwines the unitary representation and if
intertwines the unitary representation and if

The set  of all intertwining transformations is a subspace of
of all intertwining transformations is a subspace of  whose dimension is a key quantity.
whose dimension is a key quantity.
Theorem Z4. We have 
Thus our character orthogonality question becomes the question of when the space of intertwiners between two given unitary representations is zero-dimensional. To understand when this occurs, the key notion is that of a subrepresentation. A subrepresentation of a unitary representation of is a nonzero subspace  such that each of the unitary operators
such that each of the unitary operators  maps
maps  In this case, we may define
In this case, we may define  to be the restriction of to
to be the restriction of to  , giving a unitary representation
, giving a unitary representation  which is said to be a subrepresentation of .
which is said to be a subrepresentation of .
Let us take a moment to note that is a space of linear maps between two possibly different Hilbert spaces, so the Singular Value Decomposition is a naturally associated tool. First of all, associated to any intertwiner  are its kernel
are its kernel  and image
and image  and it is straightforward to check that these are subrepresentations of and
and it is straightforward to check that these are subrepresentations of and  , respectively. The SVD gives us positive numbers
, respectively. The SVD gives us positive numbers  and orthogonal decompositions
and orthogonal decompositions

such that the restriction of  to
to  has the form
has the form  with
with  an isometric isomorphism of Hilbert spaces. It is an important fact that the SVD is fully compatible with representation theory.
an isometric isomorphism of Hilbert spaces. It is an important fact that the SVD is fully compatible with representation theory.
Theorem Z5. If , then the spaces are subrepresentations of , the spaces  are subrepresentations of , and the isometric isomorphisms are -equivariant.
are subrepresentations of , and the isometric isomorphisms are -equivariant.
A unitary representation of is called irreducible if it admits no proper subrepresentation. From the above, we have Schur’s Lemma.
Theorem Z6. A nonzero -equivariant linear map out of an irreducible unitary representation is injective, a nonzero -equivariant linear map into an irreducible unitary representation is surjective, a nonzero -equivariant linear map between irreducible unitary representations is bijective.
A consequence of this, which is often also called Schur’s Lemma, is the following. Note: Theorem Z6 does not require the Fundamental Theorem of Algebra, but Theorem Z7 does.
Theorem Z7. If is an irreducible representation of , then  Moreover, if is a second irreducible unitary representations of which is isomorphic to , then
Moreover, if is a second irreducible unitary representations of which is isomorphic to , then  is one-dimensional.
is one-dimensional.
There is an important consequence of Theorem Z7, which is the third and final result in the trinity of theorems collectively known as “Schur’s Lemma.” To state it, note first that there is a bijection between unitary representations of and linear representations of . Namely, given a unitary representation of there is a corresponding linear representation  of whose action is defined by
of whose action is defined by
Theorem Z8. If  belongs to then the image
belongs to then the image  of
of  in any irreducible linear representation of is a scalar operator.
in any irreducible linear representation of is a scalar operator.
Combining Theorems Z4,Z6, and Z7 we reach the following conclusion: characters of non-isomorphic irreducible unitary representations are orthogonal.
Theorem Z9. If and are irreducible unitary representations of , then  is equal to
is equal to  if they are isomorphic and equal to
if they are isomorphic and equal to  if they are not isomorphic.
if they are not isomorphic.
Let be a set parameterizing isomorphism classes of irreducible unitary representations of  and for each
and for each  let
let  be a representative of the corresponding isomorphism class. Theorem Z8 tells us that
be a representative of the corresponding isomorphism class. Theorem Z8 tells us that  is a linearly independent set in the class algebra . From this it follows that the number of isomorphism classes of irreducible unitary representations of is bounded by the number of conjugacy classes in .
is a linearly independent set in the class algebra . From this it follows that the number of isomorphism classes of irreducible unitary representations of is bounded by the number of conjugacy classes in .
The fact that the orthogonal set spans is deduced by combining isotypic decompositions with the Wedderburn transform on the full convolution algebra First, there is a bijection between unitary representations of and linear representations of . Namely, given a unitary representation of there is a corresponding linear representation of whose action is defined by

Conversely, given a linear representation of we get a unitary representation of given by

Theorem Z10. As a unitary representation of , we have  for every
for every 
Theorem Z10 is a key result. To prove it, one first shows that for any unitary representation of we have

Make sure you know how to do this. Then, one computes the character of the regular representation,

and combines this with the above multiplicity formula. With Theorem Z9 in hand, the next result is easily obtainable. For each  define
define  by
by

where  for any
for any  .
.
Theorem Z11. The orthogonal complement of  in is the zero space. Equivalently,
in is the zero space. Equivalently,  is a basis of .
is a basis of .
The proof of Theorem Z11 uses Theorem Z9 together with the third part of Schur’s Lemma, Theorem Z8.
This completes Phase I of the construction of the Fourier transform on the class algebra of an arbitrary finite group: we have built an orthogonal basis of from characters of irreducible unitary representations of . This mirrors the abelian theory, though it is much more involved. Phase II consists of showing that the character basis of , suitably normalized, is a Fourier basis.









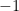
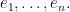






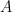








 of the corresponding isomorphism class of irreducible finite-dimensional unitary representations of
of the corresponding isomorphism class of irreducible finite-dimensional unitary representations of 

 isomorphic to the irrep
isomorphic to the irrep  We allow the possibility
We allow the possibility  which means precisely that
which means precisely that  What we are doing here is building the same binary tree of pairs of complementary subspaces that produces the decomposition
What we are doing here is building the same binary tree of pairs of complementary subspaces that produces the decomposition  and then grouping the leaves of the tree corresponding to their isomorphism type
and then grouping the leaves of the tree corresponding to their isomorphism type 
 itself is not. What we can say is that the isotypic decomposition of
itself is not. What we can say is that the isotypic decomposition of 
 with a multiplicity space: we write the isotypic decomposition of
with a multiplicity space: we write the isotypic decomposition of 
 Thanks to Schur’s Lemma, each nonzero linear transformation
Thanks to Schur’s Lemma, each nonzero linear transformation  is an injection of
is an injection of  into
into  as parameterizing all ways in which the irreducible representation
as parameterizing all ways in which the irreducible representation 
 To make this spacial (as opposed to numerical) version of the isotypic decomposition legitimate, we still have to say how each of its components
To make this spacial (as opposed to numerical) version of the isotypic decomposition legitimate, we still have to say how each of its components  is being viewed as a unitary representation of
is being viewed as a unitary representation of  This means that
This means that  To do this, we simply take the Frobenius-Hilbert-Schmidt scalar product on
To do this, we simply take the Frobenius-Hilbert-Schmidt scalar product on  in which
in which 


 for each
for each  is said to be decomposable (or pure) if it can be written as
is said to be decomposable (or pure) if it can be written as  for some
for some  , and indecomposable otherwise. Show that indecomposable tensors exist.
, and indecomposable otherwise. Show that indecomposable tensors exist. For
For  . However, the two are quite different as algebras, and to emphasize this we will write
. However, the two are quite different as algebras, and to emphasize this we will write  for the elementary function corresponding to
for the elementary function corresponding to  rather than
rather than  Then, the convolution product of two elementary functions in
Then, the convolution product of two elementary functions in 
 is the group product. This is not at all the same as the point wise product rule
is the group product. This is not at all the same as the point wise product rule  . Extending the above bilinearly, we get that the convolution of any two functions
. Extending the above bilinearly, we get that the convolution of any two functions


 where
where  is the group identity.
is the group identity.  so that
so that 
 of
of 
 is the unit circle in the complex plane. The set of all multiplicative characters is denoted
is the unit circle in the complex plane. The set of all multiplicative characters is denoted  and called the dual group of
and called the dual group of  first recall that every finite abelian group is isomorphic to a product of cyclic groups, so we may without loss in generality assume that
first recall that every finite abelian group is isomorphic to a product of cyclic groups, so we may without loss in generality assume that
 is a cyclic group of order
is a cyclic group of order  with generator
with generator  Let
Let  so that explicitly
so that explicitly 


 is the principal
is the principal  th root of unity.
th root of unity.



 is an orthogonal set in
is an orthogonal set in  it is a basis of
it is a basis of 
 are a Fourier basis of
are a Fourier basis of 
 is an algebra isomorphism
is an algebra isomorphism  Since
Since  ,
,

 which says that if one is highly concentrated, the other cannot be.
which says that if one is highly concentrated, the other cannot be.
 defined by
defined by
 for the Fourier basis of
for the Fourier basis of  of
of  , and moreover that
, and moreover that
 and the eigenvalues
and the eigenvalues  in terms of the multiplicative characters
in terms of the multiplicative characters  of the underlying groups
of the underlying groups  or the discrete hypercube
or the discrete hypercube 
 is the Hilbert space
is the Hilbert space  containing
containing  as the prototypical commutative algebra and
as the prototypical commutative algebra and  as the prototypical noncommutative algebra.
as the prototypical noncommutative algebra. namely the diagonal subalgebra
namely the diagonal subalgebra  consisting of operators on
consisting of operators on 
 is a scalar. Indeed, the isomorphism
is a scalar. Indeed, the isomorphism 
 is the Fourier transform on
is the Fourier transform on  , namely the basis of elementary operators
, namely the basis of elementary operators 


 a set of pairwise orthogonal projections that spans the diagonal subalgebra
a set of pairwise orthogonal projections that spans the diagonal subalgebra  The Fourier transform
The Fourier transform  is
is 
 for some orthonormal basis
for some orthonormal basis  . Typically, this is posed as a problem about matrices: you are given the matrix of
. Typically, this is posed as a problem about matrices: you are given the matrix of 
 and its Fourier transform
and its Fourier transform  outputs eigenvalues,
outputs eigenvalues,  Our general taxonomy of special elements in an abstract algebra gives you a number of conditions which imply that an operator is normal.
Our general taxonomy of special elements in an abstract algebra gives you a number of conditions which imply that an operator is normal.  is a maximal commutative subalgebra if and only if
is a maximal commutative subalgebra if and only if  for some orthonormal basis
for some orthonormal basis 
 for some orthonormal basis
for some orthonormal basis  of
of 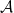 , use the general fact that an algebra is commutative if and only if all its elements are normal, and using Theorem E1 show that there exists an orthonormal basis
, use the general fact that an algebra is commutative if and only if all its elements are normal, and using Theorem E1 show that there exists an orthonormal basis  Since all subalgebras of function algebras are function algebras, Theorem E3 proves that all commutative subalgebras of
Since all subalgebras of function algebras are function algebras, Theorem E3 proves that all commutative subalgebras of  A fundamental result due to Burnside (sometimes called the fundamental theorem of noncommutative algebra) asserts that every subalgebra
A fundamental result due to Burnside (sometimes called the fundamental theorem of noncommutative algebra) asserts that every subalgebra  if and only if
if and only if  is.
is. to
to  A representation of
A representation of 
 and you are not expected to know the classification of subalgebras of
and you are not expected to know the classification of subalgebras of 
 ,$
,$
 Therefore, we simply denote by
Therefore, we simply denote by  the function defined by
the function defined by  of an abstract algebra
of an abstract algebra  In the particular case of the endomorphism algebra
In the particular case of the endomorphism algebra  is called a density operator if it satisfies
is called a density operator if it satisfies  Note that this condition is equivalent to
Note that this condition is equivalent to
 is a probability function in
is a probability function in  is a state on
is a state on 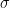 is faithful if and only if
is faithful if and only if 
 so that we can view
so that we can view  .
.  defined by
defined by  ,
,  , is an injective algebra homomorphism.
, is an injective algebra homomorphism. in Theorem E8 is called the Wedderburn transform of
in Theorem E8 is called the Wedderburn transform of  Then, the scalar product on
Then, the scalar product on  This means that the Wedderburn transform
This means that the Wedderburn transform  with respect to this Frobenius scalar product is defined.
with respect to this Frobenius scalar product is defined. and moreover
and moreover  for all
for all  :
: : Endomorphism algebras.
: Endomorphism algebras. : Convolution algebras.
: Convolution algebras. : Class algebras.
: Class algebras. : Polynomial algebras.
: Polynomial algebras. : Gelfand-Tsetlin algebras.
: Gelfand-Tsetlin algebras. with operations defined pointwise. A basic family of functions are the elementary functions,
with operations defined pointwise. A basic family of functions are the elementary functions,
 is a basis of
is a basis of  of nonempty disjoint subsets of
of nonempty disjoint subsets of  of
of  are called its blocks. The set
are called its blocks. The set  of partitions of
of partitions of  if and only if
if and only if  can be obtained from
can be obtained from  is the subalgebra
is the subalgebra  consisting of functions constant on the blocks of
consisting of functions constant on the blocks of  Note that
Note that 
 is the complete collection of subalgebras of
is the complete collection of subalgebras of  if and only if
if and only if 
 is said to separate points if, for every
is said to separate points if, for every  there exists a function
there exists a function 

 of all subsets of
of all subsets of  is the ideal
is the ideal 
 is the complete collection of ideals in
is the complete collection of ideals in  if and only if
if and only if 
 the quotient algebra
the quotient algebra  is isomorphic to the function algebra
is isomorphic to the function algebra 
 is called a probability distribution if
is called a probability distribution if  for all
for all  , and
, and 
 for a unique probability distribution
for a unique probability distribution 

 indexed by some finite set
indexed by some finite set 
 . The mapping
. The mapping 
 is an algebra isomorphism called the Fourier transform. The “the” here is justified by the following.
is an algebra isomorphism called the Fourier transform. The “the” here is justified by the following. exists, then it is unique up to relabeling the label set
exists, then it is unique up to relabeling the label set  denoted
denoted  and an antilinear, antimultiplicative, involution conjugation
and an antilinear, antimultiplicative, involution conjugation  denoted
denoted 
 Two further examples are
Two further examples are  with coordinatewise multiplication and conjugation, and
with coordinatewise multiplication and conjugation, and  with matrix multiplication and Hermitian conjugation. Both coincide with
with matrix multiplication and Hermitian conjugation. Both coincide with 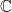 for
for  Thus, we have an example of a commutative algebra of every dimension, and for algebras of square dimension bigger than one we also have a noncommutative example.
Thus, we have an example of a commutative algebra of every dimension, and for algebras of square dimension bigger than one we also have a noncommutative example.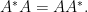 Two subclasses thereof are selfadjoint elements which are equal to their conjugate,
Two subclasses thereof are selfadjoint elements which are equal to their conjugate,  , and unitary elements which satisfy
, and unitary elements which satisfy  Normal elements which are both selfadjoint and unitary are called reflections and they satisfy
Normal elements which are both selfadjoint and unitary are called reflections and they satisfy  Selfadjoint elements which can be factored as
Selfadjoint elements which can be factored as  are called nonnegative, and selfadjoint elements such that
are called nonnegative, and selfadjoint elements such that  are called projections. Two projections which satisfy
are called projections. Two projections which satisfy  are said to be orthogonal.
are said to be orthogonal. with
with 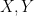 selfadjoint. Furthermore, this decomposition is unique and
selfadjoint. Furthermore, this decomposition is unique and 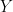 commute.
commute.  has algebras as objects. Morphisms are linear transformations
has algebras as objects. Morphisms are linear transformations  such that
such that
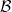 are said to be isomorphic if and only if there exists a bijective homomorphism between them.
are said to be isomorphic if and only if there exists a bijective homomorphism between them.
 the set
the set 
 and is closed under multiplication and conjugation, i.e. it is a subalgebra of
and is closed under multiplication and conjugation, i.e. it is a subalgebra of  The set
The set
 However,
However,  is closed under multiplication and conjugation, and in fact for every
is closed under multiplication and conjugation, and in fact for every  we have
we have  for all
for all  and a unique maximal element of the poset of subalgebras of
and a unique maximal element of the poset of subalgebras of  . There is also a unique minimal subalgebra containing both
. There is also a unique minimal subalgebra containing both  and it is denoted
and it is denoted 

 there is a unique minimal algebra
there is a unique minimal algebra  containing
containing  , namely the intersection of all subalgebras containing it, and this is called the subalgebra generated by
, namely the intersection of all subalgebras containing it, and this is called the subalgebra generated by  where
where 

 if and only if
if and only if  can be viewed as a measure of how (non)commutative
can be viewed as a measure of how (non)commutative  the corresponding centralizer is
the corresponding centralizer is
 then their centralizers are subalgebras such that
then their centralizers are subalgebras such that 
 there may not exist a commutative subalgebra containing it; this occurs for example if
there may not exist a commutative subalgebra containing it; this occurs for example if  consists of a single non-normal element.
consists of a single non-normal element. is contained in a commutative subalgebra of
is contained in a commutative subalgebra of  is commutative.
is commutative. , but there may be many maximal commutative subalgebras
, but there may be many maximal commutative subalgebras  having the property that they are not contained in any strictly larger commutative subalgebra.
having the property that they are not contained in any strictly larger commutative subalgebra. 
 A scalar product so normalized is said to have the left-Frobenius property if
A scalar product so normalized is said to have the left-Frobenius property if

 which has both the left-Frobenius property and the right-Frobenius property is called a Frobenius scalar product.
which has both the left-Frobenius property and the right-Frobenius property is called a Frobenius scalar product. we can define a corresponding Hermitian form on
we can define a corresponding Hermitian form on 
 satisfying
satisfying  and
and  with equality if and only if
with equality if and only if 
 which satisfies
which satisfies 
 is the set of all operators which act diagonally on
is the set of all operators which act diagonally on  if and only if
if and only if  for each
for each  where
where 
 is the orthogonal projection of
is the orthogonal projection of 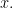 A physicist would write this projection operator as
A physicist would write this projection operator as  and so that in Dirac notation the above decomposition becomes
and so that in Dirac notation the above decomposition becomes
 . This is a particularly transparent instance of the Fourier transform.
. This is a particularly transparent instance of the Fourier transform. 
 does there exist an orthonormal basis
does there exist an orthonormal basis 
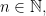 choose an arbitrary parameterization of the isomorphism classes of irreducible unitary representations of
choose an arbitrary parameterization of the isomorphism classes of irreducible unitary representations of 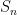 by the set
by the set  of partitions of
of partitions of  and for each
and for each  choose an arbitrary representative
choose an arbitrary representative  called the branching graph of the tower of symmetric groups. The vertex set of
called the branching graph of the tower of symmetric groups. The vertex set of 
 for some
for some  The precise adjacency relation is the following: if
The precise adjacency relation is the following: if  and
and  then
then  is an edge of
is an edge of  it contains an irreducible subspace
it contains an irreducible subspace ![V^\lambda[\mu]](https://s0.wp.com/latex.php?latex=V%5E%5Clambda%5B%5Cmu%5D&bg=FFFFFF&fg=000&s=0&c=20201002) isomorphic as a representation of
isomorphic as a representation of 
 and any
and any ![V^\lambda = \bigoplus\limits_{\gamma \in \mathrm{Geo}(\mathrm{Par}_k,\lambda)} V^\lambda[\gamma],](https://s0.wp.com/latex.php?latex=V%5E%5Clambda+%3D+%5Cbigoplus%5Climits_%7B%5Cgamma+%5Cin+%5Cmathrm%7BGeo%7D%28%5Cmathrm%7BPar%7D_k%2C%5Clambda%29%7D+V%5E%5Clambda%5B%5Cgamma%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 is the set of geodesics in
is the set of geodesics in  to the specified point
to the specified point ![V^\lambda[\gamma]](https://s0.wp.com/latex.php?latex=V%5E%5Clambda%5B%5Cgamma%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is a nonzero subspace of
is a nonzero subspace of  acts irreducibly. Note that while all of these subspaces
acts irreducibly. Note that while all of these subspaces  the number of spaces in the above decomposition isomorphic to
the number of spaces in the above decomposition isomorphic to  is
is 
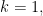 where
where ![V^\lambda=\bigoplus\limits_{\gamma \in \mathrm{Geo}(1,\lambda)} V^\lambda[\gamma]](https://s0.wp.com/latex.php?latex=V%5E%5Clambda%3D%5Cbigoplus%5Climits_%7B%5Cgamma+%5Cin+%5Cmathrm%7BGeo%7D%281%2C%5Clambda%29%7D+V%5E%5Clambda%5B%5Cgamma%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
 If we choose a unit vector
If we choose a unit vector  from each Gelfand-Tsetlin line
from each Gelfand-Tsetlin line ![V^\lambda[\gamma],](https://s0.wp.com/latex.php?latex=V%5E%5Clambda%5B%5Cgamma%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) we obtain an orthonormal basis of
we obtain an orthonormal basis of  “the” Gelfand-Tsetlin basis of
“the” Gelfand-Tsetlin basis of  which really means that the basis is uniquely defined up to the phase ambiguity. In any case, this gives our first handle on the dimensions of the irreducible representations of the symmetric groups: we now know that
which really means that the basis is uniquely defined up to the phase ambiguity. In any case, this gives our first handle on the dimensions of the irreducible representations of the symmetric groups: we now know that 
 and every
and every  let
let  be the subalgebra of
be the subalgebra of  consisting of all elements
consisting of all elements  belongs to the diagonal subalgebra
belongs to the diagonal subalgebra  of the GT-basis
of the GT-basis  In other words, the image
In other words, the image
 under the Wedderburn isomorphism
under the Wedderburn isomorphism
 -basis in every irreducible representations, the
-basis in every irreducible representations, the 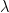 -block of
-block of 
 of every irreducible representation
of every irreducible representation 
 of
of 
 is the center of
is the center of  We had to put in some significant work to show that
We had to put in some significant work to show that ![\mathcal{J}_n = \mathbb{C}[|J_1\rangle,\dots,|J_n\rangle]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BJ%7D_n+%3D+%5Cmathbb%7BC%7D%5B%7CJ_1%5Crangle%2C%5Cdots%2C%7CJ_n%5Crangle%5D&bg=FFFFFF&fg=000&s=0&c=20201002) , which is shorthand for saying that the Jucys-Murphy specialization of the polynomial algebra
, which is shorthand for saying that the Jucys-Murphy specialization of the polynomial algebra ![\mathcal{P}_n=\mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D_n%3D%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is a surjection onto
is a surjection onto  This effort front loading is now starting to pay off.
This effort front loading is now starting to pay off. 
 For this we use the fact, since we have already shown
For this we use the fact, since we have already shown ![\mathcal{J}_n=\mathbb{C}[|J_1\rangle,\dots,|J_n\rangle],](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BJ%7D_n%3D%5Cmathbb%7BC%7D%5B%7CJ_1%5Crangle%2C%5Cdots%2C%7CJ_n%5Crangle%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) it is sufficient to show that each JM-element
it is sufficient to show that each JM-element  belongs to the
belongs to the  this reduces to showing that the sum
this reduces to showing that the sum  of all transpositions in
of all transpositions in  To demonstrate this, fix
To demonstrate this, fix  and let
and let![V^\lambda = \bigoplus\limits_{\gamma \in \mathrm{Geo}(\mathrm{Par}_k,\lambda)} V^\lambda[\gamma]](https://s0.wp.com/latex.php?latex=V%5E%5Clambda+%3D+%5Cbigoplus%5Climits_%7B%5Cgamma+%5Cin+%5Cmathrm%7BGeo%7D%28%5Cmathrm%7BPar%7D_k%2C%5Clambda%29%7D+V%5E%5Clambda%5B%5Cgamma%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
 belongs to one of the spaces
belongs to one of the spaces  acts as a scalar operator in each of these spaces by Schur’s Lemma.
acts as a scalar operator in each of these spaces by Schur’s Lemma. using finite-dimensional Stone-Weierstrass and the fact that
using finite-dimensional Stone-Weierstrass and the fact that  is isomorphic to the function algebra
is isomorphic to the function algebra  , where
, where  is the set of all geodesics from
is the set of all geodesics from  to
to  of
of  and in order to invoke Stone-Weirstrass to prove that
and in order to invoke Stone-Weirstrass to prove that  we just have to show that
we just have to show that  are distinct geodesics
are distinct geodesics  in
in  then there necessarily exists
then there necessarily exists  such that
such that  passes through
passes through  passes through
passes through  and
and  In particular,
In particular,  are non-isomorphic irreducible representations of
are non-isomorphic irreducible representations of  acts as a scalar operator in each of these irreducible representations: the eigenvalue of
acts as a scalar operator in each of these irreducible representations: the eigenvalue of  acting in
acting in 

 for all
for all  this would force
this would force
