Let  be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product
be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product

Let

be the function from Hermitian matrices to standard Euclidean space defined by

Theorem 5.1 (Hoffman-Wielandt Inequality). For any  we have
we have

Proof: By the spectral theorem, there are unitary matrices  and non-increasing vectors
and non-increasing vectors  such that
such that

The square of the Hilbert-Schmidt norm of the difference  is
is

and

Therefore, if we can show

holds for all  we will have proved the claimed inequality (make sure you understand why).
we will have proved the claimed inequality (make sure you understand why).
Now,

and ![[|U_{ij}|^2]](https://s0.wp.com/latex.php?latex=%5B%7CU_%7Bij%7D%7C%5E2%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is a doubly stochastic matrix. Therefore, the maximum value of
is a doubly stochastic matrix. Therefore, the maximum value of  over all
over all  is bounded by the maximum value of the function
is bounded by the maximum value of the function

as  ranges over all doubly stochastic matrices. Since
ranges over all doubly stochastic matrices. Since  is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives
is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives

and since the coordinates of 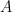 and
and  are nonincreasing the identity permutation is the optimal matching.
are nonincreasing the identity permutation is the optimal matching.
– QED
Now let  be a random Hermitian matrix.
be a random Hermitian matrix.
Theorem 5.2. The following are equivalent:
- The characteristic function of is invariant under unitary conjugation;
- The distribution of is invariant under unitary conjugation;
- is equal in distribution to a random Hermitian matrix of the form
 where
where  is a uniformly random unitary matrix and
is a uniformly random unitary matrix and  is a random real diagonal matrix independent of .
is a random real diagonal matrix independent of .
We have already proved the equivalence of (1) and (2).
Problem 5.2. Complete the proof of Theorem 5.1.
At this point we have enough information to explain how the characteristic function of a unitarily invariant random Hermitian determines the joint distribution of its eigenvalues.
Theorem 5.2. The characteristic function of a unitarily invariant random Hermitian matrix is equal to the quantum characteristic function of its eigenvalues.
Obviously, this statement needs to be explained.
Let be a real random vector whose distribution  in
in  is arbitrary, and let be an independent random unitary matrix whose distribution
is arbitrary, and let be an independent random unitary matrix whose distribution  in
in  is uniform (Haar) measure. Then
is uniform (Haar) measure. Then  is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.
is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.
Because is non-compact, there is no such thing as a uniformly random Hermitian matrix. The matrix  is as close as we can get: it is uniform conditional on the distribution of its eigenvalues
is as close as we can get: it is uniform conditional on the distribution of its eigenvalues  If
If 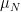 is the distribution of in , a random sample from is obtained by sampling a vector from the distribution on
is the distribution of in , a random sample from is obtained by sampling a vector from the distribution on  and then choosing a uniformly random point on the -orbit in which contains this vector.
and then choosing a uniformly random point on the -orbit in which contains this vector.
In terms of characteristic functions, this says that
![\varphi_{X_N}(A) = \mathbf{E}_{\mu_N}\left[e^{i \mathrm{Tr} AU_NB_NU_N^*}\right] = \mathbf{E}_{\sigma_N} \left[K_N(A,B_N)\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D_%7B%5Cmu_N%7D%5Cleft%5Be%5E%7Bi+%5Cmathrm%7BTr%7D+AU_NB_NU_N%5E%2A%7D%5Cright%5D+%3D+%5Cmathbf%7BE%7D_%7B%5Csigma_N%7D+%5Cleft%5BK_N%28A%2CB_N%29%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
where
![K_N(A,B) = \mathbf{E}_{\eta_N}\left[e^{i\mathrm{Tr}\, AUBU^*}\right] = \int_{\mathbb{U}_N} e^{i \mathrm{Tr}\, AUBU^*} \eta_N(\mathrm{d}U)](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cmathbf%7BE%7D_%7B%5Ceta_N%7D%5Cleft%5Be%5E%7Bi%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D%5Cright%5D+%3D+%5Cint_%7B%5Cmathbb%7BU%7D_N%7D+e%5E%7Bi+%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D+%5Ceta_N%28%5Cmathrm%7Bd%7DU%29&bg=FFFFFF&fg=000&s=0&c=20201002)
is the characteristic function of a uniformly random Hermitian matrix from the orbit containing  viewed as a diagonal matrix. Thus,
viewed as a diagonal matrix. Thus,  is the characteristic function of a uniformly random Hermitian matrix with prescribed eigenvalues. This defines a bounded symmetric kernel
is the characteristic function of a uniformly random Hermitian matrix with prescribed eigenvalues. This defines a bounded symmetric kernel

which we call the quantum Fourier kernel, because it is a superposition of standard 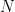 -dimensional Fourier kernels
-dimensional Fourier kernels

Problem 5.3. Prove that indeed  and
and  Moreover, show that is invariant under independent permutations of the coordinates of
Moreover, show that is invariant under independent permutations of the coordinates of 
If is the quantum Fourier kernel, then
![\psi_{B_N}(A) = \mathbf{E}[K_N(A,B_N)] = \int_{\mathbb{R}^N} K_N(A,B) \sigma_N(\mathrm{d}B)](https://s0.wp.com/latex.php?latex=%5Cpsi_%7BB_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D%5BK_N%28A%2CB_N%29%5D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%5EN%7D+K_N%28A%2CB%29+%5Csigma_N%28%5Cmathrm%7Bd%7DB%29&bg=FFFFFF&fg=000&s=0&c=20201002)
deserves to be called the quantum characteristic function of random vector , or the quantum Fourier transform of the probability measure  What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix
What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix  we have
we have

where is any -dimensional random vector whose components are eigenvalues of (this is what Theorem 5.2 means). We can also state the above as

where  is the diagonal of the random matrix .
is the diagonal of the random matrix .
The conclusion to be drawn from all of this is that figuring out how to analyze the eigenvalues of a unitarily invariant random Hermitian matrix given its characteristic function  is exactly the same thing as figuring out how to analyze an arbitrary random real vector given its quantum characteristic function
is exactly the same thing as figuring out how to analyze an arbitrary random real vector given its quantum characteristic function 
Before telling you how we will do this, let me tell you how we won’t. The main reason the Hoffman-Weilandt theorem was presented in this lecture is that the proof makes you think about maximizing the function

over unitary matrices  The action
The action  is exactly what appears in the exponent of the quantum Fourier kernel:
is exactly what appears in the exponent of the quantum Fourier kernel:

(I am going to stop writing the Haar measure explicitly in Haar integrals, so just  rather than
rather than  ). Now, the method of stationary phase predicts that should be approximated by contributions from the local maxima of the action, which means that this integral should localize to a sum over permutations. This turns out to be exactly correct, not just a good approximation, and the reasons for this are rooted in symplectic geometry. The end result is the following determinantal formula for the quantum Fourier kernel.
). Now, the method of stationary phase predicts that should be approximated by contributions from the local maxima of the action, which means that this integral should localize to a sum over permutations. This turns out to be exactly correct, not just a good approximation, and the reasons for this are rooted in symplectic geometry. The end result is the following determinantal formula for the quantum Fourier kernel.
Theorem 5.4 (HCIZ Formula). For any with no repeated coordinates we have
![K_N(A,B) = \frac{1!2! \dots (N-1)!}{i^{N \choose 2}}\frac{\det [ e^{ia_xb_y}]}{\det[a_x^{N-y}]\det[b_x^{N-y}]}.](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cfrac%7B1%212%21+%5Cdots+%28N-1%29%21%7D%7Bi%5E%7BN+%5Cchoose+2%7D%7D%5Cfrac%7B%5Cdet+%5B+e%5E%7Bia_xb_y%7D%5D%7D%7B%5Cdet%5Ba_x%5E%7BN-y%7D%5D%5Cdet%5Bb_x%5E%7BN-y%7D%5D%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
This is a very interesting formula which makes manifest all the symmetries of the quantum Fourier kernel claimed in Problem 5.3 (but, you should solve that problem without using the determinantal formula). It is also psychologically satisfying in that it shows exactly how the quantum Fourier kernel is built out of classical one-dimensional Fourier kernels. However, it is not really good for much else. We will explain this further in the coming lectures. But first we will adapt all of the above to random rectangular matrices.