Let  be a Euclidean space and
be a Euclidean space and  its Borel sigma algebra.
its Borel sigma algebra.
Definition 1.1. A random variable taking values in is a measurable function  from a probability space
from a probability space  into
into 
Every random variable leads a double life: it is both a function into and a measure on
Definition 1.2. The distribution of is the probability measure on Borel sets  defined by
defined by

Strictly speaking, it is not correct to conflate with its distribution  , since one could have a second random variable
, since one could have a second random variable 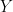 which is distinct from but has the same distribution – when this happens we say that and are “equal in distribution”, or “equal in law.” I heard the “double life” descriptor in a probability course taught by David Steinsaltz, and I think it is helpful provided one keeps the above caveat in mind. In fact I will go one step further and say that leads a triple life – it is also a complex-valued function on
which is distinct from but has the same distribution – when this happens we say that and are “equal in distribution”, or “equal in law.” I heard the “double life” descriptor in a probability course taught by David Steinsaltz, and I think it is helpful provided one keeps the above caveat in mind. In fact I will go one step further and say that leads a triple life – it is also a complex-valued function on
Definition 1.2. The characteristic function of is defined by the expectation
![\varphi_{X}(T) = \mathbf{E}\left[ e^{i \langle T,X\rangle} \right] = \int\limits_{\mathbb{L}} e^{i \langle T,X \rangle} \mu_{X}(\mathrm{d}X), \quad T \in \mathbb{L}.](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28T%29+%3D+%5Cmathbf%7BE%7D%5Cleft%5B+e%5E%7Bi+%5Clangle+T%2CX%5Crangle%7D+%5Cright%5D+%3D+%5Cint%5Climits_%7B%5Cmathbb%7BL%7D%7D+e%5E%7Bi+%5Clangle+T%2CX+%5Crangle%7D+%5Cmu_%7BX%7D%28%5Cmathrm%7Bd%7DX%29%2C+%5Cquad+T+%5Cin+%5Cmathbb%7BL%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
That is, the characteristic function of a random variable is the Fourier transform of its distribution.
Problem 1.1. Prove that the characteristic function of a random variable is an absolutely continuous function from into the closed unit disc in 
The characteristic function of faithfully encodes its distribution: if is another random variable, then and are equal in law if and only if they have the same characteristic function. This is a famous result in probability theory – a proof can be found in virtually any textbook on the subject. What makes characteristic functions so useful is that they transform probability into analysis, specifically harmonic analysis, which allows us to apply analytic methods to probabilistic questions. In particular, the famous Levy Continuity Theorem characterizes convergence in distribution for sequences of random variables in terms of the corresponding sequence of characteristic functions. This provides an efficient approach to the classical limit theorems of probability theory, the Law of Large Numbers and the Central Limit Theorem. Again, you will find an exposition of this approach in any standard probability text.
Random Matrix Theory is one of the most active areas of research in contemporary probability theory. It is a beautiful blend of algebra and probability which enjoys striking connections with many other fields, including combinatorics, number theory, physics, statistics, and something called “data science.” Strangely, RMT makes no use of characteristic functions – I am not aware of a single textbook on random matrices which even defines the characteristic function of a random matrix, despite the fact that this is simply a special case of the above construction.
To be concrete, let us take  to be the real vector space of
to be the real vector space of  Hermitian matrices equipped with the scalar product
Hermitian matrices equipped with the scalar product

where  denotes the standard matrix trace.
denotes the standard matrix trace.
Problem 1.2. Prove that the above really does define a scalar product on the space of Hermitian matrices, and write down an orthonormal basis.
Everything we have said so far about random variables taking values in a general Euclidean space is perfectly valid in the special case where  Thus, there is no definitional obstruction to analyzing a random variable taking values in via its characteristic function
Thus, there is no definitional obstruction to analyzing a random variable taking values in via its characteristic function  But there is a conceptual issue: random matrices are random variables which lead not just a triple life, but a quadruple life. More precisely, a random Hermitian matrix has associated to it not just a measure and a function
But there is a conceptual issue: random matrices are random variables which lead not just a triple life, but a quadruple life. More precisely, a random Hermitian matrix has associated to it not just a measure and a function  but also an operator
but also an operator  defined by matrix multiplication
defined by matrix multiplication

The random operator is a geometric object, a random linear transformation of  and as such has geometric invariants such as eigenvalues and eigenvectors.
and as such has geometric invariants such as eigenvalues and eigenvectors.
The statistical behavior of the geometric invariants of is encoded in the characteristic function  of its matrix . However, the characteristic function “sees” as a random vector in the
of its matrix . However, the characteristic function “sees” as a random vector in the  -dimensional Euclidean space
-dimensional Euclidean space  not as a random operator on the
not as a random operator on the 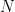 -dimensional Hilbert space and the question of how to extract geometric information from does not have an obvious or easy answer. Because of this, researchers in random matrix theory long ago abandoned characteristic functions. The subject has developed its own specific tools which have been very successful but have also distanced it from other parts of probability theory.
-dimensional Hilbert space and the question of how to extract geometric information from does not have an obvious or easy answer. Because of this, researchers in random matrix theory long ago abandoned characteristic functions. The subject has developed its own specific tools which have been very successful but have also distanced it from other parts of probability theory.
In recent years the question of whether a Fourier-analytic approach to random matrices might be possible after all has begun to be reconsidered. I do not claim to have a satisfactory answer to this question, but we will explore it in this topics course and perhaps see the beginnings of an answer. To get the most out of this endeavor, it would be best to absorb the standard approach to random matrix theory at the same time. The course notes by Todd Kemp and Terence Tao are both excellent resources which are freely available online.
Published by Jonathan Novak
Mathematician at UC San Diego.
View all posts by Jonathan Novak