This week we are looking at a landmark paper by Grigori Olshanski and Anatoly Vershik, “Ergodic Unitarily Invariant Measures on the Space of Infinite Hermitian Matrices.” This paper is among the first to consider characteristic functions in the context of random matrix theory. Namely, it considers the problem of approximating the function

defined by

where the integration is over the unitary group of rank 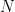 against Haar measure. We have referred to this function as the “quantum Fourier kernel,” but as we have stressed it is also the classical characteristic function of the diagonal
against Haar measure. We have referred to this function as the “quantum Fourier kernel,” but as we have stressed it is also the classical characteristic function of the diagonal  of
of  of a uniformly random Hermitian matrix with deterministic eigenvalues
of a uniformly random Hermitian matrix with deterministic eigenvalues  The paper of Olshanski-Vershik is about approximating
The paper of Olshanski-Vershik is about approximating  as
as 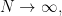 which probabilistically means that we are trying to understand how the joint distribution of the diagonal matrix elements of a very large uniformly random Hermitian matrix with prescribed eigenvalues
which probabilistically means that we are trying to understand how the joint distribution of the diagonal matrix elements of a very large uniformly random Hermitian matrix with prescribed eigenvalues  is determined by the vector
is determined by the vector  This is an example of a high-dimensional problem: we are trying to approximate a function: our goal is to approximate a function
This is an example of a high-dimensional problem: we are trying to approximate a function: our goal is to approximate a function

of  real variables as the number of variables goes to infinity. Typically such problems are much harder than traditional problems of asymptotic analysis, which consider the approximation of some parameter-dependent family of functions defined on a fixed domain as the parameter approaches a given value.
real variables as the number of variables goes to infinity. Typically such problems are much harder than traditional problems of asymptotic analysis, which consider the approximation of some parameter-dependent family of functions defined on a fixed domain as the parameter approaches a given value.
One way to simplify the question is to consider the restriction of  to the subspace
to the subspace  with
with  fixed. That is, we consider the characteristic function
fixed. That is, we consider the characteristic function
![K_N(a_1,\dots,a_r,0,\dots,0;b_1,\dots,b_N) = \mathbb{E}\left[e^{i(a_1X_N(1,1) + \dots +a_r X_N(r,r))}\right]](https://s0.wp.com/latex.php?latex=K_N%28a_1%2C%5Cdots%2Ca_r%2C0%2C%5Cdots%2C0%3Bb_1%2C%5Cdots%2Cb_N%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7Bi%28a_1X_N%281%2C1%29+%2B+%5Cdots+%2Ba_r+X_N%28r%2Cr%29%29%7D%5Cright%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
of only the first  diagonal matrix elements of the random Hermitian matrix
diagonal matrix elements of the random Hermitian matrix  Recall that we have previously shown that all diagonal matrix elements of
Recall that we have previously shown that all diagonal matrix elements of  are identically distributed, but not necessarily independent. The paper of Olshanski and Vershik shows that if the eigenvalues
are identically distributed, but not necessarily independent. The paper of Olshanski and Vershik shows that if the eigenvalues  , scaled by a factor of
, scaled by a factor of  converge to a point configuration on
converge to a point configuration on  as then the random variables
as then the random variables  converge to independent random variables whose characteristic function can be calculated explicitly in terms of this point configuration. We will try to work through this result, which I believe to be the first high-dimensional limit theorem in RMT obtained via characteristic functions.
converge to independent random variables whose characteristic function can be calculated explicitly in terms of this point configuration. We will try to work through this result, which I believe to be the first high-dimensional limit theorem in RMT obtained via characteristic functions.
The Olshanski-Vershik approach of computing the asymptotics of the characteristic function

is based on series expansion of this matrix integral. I am a big proponent of this approach, but it does require some quite extensive background from representation theory and algebraic combinatorics which is not traditionally found in the realm of probability. We will try not to get too bogged down in the algebra, and in order to do this it will be necessary to accept some results from representation theory as black boxes.
First, let us analytically continue the characteristic function  to a function
to a function

by declaring

where 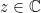 is a complex number and
is a complex number and  are complex vectors. Thus, by compactness of
are complex vectors. Thus, by compactness of  , we have that is an entire function of
, we have that is an entire function of  complex variables
complex variables  and the Maclaurin series of this function, which is a multivariate Taylor series centered at the origin, converges uniformly absolutely on compact subsets of
and the Maclaurin series of this function, which is a multivariate Taylor series centered at the origin, converges uniformly absolutely on compact subsets of  We recover our original characteristic function by setting
We recover our original characteristic function by setting  and restricting
and restricting  to
to  .
.
The analytic function has various symmetries that allow us to present its Maclaurin series in a more advantageous form. More precisely,  is invariant under independent permutations of
is invariant under independent permutations of  and
and  , and also stable under swapping these two sets of variables. This means that the Macluarin series of can be presented in the form
, and also stable under swapping these two sets of variables. This means that the Macluarin series of can be presented in the form

where  is a homogeneous degree
is a homogeneous degree 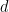 symmetric polynomial in and also a homogeneous degree symmetric polynomial in . Therefore, by Newton’s theorem on symmetric polynomials, we can write this partial derivative as
symmetric polynomial in and also a homogeneous degree symmetric polynomial in . Therefore, by Newton’s theorem on symmetric polynomials, we can write this partial derivative as

where  is the set of integer partitions of the degree
is the set of integer partitions of the degree  which we identify with the set of Young diagrams with cells, and
which we identify with the set of Young diagrams with cells, and  and
and  are the Newton power-sum symmetric polynomials corresponding to
are the Newton power-sum symmetric polynomials corresponding to  For example, if
For example, if  and
and 
 then
then

Our objective then is to calculate the numerical coefficients  of the polynomial
of the polynomial  which we will refer to as its Newton coefficients.
which we will refer to as its Newton coefficients.
Problem 9.1. Show that  and use this to show that
and use this to show that 
What is good about the Newton polynomials is that they connect us to point configurations, which is what we want. More precisely, if  is a real vector, then we can view it not as a point in -dimensional space but as a configuration of particles on the real line. The empirical distribution
is a real vector, then we can view it not as a point in -dimensional space but as a configuration of particles on the real line. The empirical distribution  of is the discrete measure on which places unit mass at each particle, and the degree moment of this measure is
of is the discrete measure on which places unit mass at each particle, and the degree moment of this measure is

This means that writing the Maclaurin expansion of $K_N(z,A,B)$ in terms of Newton symmetric polynomials is exactly what we want to do, because it is expressing this function in terms of the empirical distributions of its arguments , and the empirical distribution of a point configuration is a natural way to describe the “shape” of the configuration in the infinite particle limit where 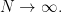
Unfortunately, there is no obvious way to calculate the Newton coefficients  What we can do is compute the Maclaurin series of
What we can do is compute the Maclaurin series of  by repeatedly differentiating under the integral sign with respect to
by repeatedly differentiating under the integral sign with respect to  . Equivalently, we just expand the exponential function of in the inetegrand and then integrate term-by-term, which gives
. Equivalently, we just expand the exponential function of in the inetegrand and then integrate term-by-term, which gives

This gives us the formula

which at least reduces our initial problem of computing an exponential integral over to computing a polynomial integral over 

but still there is no obvious path forward.
At this point we should ask ourselves what integrals over we actually can compute. To make the discussion as simple as possible, take  so
so  is just the unit circle in
is just the unit circle in  One thing we can confidently state is the orthogonality relation
One thing we can confidently state is the orthogonality relation

Representation theory gives us analogous formulas for all  namely a system of multivariate polynomials which are orthogonal polynomials for integration with respect to Haar measure on
namely a system of multivariate polynomials which are orthogonal polynomials for integration with respect to Haar measure on  Let
Let  be the set of all Young diagrams with at most rows.
be the set of all Young diagrams with at most rows.
Defintion 9.1. For each  the corresponding Schur symmetric polynomial is defined by
the corresponding Schur symmetric polynomial is defined by
![s_\lambda(t_1,\dots,t_N) = \frac{\det [t_j^{N-i+\lambda_i}]}{\det[t_j^{N-i}]},](https://s0.wp.com/latex.php?latex=s_%5Clambda%28t_1%2C%5Cdots%2Ct_N%29+%3D+%5Cfrac%7B%5Cdet+%5Bt_j%5E%7BN-i%2B%5Clambda_i%7D%5D%7D%7B%5Cdet%5Bt_j%5E%7BN-i%7D%5D%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where  are the row lengths of
are the row lengths of 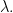
Out of the many equivalent definitions of Schur polynomials, we are taking this one because it is a fairly explicit and elementary formula. Indeed, the determinant in the denominator is the Vandermonde determinant, which has the property that it divides any other antisymmetric polynomial in  to yield a symmetric polynomial.
to yield a symmetric polynomial.
Problem 9.2. Let  be the single-cell Young diagram. Compute the Schur polynomial
be the single-cell Young diagram. Compute the Schur polynomial  directly from Definition 9.1. Do the same for a few more small Young diagrams.
directly from Definition 9.1. Do the same for a few more small Young diagrams.
The disadvantage of Definition 9.1 is that it makes the orthogonality relations for Schur polynomials, which are really consequences of the fact that these polynomials are characters of irreducible representations of into a theorem whose proof would take us to far afield. So we will have to treat this property as a black box. Given a matrix  let us write
let us write  for the evaluation
for the evaluation  of the Schur polynomial
of the Schur polynomial  on the eigenvalues of
on the eigenvalues of 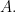
Theorem 9.1 (Schur orthogonality). For any two Young diagrams  and any two matrices
and any two matrices  we have
we have

and

where  is the number of semi standard Young tableaux of shape
is the number of semi standard Young tableaux of shape 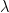 with entries from
with entries from 
We also need a remarkable “multinomial formula” due to Frobenius. Let  be the set of Young diagrams with exactly cells and at most rows.
be the set of Young diagrams with exactly cells and at most rows.
Theorem 9.2 (Frobenius formula). We have

where  is the number of standard Young tableaux of shape
is the number of standard Young tableaux of shape
The reason the tableaux counts  and
and  are denoted this way is that the former is the dimension of an irreducible representation of the symmetric group
are denoted this way is that the former is the dimension of an irreducible representation of the symmetric group  and the latter is the dimension of an irreducible representation of the unitary group At this point we have enough material to explicitly calculate a series expansion of
and the latter is the dimension of an irreducible representation of the unitary group At this point we have enough material to explicitly calculate a series expansion of  . This expansion is the starting point of Olshanski and Vershik’s asymptotic analysis, and is stated as Theorem 5.1 in their paper.
. This expansion is the starting point of Olshanski and Vershik’s asymptotic analysis, and is stated as Theorem 5.1 in their paper.
Theorem 9.3 (Schur expansion of ). We have

Proof: From the Theorem 9.2, we have

and applying the first integration formula in Theorem 9.1 this becomes

– QED
Problem 9.3. Compute the Schur expansion of up to  This is straightforward but will give you a feel for the structure of the formula.
This is straightforward but will give you a feel for the structure of the formula.
Let us include the analogue of Theorem 9.3 for the quantum Bessel kernel

where  and the integration is against Haar measure on the product group
and the integration is against Haar measure on the product group  Here
Here  are real vectors viewed as diagonal matrices in
are real vectors viewed as diagonal matrices in  Since
Since  is invariant under signed permutations of the coordinates of
is invariant under signed permutations of the coordinates of  and , we can assume without loss in generality that these are non increasing lists of nonnegative numbers. The quantum Bessel kernel is the characteristic function of a uniformly random
and , we can assume without loss in generality that these are non increasing lists of nonnegative numbers. The quantum Bessel kernel is the characteristic function of a uniformly random  rectangular matrix with singular values
rectangular matrix with singular values  Once again we can analytically continue this to
Once again we can analytically continue this to

where and are viewed as complex diagonal matrices in the integral. The following expansion of  is not in the Olshanski-Vershik paper, but it can be obtained in essentially the same way; a more general result is proved here.
is not in the Olshanski-Vershik paper, but it can be obtained in essentially the same way; a more general result is proved here.
Theorem 9.4 (Schur expansion of ). We have

We close this lecture with a pointer to interesting work in the engineering literature which considers exactly these integrals in an applied context.
 be a random rectangular matrix, i.e. a random variable taking values in
be a random rectangular matrix, i.e. a random variable taking values in  viewed as a real vector space with scalar product
viewed as a real vector space with scalar product 
 -dimensional Euclidean space
-dimensional Euclidean space  defined by the expectation
defined by the expectation![\varphi_{X_{MN}}(T) = \mathbb{E}\left[e^{i \langle T,X_{MN}\rangle}\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX_%7BMN%7D%7D%28T%29+%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7Bi+%5Clangle+T%2CX_%7BMN%7D%5Crangle%7D%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)

 of
of 
 acts on
acts on  from
from  into the orthogonal group of the Euclidean space
into the orthogonal group of the Euclidean space 
 so that the product
so that the product  is an
is an  square matrix which fits inside an
square matrix which fits inside an  contains an
contains an  whose entries satisfy
whose entries satisfy



 , where
, where  is a uniformly random sample from
is a uniformly random sample from  and
and  is an
is an 
![K_{MN}(A,B) = \mathbf{E}[e^{i\langle A,U_MBV_N^*\rangle}]=\int\limits_{\mathbb{U}_{MN}} e^{\frac{i}{2}\mathrm{Tr}\,(A^*UBV^*+VB^*U^*A)} \mathrm{d}(U,V),](https://s0.wp.com/latex.php?latex=K_%7BMN%7D%28A%2CB%29+%3D+%5Cmathbf%7BE%7D%5Be%5E%7Bi%5Clangle+A%2CU_MBV_N%5E%2A%5Crangle%7D%5D%3D%5Cint%5Climits_%7B%5Cmathbb%7BU%7D_%7BMN%7D%7D+e%5E%7B%5Cfrac%7Bi%7D%7B2%7D%5Cmathrm%7BTr%7D%5C%2C%28A%5E%2AUBV%5E%2A%2BVB%5E%2AU%5E%2AA%29%7D+%5Cmathrm%7Bd%7D%28U%2CV%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 the kernels
the kernels  and
and  The quantum Fourier kernel reverts to the classical Fourier kernel on the line,
The quantum Fourier kernel reverts to the classical Fourier kernel on the line,
 is something else, namely
is something else, namely  \
\ the power series expansion of which is
the power series expansion of which is
 which defines the
which defines the 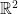 with radially symmetric distribution.
with radially symmetric distribution.  and any integer
and any integer  the
the  th quantum Hankel transform of
th quantum Hankel transform of 


 we can define the characteristic function of a random variable
we can define the characteristic function of a random variable 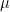 by
by
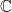 which uniquely determines the measure
which uniquely determines the measure  To get some feel for which this might be, expand the Fourier kernel in a power series,
To get some feel for which this might be, expand the Fourier kernel in a power series, 
![\mathbf{E}F(a,X) = 1 + \sum_{d=1}^\infty \frac{i^d}{d!} a^d\mathbf{E}[X^d],](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7DF%28a%2CX%29+%3D+1+%2B+%5Csum_%7Bd%3D1%7D%5E%5Cinfty+%5Cfrac%7Bi%5Ed%7D%7Bd%21%7D+a%5Ed%5Cmathbf%7BE%7D%5BX%5Ed%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![\mathbf{E}[X^d] = \int\limits_{\mathbb{R}} x^d \mu(\mathrm{d}x)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5BX%5Ed%5D+%3D+%5Cint%5Climits_%7B%5Cmathbb%7BR%7D%7D+x%5Ed+%5Cmu%28%5Cmathrm%7Bd%7Dx%29&bg=FFFFFF&fg=000&s=0&c=20201002) ,
, or equivalently of
or equivalently of 

 defined by
defined by 
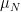 is the distribution of
is the distribution of  It is still true that
It is still true that  exists and uniquely determines
exists and uniquely determines  and
and
 we have
we have 
 is a homogeneous polynomial of degree
is a homogeneous polynomial of degree  which is invariant under independent permutations of these variables. Therefore, we have
which is invariant under independent permutations of these variables. Therefore, we have
 is the set of weak
is the set of weak 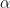 of
of 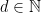 and
and  is a numerical coefficient. It is easy to determine this coefficient explicitly: since
is a numerical coefficient. It is easy to determine this coefficient explicitly: since

 is a generating polynomial for degree
is a generating polynomial for degree  ,
, ![\mathbf{E}F_N^d(A,X_N) = \sum\limits_{\alpha \in \mathsf{C}_N^d} a_1^{\alpha_1} \dots a_N^{\alpha_N} \mathbf{E}[X^{\alpha_1}_N(1)\dots X^{\alpha_N}_N(N)]F_N(\alpha).](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7DF_N%5Ed%28A%2CX_N%29+%3D+%5Csum%5Climits_%7B%5Calpha+%5Cin+%5Cmathsf%7BC%7D_N%5Ed%7D+a_1%5E%7B%5Calpha_1%7D+%5Cdots+a_N%5E%7B%5Calpha_N%7D+%5Cmathbf%7BE%7D%5BX%5E%7B%5Calpha_1%7D_N%281%29%5Cdots+X%5E%7B%5Calpha_N%7D_N%28N%29%5DF_N%28%5Calpha%29.&bg=FFFFFF&fg=000&s=0&c=20201002)

 the matrix
the matrix
![U=[U_{xy}]](https://s0.wp.com/latex.php?latex=U%3D%5BU_%7Bxy%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) by taking the squared modulus of each entry. Thus for any
by taking the squared modulus of each entry. Thus for any  the vector
the vector
 and because of this we named
and because of this we named  and
and  for all
for all 
 in
in  we defined its quantum characteristic function by
we defined its quantum characteristic function by
 into the closed unit disc in
into the closed unit disc in  uniquely determines the distribution
uniquely determines the distribution  Since the quantum characteristic function of
Since the quantum characteristic function of 
 and try to determine if
and try to determine if  is some sort of generating function encoding natural statistics of
is some sort of generating function encoding natural statistics of  for any
for any  permutation matrices
permutation matrices 
 Namely, we have
Namely, we have
 which is invariant under independent permutations of
which is invariant under independent permutations of 
 of symmetric homogeneous degree
of symmetric homogeneous degree 
 ranges over the set
ranges over the set  of
of  denoting the number of parts.
denoting the number of parts.  and any
and any  the evolution
the evolution  satisfies
satisfies  and that this bound is sharp.
and that this bound is sharp.
 , the normalized power sum polynomial of degree
, the normalized power sum polynomial of degree 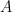 is
is

 Thus, the expansion of the quantum Fourier kernel
Thus, the expansion of the quantum Fourier kernel  is a generating function for expectations of polynomials in the random variables
is a generating function for expectations of polynomials in the random variables
 be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product
be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product


 we have
we have
 and non-increasing vectors
and non-increasing vectors 
 is
is


 we will have proved the claimed inequality (make sure you understand why).
we will have proved the claimed inequality (make sure you understand why).
![[|U_{ij}|^2]](https://s0.wp.com/latex.php?latex=%5B%7CU_%7Bij%7D%7C%5E2%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is a doubly stochastic matrix. Therefore, the maximum value of
is a doubly stochastic matrix. Therefore, the maximum value of  over all
over all 
 is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives
is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives
 where
where  is a uniformly random unitary matrix and
is a uniformly random unitary matrix and  in
in  is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.
is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.  is as close as we can get: it is uniform conditional on the distribution of its eigenvalues
is as close as we can get: it is uniform conditional on the distribution of its eigenvalues ![\varphi_{X_N}(A) = \mathbf{E}_{\mu_N}\left[e^{i \mathrm{Tr} AU_NB_NU_N^*}\right] = \mathbf{E}_{\sigma_N} \left[K_N(A,B_N)\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D_%7B%5Cmu_N%7D%5Cleft%5Be%5E%7Bi+%5Cmathrm%7BTr%7D+AU_NB_NU_N%5E%2A%7D%5Cright%5D+%3D+%5Cmathbf%7BE%7D_%7B%5Csigma_N%7D+%5Cleft%5BK_N%28A%2CB_N%29%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![K_N(A,B) = \mathbf{E}_{\eta_N}\left[e^{i\mathrm{Tr}\, AUBU^*}\right] = \int_{\mathbb{U}_N} e^{i \mathrm{Tr}\, AUBU^*} \eta_N(\mathrm{d}U)](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cmathbf%7BE%7D_%7B%5Ceta_N%7D%5Cleft%5Be%5E%7Bi%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D%5Cright%5D+%3D+%5Cint_%7B%5Cmathbb%7BU%7D_N%7D+e%5E%7Bi+%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D+%5Ceta_N%28%5Cmathrm%7Bd%7DU%29&bg=FFFFFF&fg=000&s=0&c=20201002)

 Moreover, show that
Moreover, show that ![\psi_{B_N}(A) = \mathbf{E}[K_N(A,B_N)] = \int_{\mathbb{R}^N} K_N(A,B) \sigma_N(\mathrm{d}B)](https://s0.wp.com/latex.php?latex=%5Cpsi_%7BB_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D%5BK_N%28A%2CB_N%29%5D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%5EN%7D+K_N%28A%2CB%29+%5Csigma_N%28%5Cmathrm%7Bd%7DB%29&bg=FFFFFF&fg=000&s=0&c=20201002)
 What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix
What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix  we have
we have

 is the diagonal of the random matrix
is the diagonal of the random matrix 

 The
The  is exactly what appears in the exponent of the quantum Fourier kernel:
is exactly what appears in the exponent of the quantum Fourier kernel:
 rather than
rather than  ). Now, the
). Now, the ![K_N(A,B) = \frac{1!2! \dots (N-1)!}{i^{N \choose 2}}\frac{\det [ e^{ia_xb_y}]}{\det[a_x^{N-y}]\det[b_x^{N-y}]}.](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cfrac%7B1%212%21+%5Cdots+%28N-1%29%21%7D%7Bi%5E%7BN+%5Cchoose+2%7D%7D%5Cfrac%7B%5Cdet+%5B+e%5E%7Bia_xb_y%7D%5D%7D%7B%5Cdet%5Ba_x%5E%7BN-y%7D%5D%5Cdet%5Bb_x%5E%7BN-y%7D%5D%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
![\varphi_{X}(T) = \mathbf{E}\left[e^{i\langle T,X \rangle}\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28T%29+%3D+%5Cmathbf%7BE%7D%5Cleft%5Be%5E%7Bi%5Clangle+T%2CX+%5Crangle%7D%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 ranges over the real vector space
ranges over the real vector space


 is the distribution of
is the distribution of  . With this definition in hand, we can consider special classes of random Hermitian matrices carved out by clauses of the form
. With this definition in hand, we can consider special classes of random Hermitian matrices carved out by clauses of the form
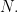 The group
The group 
 into the orthogonal group of the Euclidean space
into the orthogonal group of the Euclidean space 


 contains a diagonal matrix
contains a diagonal matrix  which is unique up to simultaneous permutations of its rows and columns.
which is unique up to simultaneous permutations of its rows and columns. satisfies
satisfies
 and all
and all  That is,
That is,  Indeed, for any arbitrary Hermitian
Indeed, for any arbitrary Hermitian 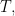 the Spectral Theorem says that
the Spectral Theorem says that  for some unitary matrix
for some unitary matrix  Unitary invariance of the characteristic function then gives
Unitary invariance of the characteristic function then gives

 so that the characteristic function of a unitarily invariant random Hermitian matrix
so that the characteristic function of a unitarily invariant random Hermitian matrix 

 , which are
, which are  real diagonal, we have
real diagonal, we have 
![\varphi_{X}(A) = \mathbb{E}[e^{i\mathrm{Tr}\, AX}] = \mathbb{E}[e^{i(a_1X_{11} + \dots + a_NX_{NN})}],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28A%29+%3D+%5Cmathbb%7BE%7D%5Be%5E%7Bi%5Cmathrm%7BTr%7D%5C%2C+AX%7D%5D+%3D+%5Cmathbb%7BE%7D%5Be%5E%7Bi%28a_1X_%7B11%7D+%2B+%5Cdots+%2B+a_NX_%7BNN%7D%29%7D%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)

 The exchangeability of
The exchangeability of  follows from Problem 4.1.
follows from Problem 4.1. is a Gaussian measure on
is a Gaussian measure on  have the same distribution for every
have the same distribution for every 


 Conversely, if
Conversely, if  and
and  by
by
 in the standard basis
in the standard basis  of
of  is the
is the  is the matrix of the linear transformation defined by
is the matrix of the linear transformation defined by  Unitary invariance says that
Unitary invariance says that  In this sense, unitarily invariant random Hermitian matrices are precisely those random matrices which correspond to canonically defined random Hermitian operators on finite-dimensional Hilbert space.
In this sense, unitarily invariant random Hermitian matrices are precisely those random matrices which correspond to canonically defined random Hermitian operators on finite-dimensional Hilbert space. be a
be a  its
its  into
into 
 defined by
defined by
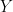 which is distinct from
which is distinct from ![\varphi_{X}(T) = \mathbf{E}\left[ e^{i \langle T,X\rangle} \right] = \int\limits_{\mathbb{L}} e^{i \langle T,X \rangle} \mu_{X}(\mathrm{d}X), \quad T \in \mathbb{L}.](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28T%29+%3D+%5Cmathbf%7BE%7D%5Cleft%5B+e%5E%7Bi+%5Clangle+T%2CX%5Crangle%7D+%5Cright%5D+%3D+%5Cint%5Climits_%7B%5Cmathbb%7BL%7D%7D+e%5E%7Bi+%5Clangle+T%2CX+%5Crangle%7D+%5Cmu_%7BX%7D%28%5Cmathrm%7Bd%7DX%29%2C+%5Cquad+T+%5Cin+%5Cmathbb%7BL%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)

 denotes the standard matrix
denotes the standard matrix  Thus, there is no definitional obstruction to analyzing a random variable
Thus, there is no definitional obstruction to analyzing a random variable  But there is a conceptual issue: random matrices are random variables which lead not just a triple life, but a quadruple life. More precisely, a random Hermitian matrix
But there is a conceptual issue: random matrices are random variables which lead not just a triple life, but a quadruple life. More precisely, a random Hermitian matrix  but also an operator
but also an operator  defined by matrix multiplication
defined by matrix multiplication
 and as such has geometric invariants such as eigenvalues and eigenvectors.
and as such has geometric invariants such as eigenvalues and eigenvectors.  of its matrix
of its matrix  -dimensional Euclidean space
-dimensional Euclidean space  not as a random operator on the
not as a random operator on the  Our main tool will be a discrete version of the
Our main tool will be a discrete version of the  be a subalgebra of
be a subalgebra of  . We say that
. We say that  in
in  such that
such that  . It turns out that there is only one separating subalgebra in
. It turns out that there is only one separating subalgebra in  .
. are distinct, then
are distinct, then 
 be an arbitrary point. By hypothesis, for each
be an arbitrary point. By hypothesis, for each  there is a function
there is a function  such that
such that  , and by centering and scaling we can assume without loss in generality that
, and by centering and scaling we can assume without loss in generality that

 in this product belongs to
in this product belongs to  . Since
. Since  was arbitrary,
was arbitrary,  of disjoint nonempty subsets of
of disjoint nonempty subsets of  is called a block of
is called a block of 
 of all partitions of
of all partitions of  if every block of
if every block of  . When
. When 
 of
of  .
. then
then  for some partition
for some partition  is a singleton set, and
is a singleton set, and  is a one-dimensional algebra. The unique partition of
is a one-dimensional algebra. The unique partition of  and
and  is the set of functions in
is the set of functions in  which are constant on
which are constant on  , which is all of
, which is all of 
 be a proper subalgebra of
be a proper subalgebra of  for all
for all  . Thus,
. Thus,  where
where  is the partition of
is the partition of  is isomorphic
is isomorphic  , and
, and  Thus, by the induction hypothesis,
Thus, by the induction hypothesis,  for
for 
 .
.