Let  be the linear algebra of a Hilbert space
be the linear algebra of a Hilbert space 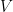 of dimension at least two. We have seen that there does not exist an algebra homomorphism
of dimension at least two. We have seen that there does not exist an algebra homomorphism  . This suggests that the commutativity index of is very low, or equivalently that its noncommutativity index is very high. To make this precise, we want to determine the center of
. This suggests that the commutativity index of is very low, or equivalently that its noncommutativity index is very high. To make this precise, we want to determine the center of 
Definition 6.1. Given a subalgebra 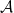 of , a subspace
of , a subspace  of is said to be –invariant if for every
of is said to be –invariant if for every  and every
and every  we have
we have 
Proposition 6.1. If  is an -invariant subspace, then either
is an -invariant subspace, then either  or
or 
Problem 6.1. Prove Proposition 6.1.
Theorem 6.2. The center of is the set  of scalar operators.
of scalar operators.
Proof: Let  be a central element, and let
be a central element, and let  be an eigenvalue of
be an eigenvalue of  By definition, this means that
By definition, this means that  is not invertible in
is not invertible in  which is equivalent to saying that
which is equivalent to saying that  is a nonzero subspace of . We claim that, because
is a nonzero subspace of . We claim that, because 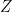 is a central element in the
is a central element in the  -eigenspace of is -invariant. Indeed, for any
-eigenspace of is -invariant. Indeed, for any  we have
we have

which shows that  is again in the -eigenspace of Since this space has positive dimension, Proposition 6.1 forces
is again in the -eigenspace of Since this space has positive dimension, Proposition 6.1 forces  so that
so that  for every
for every 
-QED
Having understood the center of let us consider arbitrary commutative subalgebras of These can be understood using the Spectral Theorem from Math 202A, which may be stated as follows.
Theorem 6.3. If  are commuting normal operators, then there exists an orthonormal basis
are commuting normal operators, then there exists an orthonormal basis  such that
such that 
Since  is isomorphic to
is isomorphic to  , we can combine the above formulation of the Spectral Theorem with the characterization of commutative algebras obtained in Lecture 1 and the classification of subalgebras of function algebras obtained in Lecture 3 to prove the following.
, we can combine the above formulation of the Spectral Theorem with the characterization of commutative algebras obtained in Lecture 1 and the classification of subalgebras of function algebras obtained in Lecture 3 to prove the following.
Theorem 6.4. Every commutative subalgebra of is isomorphic to a function algebra.
Proof: Let be a subalgebra of Since is a vector space, it has a basis  where
where  If is commutative, all of its elements are normal (Theorem 1.3 in Lecture 1), and the basis
If is commutative, all of its elements are normal (Theorem 1.3 in Lecture 1), and the basis  of consists of commuting normal operators. By Theorem 6.3, there exists an orthonormal basis such that
of consists of commuting normal operators. By Theorem 6.3, there exists an orthonormal basis such that  , and therefore is a subalgebra of . Since is isomorphic to the function algebra
, and therefore is a subalgebra of . Since is isomorphic to the function algebra  and since every subalgebra of is isomorphic to a function algebra (Lecture 3), it follows that is isomorphic to a function algebra.
and since every subalgebra of is isomorphic to a function algebra (Lecture 3), it follows that is isomorphic to a function algebra.
In fact, we can be more precise (though we don’t need to be): is isomorphic to  for some partition
for some partition  of
of  and we can describe this partition in terms of the eigenspaces of the commuting normal operators . Namely, each of the operators
and we can describe this partition in terms of the eigenspaces of the commuting normal operators . Namely, each of the operators  ,
,  induces a partition
induces a partition  of
of  such that
such that  belong to the same block of if and only if they belong to the same eigenspace of
belong to the same block of if and only if they belong to the same eigenspace of  Letting
Letting  be the coarsest partition of finer than all of the ‘s, a little thought reveals that is isomorphic to
be the coarsest partition of finer than all of the ‘s, a little thought reveals that is isomorphic to 
-QED
As we have just seen, for any commutative subalgebra of the spectral theorem guarantees a corresponding decomposition of into a direct sum of orthogonal one-dimensional subspaces on which acts diagonally. If is a noncommutative subalgebra of , this is no longer the case. Nevertheless, we can consider the set of all -invariant subspaces of  which is an induced sublattice of the lattice of all subspaces of , since the intersection of two -invariant subspaces is again -invariant, and likewise the span of the union of two -invariant subspaces is again -invariant (exercise: check these statements). For any subalgebra
which is an induced sublattice of the lattice of all subspaces of , since the intersection of two -invariant subspaces is again -invariant, and likewise the span of the union of two -invariant subspaces is again -invariant (exercise: check these statements). For any subalgebra  , the lattice of -invariant subspaces contains at least
, the lattice of -invariant subspaces contains at least  and
and  An important theorem of Burnside characterizes subalgebras of for which this minimum is achieved.
An important theorem of Burnside characterizes subalgebras of for which this minimum is achieved.
Theorem 6.5. (Burnside) A subalgebra of has exactly two invariant subspaces if and only if 
Proof: An elementary proof of Burnside’s theorem by induction in the dimension of can be found here.
-QED
Corollary 6.6. A proper subalgebra of has at least four invariant subspaces.
Proof: The zero space and the total space are -invariant, and since  there is a third -invariant subspace
there is a third -invariant subspace  by Burnside’s theorem. The orthogonal complement
by Burnside’s theorem. The orthogonal complement  of is again a nonzero proper subspace of and we claim it is -invariant. Indeed, let
of is again a nonzero proper subspace of and we claim it is -invariant. Indeed, let  and
and  Then, for any we have
Then, for any we have

where we used the fact that is -invariant. This shows  i.e. is -invariant.
i.e. is -invariant.
– QED
We can attempt to classify subalgebras of by adapting our approach to the classification of subalgebras of where we looked at subalgebras of corresponding to partitions of the set  To emulate this approach, we need the Hilbert space analogue of a set partition, in which “nonempty” is replaced with “nonzero” and “disjoint” becomes “orthogonal.”
To emulate this approach, we need the Hilbert space analogue of a set partition, in which “nonempty” is replaced with “nonzero” and “disjoint” becomes “orthogonal.”
Definition 6.2. A linear partition of is a set  of nonzero pairwise orthogonal subspaces of whose union spans We refer to the subspaces
of nonzero pairwise orthogonal subspaces of whose union spans We refer to the subspaces  as the blocks of
as the blocks of  and write
and write

Given a linear partition of we define  to be the set of all operators
to be the set of all operators  such that every block
such that every block  is
is 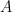 -invariant.
-invariant.
Problem 6.2. Prove that is a subalgebra of
Here our construction starts to diverge from what we saw in the setting of function algebras: unless  is the linear partition of consisting of a single block, in which case
is the linear partition of consisting of a single block, in which case  the subalgebra is definitely not isomorphic to the algebra of all linear operators on a Hilbert space. Indeed, consider the case where
the subalgebra is definitely not isomorphic to the algebra of all linear operators on a Hilbert space. Indeed, consider the case where  is a linear partition of with two blocks, i.e.
is a linear partition of with two blocks, i.e.  . Let
. Let  be an ordered basis of
be an ordered basis of  and let
and let  be an ordered basis of
be an ordered basis of  Then
Then  is an ordered basis of , and consists of all operators in
is an ordered basis of , and consists of all operators in  whose matrix relative to this ordered basis has the form
whose matrix relative to this ordered basis has the form
![[A]_{(e_1,\dots,e_m,f_1,\dots,f_n)}=\begin{bmatrix} M_1 & {} \\ {} & M_2 \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5BA%5D_%7B%28e_1%2C%5Cdots%2Ce_m%2Cf_1%2C%5Cdots%2Cf_n%29%7D%3D%5Cbegin%7Bbmatrix%7D+M_1+%26+%7B%7D+%5C%5C+%7B%7D+%26+M_2+%5Cend%7Bbmatrix%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
with  and
and  Thus,
Thus,  is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,
is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,

The question now is whether the above can reversed: given a subalgebra of does there exist a linear partition such that  ? If
? If  the answer is clearly “yes” since we have
the answer is clearly “yes” since we have  Thus we consider the case where is a proper subalgebra of Our starting point is Burnside’s theorem, which guarantees the existence of an -invariant subspace
Thus we consider the case where is a proper subalgebra of Our starting point is Burnside’s theorem, which guarantees the existence of an -invariant subspace  . Together with the corollary to Burnside’s theorem, we thus have a linear partition
. Together with the corollary to Burnside’s theorem, we thus have a linear partition  of whose blocks are -invariant. We now ask whether has a proper non-trivial subspace invariant under . If it does we can split it into the orthogonal direct sum of two smaller -invariant subspaces; if not is said to be –irreducible. Continuing this process, for both and , we get the following.
of whose blocks are -invariant. We now ask whether has a proper non-trivial subspace invariant under . If it does we can split it into the orthogonal direct sum of two smaller -invariant subspaces; if not is said to be –irreducible. Continuing this process, for both and , we get the following.
Theorem 6.7. (Maschke’s theorem) There exists a linear partition of whose blocks are -invariant and -irreducible subspaces.
Now consider the linear partition of into -invariant, -irreducible subspaces we have constructed. It is tempting to hope that  Unfortunately, this is not quite correct. For example, consider the case where is a Hilbert space of even dimension
Unfortunately, this is not quite correct. For example, consider the case where is a Hilbert space of even dimension  Let
Let  be an othornormal basis of , and consider the set of all operators such that
be an othornormal basis of , and consider the set of all operators such that

Then is a subalgebra of – it consists of all operators whose matrix in the basis is block diagonal with two identical blocks. Now  , where
, where  and
and  and this is a linear partition of into -invariant and -irreducible subspaces. However, the algebra
and this is a linear partition of into -invariant and -irreducible subspaces. However, the algebra  is not — it is the larger algebra of operators whose matrix relative to is block diagonal, but not necessarily with both blocks being the same. In other words consists of all matrices of the form
is not — it is the larger algebra of operators whose matrix relative to is block diagonal, but not necessarily with both blocks being the same. In other words consists of all matrices of the form

whereas consists of all matrices of the form

To account for the above situation, we need a notion of equivalence for -invariant subspaces of .
Definition 6.3. We say that two -invariant subspaces  of are -equivalent if we can choose bases in
of are -equivalent if we can choose bases in 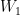 and
and  such that, for every
such that, for every  the matrix of the restriction of to is the same as the matrix of the restriction of of to
the matrix of the restriction of to is the same as the matrix of the restriction of of to
Now let  be a set parameterizing equivalence classes of -invariant and -irreducible subspaces of For each
be a set parameterizing equivalence classes of -invariant and -irreducible subspaces of For each  let
let  be a representative of the the equivalence class corresponding to
be a representative of the the equivalence class corresponding to 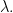 The following result is a very simple version of the Artin-Wedderburn theorem. We will eventually prove this theorem for a special class of algebras coming from finite groups.
The following result is a very simple version of the Artin-Wedderburn theorem. We will eventually prove this theorem for a special class of algebras coming from finite groups.
Theorem 6.8. We have 


















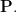





















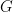 be a group with group law written multiplicatively: for any elements
be a group with group law written multiplicatively: for any elements  , their product is
, their product is  . Since
. Since  of functions
of functions  . As explained in
. As explained in 
 so from the point of view of this construction the fact that
so from the point of view of this construction the fact that  whose elements are functions
whose elements are functions 
 Thus for any two functions
Thus for any two functions




 viewed as elements of
viewed as elements of 
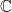 , we define it using the the natural involution in
, we define it using the the natural involution in 



 , where
, where  is the group unit, as opposed to being the constant function equal to
is the group unit, as opposed to being the constant function equal to 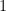 on every
on every  , which is the multiplicative unit in
, which is the multiplicative unit in 

 = \sum\limits_{h \in G}A(gh^{-1})B(h)](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7DA%28gh%5E%7B-1%7D%29B%28h%29&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \overline{A(g^{-1})}.](https://s0.wp.com/latex.php?latex=%5BA%5E%2A%5D%28g%29+%3D+%5Coverline%7BA%28g%5E%7B-1%7D%29%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 are a basis of
are a basis of  are isomorphic groups then their convolution algebras
are isomorphic groups then their convolution algebras  are isomorphic algebras (the converse is false, bonus points if you give a counterexample). Also show that
are isomorphic algebras (the converse is false, bonus points if you give a counterexample). Also show that 

 of
of  .
. is a subalgebra of
is a subalgebra of 

 is the constant function
is the constant function
 is selfadjoint (make sure you understand why), and also
is selfadjoint (make sure you understand why), and also

 just permutes the points of the group (make sure you understand why). Therefore,
just permutes the points of the group (make sure you understand why). Therefore,  and we conclude that the average of all elementary functions
and we conclude that the average of all elementary functions  is a projection in
is a projection in  and
and  .
. are linearly independent (make sure you understand why), we have located a two-dimensional subalgebra inside
are linearly independent (make sure you understand why), we have located a two-dimensional subalgebra inside  must also have odd order, and consequently the subalgebra
must also have odd order, and consequently the subalgebra  cannot be the algebra of functions vanishing outside some subgroup
cannot be the algebra of functions vanishing outside some subgroup  cannot be even.
cannot be even. and computed their characters. Proceeding by bare hands becomes difficult quickly since the cardinality of
and computed their characters. Proceeding by bare hands becomes difficult quickly since the cardinality of 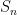 grows very rapidly (indeed, superexponentially) with
grows very rapidly (indeed, superexponentially) with 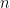 .
.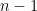 dimensional. This isn’t much – the number of irreducible representations of
dimensional. This isn’t much – the number of irreducible representations of  which according to the
which according to the 
 of
of  ,
,  and
and  is the group homomorphism defined by
is the group homomorphism defined by

 is the number of fixed points (i.e. one-cycles) of the permutation
is the number of fixed points (i.e. one-cycles) of the permutation  Therefore,
Therefore,
 is the set of fixed points of
is the set of fixed points of  . To understand this sum, let us begin with the simpler version without the squares. By
. To understand this sum, let us begin with the simpler version without the squares. By 
 is the number of orbits of
is the number of orbits of  is one, i.e.
is one, i.e.  To get the exponent of
To get the exponent of 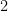 into the equation, let
into the equation, let  by
by  Then, we have
Then, we have 
 . Applying Burnside’s Lemma we thus have
. Applying Burnside’s Lemma we thus have 
 Indeed, consider any point
Indeed, consider any point  Either
Either  or
or  . In the first case, the orbit of
. In the first case, the orbit of 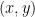 under
under 
![\mathbb{E}[Z]=1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5D%3D1&bg=FFFFFF&fg=000&s=0&c=20201002) and
and ![\mathbb{E}[Z^2]=2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5E2%5D%3D2&bg=FFFFFF&fg=000&s=0&c=20201002) you might be tempted to assume that the
you might be tempted to assume that the 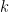 th moment of
th moment of ![\mathbb{E}[Z^k]=k,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BZ%5Ek%5D%3Dk%2C&bg=FFFFFF&fg=000&s=0&c=20201002) but this is wrong and the correct answer is quite a bit more interesting.
but this is wrong and the correct answer is quite a bit more interesting. 
 be the random variable defined by
be the random variable defined by 
 of the permutation representation of
of the permutation representation of 
 which is an irreducible representation of
which is an irreducible representation of  we have
we have  and therefore
and therefore

 Indeed,
Indeed,  and for
and for  its dimension is strictly larger than one.
its dimension is strictly larger than one. 
 follows from its irreducibility. Likewise, since
follows from its irreducibility. Likewise, since  the standard representation of the symmetric group is irreducible.
the standard representation of the symmetric group is irreducible.  is a subgroup of
is a subgroup of  that have
that have 


 be a set indexing isomorphism classes of irreducible unitary representations of
be a set indexing isomorphism classes of irreducible unitary representations of  or equivalently irreducible linear representations of its convolution algebra
or equivalently irreducible linear representations of its convolution algebra  For each
For each  let
let  be a representative of the corresponding isomorphism class. We know
be a representative of the corresponding isomorphism class. We know 
 in
in  under
under  is all of
is all of  by Burnside’s theorem. On the other hand, viewing
by Burnside’s theorem. On the other hand, viewing  as a subalgebra of
as a subalgebra of  the image of
the image of  but not necessarily an irreducible one. So viewed as a representation of
but not necessarily an irreducible one. So viewed as a representation of 
 of partitions of
of partitions of  and
and  is the multiplicity of
is the multiplicity of  in
in  be arbitrary but fixed, and let
be arbitrary but fixed, and let  be a representative of the corresponding isomorphism class of irreducible unitary representations of the symmetric group
be a representative of the corresponding isomorphism class of irreducible unitary representations of the symmetric group  where
where  as vectors
as vectors  with
with  entries, which are weakly decreasing positive integers whose sum is
entries, which are weakly decreasing positive integers whose sum is  -dimensional. An important point is that there is no canonical way to say which of the abstract irreducible representations
-dimensional. An important point is that there is no canonical way to say which of the abstract irreducible representations  The main result in the representation theory of the symmetric groups is that it is possible to give a concrete construction of each
The main result in the representation theory of the symmetric groups is that it is possible to give a concrete construction of each 
 such that
such that 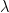 can be obtained from
can be obtained from 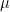 by adding a single cell.
by adding a single cell. of
of  is viewed as a representation of
is viewed as a representation of 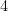 as a fixed point, its decomposition into irreducible representations of
as a fixed point, its decomposition into irreducible representations of 
 If we instead start with
If we instead start with  then as a representation of
then as a representation of 



 in the cells of
in the cells of  ,
,  A related question is to calculate the character of this representation, i.e. the function on
A related question is to calculate the character of this representation, i.e. the function on 
 of the class algebra
of the class algebra  where we recall that
where we recall that  of the class basis
of the class basis  . This is an equivalent problem because
. This is an equivalent problem because
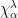 is the value of
is the value of  on any permutation
on any permutation  For any Young diagram
For any Young diagram  define the content
define the content  of this cell to be its column index minus its row index.
of this cell to be its column index minus its row index.

 be the corresponding irreducible character, i.e. function
be the corresponding irreducible character, i.e. function  defined by
defined by
 of the class algebra
of the class algebra  satisfies the orthogonality relations
satisfies the orthogonality relations

 be the set of conjugacy classes in
be the set of conjugacy classes in  let
let  be the indicator function of the class
be the indicator function of the class 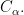 The class basis
The class basis  satisfies the orthogonality relations
satisfies the orthogonality relations

 character orthogonality takes the form
character orthogonality takes the form
 are conjugate for every
are conjugate for every  If
If 
 we have
we have

 as the column index and
as the column index and 
![[c_{\alpha\beta\gamma}]_{\alpha,\beta,\gamma \in \Lambda}](https://s0.wp.com/latex.php?latex=%5Bc_%7B%5Calpha%5Cbeta%5Cgamma%7D%5D_%7B%5Calpha%2C%5Cbeta%2C%5Cgamma+%5Cin+%5CLambda%7D&bg=FFFFFF&fg=000&s=0&c=20201002) such that
such that
 we have
we have
 On one hand, we have
On one hand, we have
 is the identity operator. On the other hand,
is the identity operator. On the other hand, 


 multiply both sides by
multiply both sides by  and sum over
and sum over 


 consists of orthogonal projections. In particular, the span of
consists of orthogonal projections. In particular, the span of 
 we have
we have


 leaving
leaving
 In the case of an ambivalent group, the Fourier basis is simply a rescaling of the character basis by nonzero (indeed, positive) factors. In the general case we have the following.
In the case of an ambivalent group, the Fourier basis is simply a rescaling of the character basis by nonzero (indeed, positive) factors. In the general case we have the following. , we have
, we have
 of the convolution algebra
of the convolution algebra 

 Recall also that the class algebra
Recall also that the class algebra  if and only if
if and only if 
 then
then 
 is an algebra homomorphism, we have
is an algebra homomorphism, we have 
 to be in
to be in 
 is all of
is all of  , with
, with  and
and  the identity operator in
the identity operator in  we have
we have  for some
for some  Thus, we have a map
Thus, we have a map
 of the operator
of the operator  This map is called the central character of
This map is called the central character of  is an algebra homomorphism
is an algebra homomorphism  and that
and that

 is a central function on
is a central function on  i.e.
i.e.
 be the subspace of
be the subspace of  . We will do this by showing that
. We will do this by showing that  In other words, the only central function on
In other words, the only central function on 
 be the central character of
be the central character of  and let
and let

 to be the zero operator in
to be the zero operator in  , and hence
, and hence  be the indicator function of
be the indicator function of  i.e.
i.e.

 denotes the value of
denotes the value of  for any group element
for any group element  Thus, the functions
Thus, the functions 
 and
and  are the same set if
are the same set if  and disjoint if
and disjoint if 


 is orthogonal in
is orthogonal in 


 extending our result from the case of abelian groups, where
extending our result from the case of abelian groups, where 
 be a representative of the isomorphism class of irreps corresponding to
be a representative of the isomorphism class of irreps corresponding to 

 i.e. that the number of irreducible unitary representations of
i.e. that the number of irreducible unitary representations of 

 This is a subalgebra of the linear algebra
This is a subalgebra of the linear algebra 
 of
of  is the restriction of
is the restriction of  to the subspace
to the subspace  Since
Since 
 is the number of blocks of the linear partition
is the number of blocks of the linear partition  and
and


 we have
we have


 is the multiplicity of
is the multiplicity of 
 of
of 
 Let
Let 

 implies
implies 


 For the converse, suppose it is the case that
For the converse, suppose it is the case that 


 forces
forces
 has exactly one term equal to one and all other terms equal to zero, so that the isotypic decomposition of
has exactly one term equal to one and all other terms equal to zero, so that the isotypic decomposition of  for some
for some  in which
in which  -scalar product and
-scalar product and 
 = \sum\limits_{k \in G}E_g(k)A(k^{-1}h) = A(g^{-1}h), \quad h \in G.](https://s0.wp.com/latex.php?latex=%5BE_gA%5D%28h%29+%3D+%5Csum%5Climits_%7Bk+%5Cin+G%7DE_g%28k%29A%28k%5E%7B-1%7Dh%29+%3D+A%28g%5E%7B-1%7Dh%29%2C+%5Cquad+h+%5Cin+G.&bg=FFFFFF&fg=000&s=0&c=20201002)
 acts on the group basis of
acts on the group basis of 

 be their characters, i.e. the functions
be their characters, i.e. the functions 
 are defined using the trace, they are central functions on
are defined using the trace, they are central functions on 
 Thus,
Thus,  Indeed, if these representations are isomorphic, then (by definition) there is a unitary vector space isomorphism
Indeed, if these representations are isomorphic, then (by definition) there is a unitary vector space isomorphism  which has the additional property that the equation
which has the additional property that the equation
 for every
for every  whence
whence 
 and in particular we do not know whether or not it is finite. For each
and in particular we do not know whether or not it is finite. For each 


 are irreducible representations, Schur’s Lemma tells us that
are irreducible representations, Schur’s Lemma tells us that 

 We will see next lecture that in fact equality holds: up to isomorphism, the number of irreducible unitary representations of
We will see next lecture that in fact equality holds: up to isomorphism, the number of irreducible unitary representations of 
 ;
; ;
; with equality if and only if
with equality if and only if 
 for all
for all  The expansion of any vector
The expansion of any vector  with respect to an orthonormal basis is
with respect to an orthonormal basis is
 is
is 



 together with multiplication defined by composition,
together with multiplication defined by composition, = A(B(v)),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28v%29+%3D+A%28B%28v%29%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 which is characterized by the condition
which is characterized by the condition 

 The matrix elements of
The matrix elements of 
 in
in  for all
for all  compute the matrix elements of the product
compute the matrix elements of the product 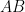 in terms of the matrix elements of its factors.
in terms of the matrix elements of its factors. are defined by
are defined by
 elementary operators in
elementary operators in 
 and
and 
 ,
,  are orthogonal projections in
are orthogonal projections in  and
and  Thus,
Thus,  is a linearly independent set in
is a linearly independent set in  We call
We call  we say that
we say that 
 of elementary operators spans
of elementary operators spans  be its matrix elements relative to the orthonormal basis
be its matrix elements relative to the orthonormal basis  by
by
 Indeed, the matrix elements of
Indeed, the matrix elements of 


 ;
; with equality if and only if
with equality if and only if 




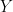 be two orthonormal bases of
be two orthonormal bases of  .
.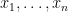 of
of  of
of  defined by
defined by  is unitary. We have
is unitary. We have 


 of numbers
of numbers  such that
such that  is not invertible. Elements of
is not invertible. Elements of 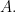
 being non-invertible is equivalent to
being non-invertible is equivalent to  and because
and because  is a polynomial in
is a polynomial in  the
the 
 is an eigenvalue of an operator
is an eigenvalue of an operator  is called the
is called the  and any nonzero vector
and any nonzero vector  is said to be an eigenvector of
is said to be an eigenvector of 



 for all
for all 
 form an orthonormal basis of
form an orthonormal basis of  we have
we have
 is a linear functional which satisfies
is a linear functional which satisfies  for all
for all  , then
, then  is a scalar multiple of the trace.
is a scalar multiple of the trace. of
of 

 such that
such that  for all
for all  Thus for any
Thus for any

