Today we want to prove the “inverse Wigner theorem” we started discussing last time. Let  be a sequence of traceless deterministic matrices, and for each
be a sequence of traceless deterministic matrices, and for each  let
let  be a uniformly random Hermitian matrix isospectral with
be a uniformly random Hermitian matrix isospectral with  Suppose that the empirical eigenvalue distribution of
Suppose that the empirical eigenvalue distribution of  converges in moments as
converges in moments as 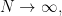 meaning that the limit
meaning that the limit

exists for each  Equivalently, we have
Equivalently, we have

with  any enumeration of the eigenvalues of
any enumeration of the eigenvalues of  and
and  the power sum polynomial of degree
the power sum polynomial of degree  Let
Let  denote the diagonal matrix elements of the random matrix
denote the diagonal matrix elements of the random matrix  so
so

with  a uniformly random unitary matrix.
a uniformly random unitary matrix.
Theorem 15.1. For any fixed 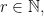 the random vector
the random vector  converges in moments to a vector
converges in moments to a vector  of iid centered Gaussians of variance
of iid centered Gaussians of variance  More precisely, we have
More precisely, we have

for any vector  of nonnegative integers.
of nonnegative integers.
Here is a corollary which further explains why we are calling Theorem 15.1 an inverse Wigner theorem.
Corollary 15.1. For any the  principal submatrix of
principal submatrix of  converges to
converges to  i.e. to an random Hermitian matrix following a centered Gaussian distribution of variance
i.e. to an random Hermitian matrix following a centered Gaussian distribution of variance
Problem 15.1. Deduce Corollary 15.1 from Theorem 15.1.
The rest of the lecture consists of the proof of Theorem 15.1. First, let us explain the assumption that our deterministic data has trace zero. The random variables are identically distributed (but not independent), with first moment

So, assuming  is equivalent to centering
is equivalent to centering 
Now we start the proof. The joint distribution of is a compactly supported probability measure on  — indeed, it is supported on the compact convex set whose extreme points are the distinct permutations of the deterministic vector
— indeed, it is supported on the compact convex set whose extreme points are the distinct permutations of the deterministic vector  Therefore, the Laplace transform
Therefore, the Laplace transform

is an entire function of the complex variables  i.e.
i.e.  is an analytic function on
is an analytic function on  Note that if we set
Note that if we set  and restricting the remaining variables
and restricting the remaining variables  , the Laplace transform specializes to the characteristic function of
, the Laplace transform specializes to the characteristic function of  so that it completely determines the distribution of this random vector. The variable
so that it completely determines the distribution of this random vector. The variable  is redundant, but it is a convenient marker of homogeneity: we write the Maclaurin expansion of as
is redundant, but it is a convenient marker of homogeneity: we write the Maclaurin expansion of as

where  is a homogeneous polynomial of degree
is a homogeneous polynomial of degree 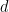 . Indeed, this polynomial is
. Indeed, this polynomial is

which in the standard monomial basis of homogeneous polynomials is

the sum being over all vectors  of nonnegative integers whose coordinates sum to , aka weak
of nonnegative integers whose coordinates sum to , aka weak 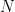 -part compositions of We call
-part compositions of We call  the degree moment polynomial of
the degree moment polynomial of  because its coefficients in the monomial basis are the degree joint moments of these random variables (up to a multinomial coefficient). So our objective is to understand the
because its coefficients in the monomial basis are the degree joint moments of these random variables (up to a multinomial coefficient). So our objective is to understand the  behavior of this polynomial restricted to the
behavior of this polynomial restricted to the  -dimensional subspace of
-dimensional subspace of  spanned by the first coordinate vectors, where
spanned by the first coordinate vectors, where  is arbitrary but fixed. To be completely explicit, this is the polynomial
is arbitrary but fixed. To be completely explicit, this is the polynomial

the sum being over weak -part compositions of 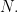 This is an important simplification, since the number of variables of
This is an important simplification, since the number of variables of  is fixed, i.e. its domain does not vary with
is fixed, i.e. its domain does not vary with
In fact, it is more convenient to work with the log-Laplace transform of More precisely, since  there exists a simply connected open neighborhood
there exists a simply connected open neighborhood  of the origin in
of the origin in  on which is non vanishing, and there is a unique analytic function
on which is non vanishing, and there is a unique analytic function  vanishing at the origin which satisfies
vanishing at the origin which satisfies

Let

be the Maclaurin expansion of this analytic function, so  is a homogeneous degree polynomial. This is called the degree cumulant polynomial of the random variables . According to the Exponential Formula (aka moment-cumulant formula), these cumulants are recursively determined by the moment polynomials by a triangular system of equations, the first three of which are (suppressing the variables
is a homogeneous degree polynomial. This is called the degree cumulant polynomial of the random variables . According to the Exponential Formula (aka moment-cumulant formula), these cumulants are recursively determined by the moment polynomials by a triangular system of equations, the first three of which are (suppressing the variables  )
)

We can write the polynomial  as
as

except for the subscript on the expectation-like quantity $\langle X_{N1}^{\alpha_1} \dots X_{NN}^{\alpha_N}\rangle_c$, which is known as a degree joint cumulant of Note that this is a definition, not a proposition – the relationship between the Maclaurin expansion of the Laplace transform and the log-Laplace transform implicitly defines these statistics.
Problem 15.2. Show that  is the covariance of
is the covariance of  and
and 
Our discussion so far pertains to any finite family of random variables with compactly supported joint distribution. Now we will start invoking special features of the family we are actually dealing with. The first of these is that these random variables are exchangeable, which is equivalent to saying that the cumulant polynomials are symmetric polynomials. This means that we can also expand them as linear combinations of Newton polynomials, and as previously discussed have a powerful understanding of this expansion.
Theorem 15.2 (Leading Cumulants Formula). For any  we have
we have

where each sum is over the set of integer partitions of and

is a convergent power series in  whose coefficients
whose coefficients  are positive integers.
are positive integers.
The combinatorial coefficients are quite intricate and there is no simple closed formula for them (you can read this if you want to know more), but luckily we do not need to know very much about them in order to prove our inverse Wigner theorem. All that matters for us is that this magic formula is expressing the cumulant polynomials of in terms of the moments of the empirical eigenvalue distribution of our deterministic data matrices in a quite transparent way.
To leverage this, let us restrict to the cumulant polynomials of  , which just means setting the last
, which just means setting the last  variables of equal to zero (this eventually makes sense because is fixed and increases without bound). We write the resulting polynomial in the form
variables of equal to zero (this eventually makes sense because is fixed and increases without bound). We write the resulting polynomial in the form

Ignore the factor of  for a moment and just think about the behavior of the double sum as . The number of terms in this sum is independent of , which means that we only need to understand the asymptotics of each individual term
for a moment and just think about the behavior of the double sum as . The number of terms in this sum is independent of , which means that we only need to understand the asymptotics of each individual term

Reading from right to left, we have that  as
as 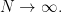 By hypothesis, we have
By hypothesis, we have

Finally, since

we have

as Thus, the whole double sum is 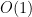 as so now is a good time to remember the prefactor and immediately conclude that
as so now is a good time to remember the prefactor and immediately conclude that

as , uniformly on compact subsets of  for all
for all 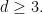 For
For  we have
we have

uniformly on compact subsets of and since  and
and  this simplifies to
this simplifies to

Finally, the polynomial  is identically zero by our trace zero hypothesis. What we have shown is that all joint cumulants of
is identically zero by our trace zero hypothesis. What we have shown is that all joint cumulants of  converge to zero as except for pure cumulants of degree two,
converge to zero as except for pure cumulants of degree two,

each of which converges to
Problem 15.3. Compute the joint cumulants of a finite family of centered iid Gaussians and complete the proof.