Let  be a sequence of deterministic Hermitian matrices, and let
be a sequence of deterministic Hermitian matrices, and let  be any enumeration of the eigenvalues of
be any enumeration of the eigenvalues of  Consider the corresponding sequence
Consider the corresponding sequence  of random Hermitian matrices defined by
of random Hermitian matrices defined by  where
where  is a random unitary matrix whose distribution in
is a random unitary matrix whose distribution in  is Haar measure. We then have a corresponding triangular array of real random variables,
is Haar measure. We then have a corresponding triangular array of real random variables,

whose 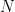 th row
th row

consists of the diagonal elements of the random matrix  In terms of our input data
In terms of our input data  we have
we have

This is superficially similar to the setup for the Central Limit Theorem, but it is different:  are exchangeable but not independent (make sure you understand why). Thus our first objective is simply to understand the
are exchangeable but not independent (make sure you understand why). Thus our first objective is simply to understand the  asymptotic distribution of
asymptotic distribution of  the
the  -matrix element of a uniformly random Hermitian matrix with spectrum
-matrix element of a uniformly random Hermitian matrix with spectrum 
In this lecture I will use the angled brackets notation favored by physicists to denote expectation. I will also use the angled bracket with a subscript “ ” for cumulants (the subscript could also stand for connected). So for example the variance of
” for cumulants (the subscript could also stand for connected). So for example the variance of  is
is

Problem 13.1. Prove that  Also show that for
Also show that for  we have
we have  for any constant
for any constant  (this translation invariance is a general property of cumulants).
(this translation invariance is a general property of cumulants).
Our Optimized Leading Cumulants Formula says that for any  we have
we have

where

and

is  times a convergent positive series.
times a convergent positive series.
What is nice about the Optimized Leading Cumulants Formula is that it almost immediately suggests the possibility of Gaussian limiting behavior: because of the factor  in the formula, it looks like cumulants of degree
in the formula, it looks like cumulants of degree 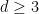 should vanish in the limit, which is the Gaussian signature. To actually establish this we need to determine how the rest of the formula behaves as grows large.
should vanish in the limit, which is the Gaussian signature. To actually establish this we need to determine how the rest of the formula behaves as grows large.
This is not so difficult. We have the finite sum

and the number of terms in the sum has no dependence on . The quantity  is
is 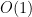 as (make sure you understand why). This leaves the fraction
as (make sure you understand why). This leaves the fraction

The denominator is literally just a power of . As for the numerator, we have the bound

where  is the spectral radius of Thus, we have
is the spectral radius of Thus, we have

We therefore have the cumulant bound

where  depends only on
depends only on 
Theorem 13.1. If the input sequence  of Hermitian matrices is such that
of Hermitian matrices is such that  for some constant
for some constant  and all
and all 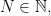 and if
and if  exists, then the centered random variable
exists, then the centered random variable  converges to a centered Gaussian of variance
converges to a centered Gaussian of variance 
Proof: By definition the first cumulant of  is zero for every and from translation invariance of cumulants and the bound established above we have that all cumulants of degree
is zero for every and from translation invariance of cumulants and the bound established above we have that all cumulants of degree  converge to zero. From the Optimized Leading Cumulants formula and the estimates above, the only term in the second cumulant is exactly
converge to zero. From the Optimized Leading Cumulants formula and the estimates above, the only term in the second cumulant is exactly  Therefore, converges to a centered Gaussian random variable
Therefore, converges to a centered Gaussian random variable 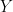 of variance
of variance  as
as 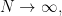 and the convergence holds in distribution by the Moment Method.
and the convergence holds in distribution by the Moment Method.
-QED
Published by Jonathan Novak
Mathematician at UC San Diego.
View all posts by Jonathan Novak