In this lecture we will review what we have done so far from a slightly different perspective. Starting with the Fourier kernel
which is defined by we can define the characteristic function of a random variable with distribution by
This is an absolutely continuous function from into the closed unit disc in which uniquely determines the measure To get some feel for which this might be, expand the Fourier kernel in a power series,
Then, assuming we can interchange expectation with the summation we get
where
,
is the degree moment of or equivalently of So at least heuristically, the characteristic function of is a generating function for the moments of its distribution. One situation in which this formal computation is quantitatively correct is when has compact support, so if the characteristic function does indeed characterize the distribution of then it must be the case that is characterized by its moments. It is not difficult to see why the why the moments of a probability measure with compact support determine it completely: if we know how to compute the expectation of polynomial functions of , then thanks to the Weierstrass approximation theorem we also know how to compute the expectation of continuous functions of and this in turn tells us how measures intervals, by taking expectations of smooth bump functions. Of course, to obtain the fully general result that the characteristic function of completely determines its distribution a different argument is needed. For example, the Cauchy distribution has no moments whatsoever, but its characteristic function still exists and determines it uniquely.
The -dimensional Fourier kernel
is defined by
and the characteristic function of an -dimensional random vector is the continuous function defined by
where is the distribution of in It is still true that exists and uniquely determines , and we can tell a similar story about moments which supports this statement. To do so we first have to expand the -dimensional Fourier kernel in a power series. This is easy but let us first make some general observations about what this expansion must look like before doing the computation. Since and
for any permutation matrix we have
where is a homogeneous polynomial of degree in which is invariant under independent permutations of these variables. Therefore, we have
where is the set of weak -part compositions of and is a numerical coefficient. It is easy to determine this coefficient explicitly: since
we have
the multinomial coefficient. Thus, the expected value of is a generating polynomial for degree mixed moments of the entries of the random vector ,
In the previous lectures we defined a strange new kernel
by
where the integration is against Haar probability measure on the unitary group and for any the matrix
is obtained from by taking the squared modulus of each entry. Thus for any the vector
has coordinates which are superpositions of the coordinates of and because of this we named the -dimensional “quantum Fourier kernel.”
Problem 7.1. Prove that is a bounded symmetric kernel on $late \mathbb{R}^N$, i.e. and for all
Then, given a random vector with distribution in we defined its quantum characteristic function by
This is a continuous function from into the closed unit disc in , and we claimed that uniquely determines the distribution of Since the quantum characteristic function of is clearly distinct from its classical characteristic function
this must be true for some different reason. To understand what this reason might be, at least heuristically, we could proceed along the same lines we did with and try to determine if is some sort of generating function encoding natural statistics of .
Let’s give this a try. The first step is to expand the quantum Fourier kernel as a power series. Before doing the computation, we can look for some easy symmetries of which will tell us in advance what a series expansion of ought to look like. In fact, the quantum Fourier kernel is much more symmetric than the classical Fourier kernel – it is invariant under independent (as opposed to simultaneous) permutations of the coordinates of its arguments.
Problem 7.2. Prove that for any and any permutation matrices
From Problems 7.1 and 7.2, we can indeed infer the general form of a series expansion of the kernel Namely, we have
where is a homogeneously degree polynomial function of the coordinates which is invariant under independent permutations of and and stable under swapping these two sets of variables. What does such a polynomial look like?
A classical theorem of Newton asserts that a symmetric homogeneous degree polynomial in variables is a polynomial function of the power-sum polynomials
Equivalently, the vector space of symmetric homogeneous degree polynomials in variables has as a linear basis the polynomials
where ranges over the set of partitions of with largest part at most and denoting the number of parts.
Problem 7.3. Prove that for any and any the evolution satisfies and that this bound is sharp.
Thus, a power series expansion of the quantum Fourier kernel can be written in the form
where the coefficients satisfy This complicated-looking expression is actually quite meaningful. For any vector , the normalized power sum polynomial of degree in the coordinates of is
where
is the discrete probability measure on which places equal mass at each coordinate of This is called the empirical distribution of Thus, the expansion of the quantum Fourier kernel is a generating function for the moments of the empirical distributions of its arguments. Consequently, for a random vector, the quantum characteristic function is a generating function for expectations of polynomials in the random variables
which are the moments of the (random) empirical distribution of the random vector
Let be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product
Let
be the function from Hermitian matrices to standard Euclidean space defined by
Theorem 5.1 (Hoffman-Wielandt Inequality). For any we have
Proof: By the spectral theorem, there are unitary matrices and non-increasing vectors such that
The square of the Hilbert-Schmidt norm of the difference is
and
Therefore, if we can show
holds for all we will have proved the claimed inequality (make sure you understand why).
Now,
and is a doubly stochastic matrix. Therefore, the maximum value of over all is bounded by the maximum value of the function
as ranges over all doubly stochastic matrices. Since is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives
and since the coordinates of and are nonincreasing the identity permutation is the optimal matching.
– QED
Now let be a random Hermitian matrix.
Theorem 5.2. The following are equivalent:
The characteristic function of is invariant under unitary conjugation;
The distribution of is invariant under unitary conjugation;
is equal in distribution to a random Hermitian matrix of the form where is a uniformly random unitary matrix and is a random real diagonal matrix independent of .
We have already proved the equivalence of (1) and (2).
Problem 5.2. Complete the proof of Theorem 5.1.
At this point we have enough information to explain how the characteristic function of a unitarily invariant random Hermitian determines the joint distribution of its eigenvalues.
Theorem 5.2. The characteristic function of a unitarily invariant random Hermitian matrix is equal to the quantum characteristic function of its eigenvalues.
Obviously, this statement needs to be explained.
Let be a real random vector whose distribution in is arbitrary, and let be an independent random unitary matrix whose distribution in is uniform (Haar) measure. Then is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.
Because is non-compact, there is no such thing as a uniformly random Hermitian matrix. The matrix is as close as we can get: it is uniform conditional on the distribution of its eigenvalues If is the distribution of in , a random sample from is obtained by sampling a vector from the distribution on and then choosing a uniformly random point on the -orbit in which contains this vector.
In terms of characteristic functions, this says that
where
is the characteristic function of a uniformly random Hermitian matrix from the orbit containing viewed as a diagonal matrix. Thus, is the characteristic function of a uniformly random Hermitian matrix with prescribed eigenvalues. This defines a bounded symmetric kernel
which we call the quantum Fourier kernel, because it is a superposition of standard -dimensional Fourier kernels
Problem 5.3. Prove that indeed and Moreover, show that is invariant under independent permutations of the coordinates of
If is the quantum Fourier kernel, then
deserves to be called the quantum characteristic function of random vector , or the quantum Fourier transform of the probability measure What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix we have
where is any -dimensional random vector whose components are eigenvalues of (this is what Theorem 5.2 means). We can also state the above as
where is the diagonal of the random matrix .
The conclusion to be drawn from all of this is that figuring out how to analyze the eigenvalues of a unitarily invariant random Hermitian matrix given its characteristic function is exactly the same thing as figuring out how to analyze an arbitrary random real vector given its quantum characteristic function
Before telling you how we will do this, let me tell you how we won’t. The main reason the Hoffman-Weilandt theorem was presented in this lecture is that the proof makes you think about maximizing the function
over unitary matrices The action is exactly what appears in the exponent of the quantum Fourier kernel:
(I am going to stop writing the Haar measure explicitly in Haar integrals, so just rather than ). Now, the method of stationary phase predicts that should be approximated by contributions from the local maxima of the action, which means that this integral should localize to a sum over permutations. This turns out to be exactly correct, not just a good approximation, and the reasons for this are rooted in symplectic geometry. The end result is the following determinantal formula for the quantum Fourier kernel.
Theorem 5.4 (HCIZ Formula). For any with no repeated coordinates we have
This is a very interesting formula which makes manifest all the symmetries of the quantum Fourier kernel claimed in Problem 5.3 (but, you should solve that problem without using the determinantal formula). It is also psychologically satisfying in that it shows exactly how the quantum Fourier kernel is built out of classical one-dimensional Fourier kernels. However, it is not really good for much else. We will explain this further in the coming lectures. But first we will adapt all of the above to random rectangular matrices.
Let be a Hilbert space of dimension and be the algebra of all linear operators As we saw in Lecture 14, the trace on is, up to scaling, the unique linear functional such that Thus, the only linear functional satisfying and is
This fact allows us to prove a fact claimed early on in the course.
Problem 15.1. Prove that there does not exist an algebra homomorphism
The fact that admits not even a single homomorphism to indicates that this is an algebra with the highest degree of noncommutativity. According to our definitions in Week One, the degree of noncommutativity of an algebra is formalized as the dimension of its center. We now prove that the center of is indeed one-dimensional. The key notion is the following.
Definition 15.1. Given a subalgebra of , a subspace of is said to be –invariant if for every and every we have
Every subalgebra of has at least two invariant subspaces, namely the zero space and the total space An important theorem of Burnside characterizes subalgebras of for which this minimum is achieved.
Theorem 15.1. (Burnside) A subalgebra of has exactly two invariant subspaces if and only if
Proof: An elementary proof of Burnside’s theorem by induction in the dimension of can be found here.
-QED
Corollary 15.2. A proper subalgebra of has at least four invariant subspaces.
Proof: The zero space and the total space are -invariant, and since there is a third -invariant subspace by Burnside’s theorem. The orthogonal complement of is again a nonzero proper subspace of and we claim it is -invariant. Indeed, let and Then, for any we have
where we used the fact that is -invariant. This shows i.e. is -invariant.
– QED
Using Burnside’s theorem we can characterize the center of .
Theorem 15.2. The center of is the set of scalar operators.
Proof: Let be a central element, and let be an eigenvalue of Then, the -eigenspace of is an -invariant subspace, since if is an eigenvector of corresponding to and is any operator we have
which shows that is again in the -eigenspace of Since this eigenspace is not the zero space, Burnside’s theorem forces it to be all of i.e.
-QED
We have succeeded in describing the center of explicitly, and ideally we would like to have an explicit description of all subalgebras of We were able to do this for function algebras where subalgebras are indexed by partitions of the finite set . The classification is very simple: the subalgebra of a given partition of is the set of all functions on which are constant on the blocks of A nice feature of this classification is that it shows every subalgebra of is itself isomorphic to a function algebra, because is isomorphic to
We can attempt to classify subalgebras of by adapting our approach to the classification of subalgebras of The first step is to formulate the vector space version of partitions of a set.
Definition 15.2. A linear partition of is a set of nonzero subspaces of whose union spans We refer to the subspaces as the blocks of
Given a linear partition of it is not useful to consider the set of linear operators in constant on the blocks of Indeed, there is only one such operator, namely the zero operator. Rather, we define to be the set of all operators such that every block is -invariant.
Problem 15.2. Prove that is a subalgebra of
Here our construction starts to diverge from what we saw in the setting of function algebras: unless is the linear partition of consisting of a single block, in which case the subalgebra is definitely not isomorphic to the algebra of all linear operators on a Hilbert space. Indeed, consider the case where is a linear partition of with two blocks. Let be an ordered basis of and let be an ordered basis of Then is an ordered basis of , and consists of all operators in whose matrix relative to this ordered basis has the form
with and Thus, is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,
The question now is whether the above can reversed: given a subalgebra of does there exist a linear partition such that ? If the answer is clearly “yes” since we have Thus we consider the case where is a proper subalgebra of Our starting point is Burnside’s theorem, which guarantees the existence of an -invariant subspace . Together with the corollary to Burnside’s theorem, we thus have a linear partition of whose blocks are -invariant. We now ask whether has a proper non-trivial subspace invariant under . If it does we can split it into the orthogonal direct sum of two smaller -invariant subspaces; if not is said to be -irreducible. Continuing this process, for both and , we get the following.
Theorem 15.4. (Maschke’s theorem) There exists a linear partition of whose blocks are -invariant and -irreducible subspaces.
Now consider the linear partition of into -invariant, -irreducible subspaces we have constructed. It is tempting to hope that This is almost correct. Let us say that two blocks are –equivalent if it is possible to choose a basis in and a basis in such that the matrix of every , viewed as an operator on , coincides with the matrix of viewed as an operator on . This is an equivalence relation on the blocks of Let be a set parameterizing the corresponding equivalence classes of blocks, and for each choose a representative of the corresponding equivalence class.
Theorem 15.5. (Classification Theorem for subalgebras of linear algebras) The subalgebra is isomorphic to
We are not going to prove the above classification in full right now – in the coming lectures we will prove a special case of it for homomorphic images of convolution algebras of finite groups. If time permits, we will prove the full theorem later.
Let be the convolution algebra of a finite group Then, the left regular representation
is an injective algebra homomorphism from the convolution algebra into the the linear algebra of viewed as a Hilbert space. That is, the regular representation converts convolution of functions into matrix multiplication.
If is abelian, then the Fourier transform
is an algebra isomorphism between the convolution algebra and the function algebra of the dual group of That is, the Fourier transform converts convolution into pointwise multiplication.
Let us reconcile these two points of view on the convolution algebra of a finite abelian group. Let be any function on Let
be the Fourier expansion of Taking the left regular representation, we have
where is the linear operator on the Hilbert space given by the image of the Fourier basis vector under the injective algebra homomorphism In other words,
is a basis of orthogonal projections for the image of in under and
is the spectral decomposition of the operator This says that the operators making up the image of the commutative algebra in are simultaneously diagonalizable, which we already knew from our characterization of commutative subalgebras of and moreover that calculating the eigenvalues of the operator is the same thing as calculating the Fourier transform of the function
Problem 12.3. A circulant matrix is a complex square matrix of the form
Determine the eigenvalues and eigenvectors of Hint: show that every circulant matrix is the image of a function on the cyclic group of order in the regular representation.
As an extension to the above problem, you may consider how the uncertainty principle for the Fourier transform relates the sparsity of a circulant matrix to the dimension of its kernel. (Note to self: perhaps do this in Lecture in the next iteration of Math 202B).
be its dual group. In Lecture 8 we showed that the convolution algebra admits a basis consisting of orthogonal projections, called its Fourier basis. Thus any function can be expanded in the group basis,
and in the Fourier basis
The coefficients of the Fourier expansion of give a function defined by
Definition 9.1. The Fourier transform on is the map defined by
In Lecture 3, we proved that any algebra which admits a basis of orthogonal projections is isomorphic to a function algebra, and the proof of this general fact given there applies here in particular, allowing us to conclude that the Fourier transform is an algebra isomorphism Thus, we have
where on the left hand side
is the convolution product of two functions in and on the right hand side
is the pointwise product of two functions in
By definition, the elements of the Fourier basis of are
where is the character basis of , which consists of all group homomorphisms
Theorem 9.1. For any we have
where the right hand side is an -scalar product in
Proof: Taking a slightly different normalization of the Fourier basis, we get an orthonormal basis of consisting of the functions
Because this basis is orthonormal, we have
for any function and comparing with the Fourier expansion of this gives
-QED
Theorem 9.1 is called the Fourier inversion formula, because
recovers the values of the transformed function in terms of the values of the original function As an example, let us calculate the Fourier transform of the elementary function corresponding to a given group element From the inversion formula, the Fourier transform of the indicator function of is
Equivalently, we have
where is the elementary basis of consisting of indicator functions
Theorem 9.2. (Plancherel and Parseval formulas) For any we have
and
Proof: From the definition of the Fourier transform, we have
This is the Plancherel formula, and the Parseval formula is the special case where together with the definition of the norm associated to a scalar product.
-QED
The -norm on functions the case of the -norm, which for any is defined by
Also familiar from analysis is the case , which is defined by
The intuition behind this definition is that, as the sum is approximately equal to its largest term, and this concentration becomes exact in the limit. This intuition leads to the following inequality.
Proposition 11.3. For any and , we have
where by definition the support of is the cardinality of the complement of its vanishing set,
Problem 11.2. Prove Proposition 11.3.
We now prove a discrete version of the famous uncertainty principle, whose origins are in quantum mechanics; in Fourier analysis, this principle effectively says that if the support of a function is small than the support of its Fourier transform is large.
Theorem 11.4. (Uncertainty principle) For any nonzero function we have
Proof: Start from the Fourier expansion of which in terms of the character basis of is
For any we have
where we used the triangle inequality and the fact that Since was arbitrary, the above shows that
Squaring both sides, we thus have
where we applied the Cauchy-Schwarz inequality, the Parseval formula, and Proposition 11.3. Since it can be cancelled from both sides of the above inequality, leaving
-QED
Problem 11.3. Prove that the uncertainty principle is sharp by exhibiting a function for which equality holds in Theorem 11.4.
The convolution and class algebras and of a group are apparently quite different from the other types of algebras we have seen, namely function algebras and linear algebras However, they are in fact closely related.
Theorem 9.1. The convolution algebra is isomorphic to a subalgebra of a linear algebra.
Proof: Since has a natural scalar product, the -scalar product
it is a Hilbert space as well as an algebra. For each , consider the function defined by
Observe that is a linear operator on i.e.
Thus, is a function from the convolution algebra to the linear algebra Moreover, the map itself is a linear transformation, i.e.
We claim that is an injective linear transformation. Since is a linear transformation of , it is completely determined by its action on the group basis of . Thus, it suffices to show that the linear operators and on are distinct unless Since and are linear operators on they are uniquely determined by their actions on the group basis of . We have
hence
From this we can conclude that the image of in under is a subspace isomorphic to . It remains to show that is not just a linear transformation, but an algebra homomorphism, and we leave this as an exercise (that you really should do).
-QED
The proof of Theorem 8.1 is the linear version of Cayley’s theorem from group theory: instead of representing as a subgroup of the group of permutations of it represents as a subalgebra of the algebra of linear operators on This is called the left regular representation of
Corollary 9.2. The class algebra is isomorphic to a function algebra.
Proof: Since is a subalgebra of , and since is isomorphic to a subalgebra of a linear algebra, is isomorphic to a subalgebra of a linear algebra. Thus, is isomorphic to a commutative subgalgebra of a linear algebra, and we have previously shown that all commutative subalgebras of linear algebras are isomorphic to function algebras.
-QED
For an example illustrating how the proof of Theorem 8.1 works, let us take to be a cyclic group of order four with generator , so that is the group unit. The group basis of is thus and we denote these vectors by for brevity. Let be any function on and let
be its expansion in the group basis, so that
Problem 9.1. Show by direct calculation that the matrix of with respect to the ordered basis of is
In the case where is an abelian group, as in the example above, we have that . Moreover, it is possible to establish Corollary 8.1 directly, without appealing to Theorem 8.1. This is done constructively, by finding an explicit basis of orthogonal projections in the commutative convolution algebra called its Fourier basis. The advantage of this direct approach is that it also gives us an explicit description of the spectrum of all matrices in the left regular representation of This is very useful in applications – in particular, matrices in the left regular representation of a cyclical group are called circulant matrices and they are important in engineering.
To see begin to see where a projection basis of might come from, recall that we previously showed the non-existence of an algebra homomorphism for a Hilbert space of dimension at least two. This reflects the fact that linear algebras are maximally noncommuative. But we have also seen that for a group with at least two elements, the dimension of is at least two, so convolution algebras are always at least one degree more commutative than linear algebras, and therefore might admit homomorphisms to the complex numbers.
Theorem 9.3. A linear transformation is an algebra homomorphism if and only if the function defined by
is a group homomorphism taking values in the unitary group of the complex numbers.
Problem 9.2. Prove Theorem 8.3.
Definition 9.1. A group homomorphism is called a character of The set of all characters of is denoted .
Observe first of all that is a set of functions on is a subset of the space of all -valued functions on It is this special subset of functions tethered to the group law in that we look to for orthogonal projections. No matter what the group is, the set is nonempty: it contains at least the trivial character defined by However, for highly noncommutative groups there may not be many nontrivial characters.
Problem 9.3. Determine the Fourier dual of the symmetric group
For abelian groups the situation is much better and in fact we always have To begin, recall that every finite abelian group is isomorphic to a product of cyclic groups. We thus fix a positive integer and positive integers and consider the group
where is a cyclic group of order with generator Define the dual group of to be
That is,
where is the additive group of integers modulo . We can parameterize by the points of writing
Indeed, the parameterization is a group isomorphism (Exercise: prove this, noting that because it is sufficient to show the parameterization is an injective group homomorphism).
Theorem 9.4. For every the function defined by
where is a principal th root of unity, is a character of and every character of is of this form.
Proof: For any it is clear that because the identity element has parameters Moreover, for any we have
so is indeed a group homomorphism The fact that every homomorphism is for some is left as an exercise.
-QED
We now have a special subset of the convolution algebra of the finite abelian group , namely the set of all homomorphisms to the unitary group We now claim that the characters form a basis of Since the number of characters is which is the dimension of , it is sufficient to show that is a linearly independent set in
Theorem 9.5. The set is orthogonal with respect to the -scalar product on – we have
Proof: For any we have
where
Thus if we have
and if we have
where the denominator of each fraction is nonzero and the numerator is zero, because is an th root of unity.
-QED
The orthogonal basis of is called its character basis. It is convenient to write since this highlights the symmetry The symmetric matrix is called the character table of and Theorem 8.3 says that is a symmetric unitary matrix. Another way to say the same thing is that the rescaled character basis
is an orthonormal basis of the convolution algebra In fact, the further scaling
is even better, for the following reason.
Theorem 9.6. The elements of the basis are orthogonal projections in
Proof: For any we have
For any we have
The internal sum is
where the final equality is Theorem 8.3. Thus
-QED
Since we know that any algebra with a basis of orthogonal projections is isomorphic to the function algebra (Lecture 3), Theorem 8.4 gives the promised second proof of the fact that the convolution algebra of an abelian group is isomorphic to a function algebra. In this particular case, the basis is known as the Fourier basis of
The convolution algebra of a group is commutative if and only if is abelian. As in Lecture 2, we will refine this dichotomy by giving a quantitative measurement of how (non)commutative is. In Lecture 2 we defined the commutativity index of an algebra to be the dimension of its center, so our goal now is to determine the dimension of the center of a convolution algebra.
The degree of non commutativity of is determined by that of , and in group theory we understand this using the action of on itself defined by
The orbits of this action are the conjugacy classes of , and the number of conjugacy classes in is called its class number. The higher the class number, the more commutative the group – for abelian groups, conjugacy classes are singleton sets.
Problem 8.1. Prove that is an abelian group if and only if its class number is equal to its cardinality, and more generally that the number of commuting pairs of elements in is equal to the cardinality of times its class number (hint: the orbit-stabilizer theorem may be helpful). Show also that every group except the trivial group contains at least two conjugacy classes.
For the function algebra , every partition of gives rise to a subalgebra of , namely the set of functions constant on the blocks of the partition. As we discussed in Lecture 4, there is no reason that the convolution of two such functions will still be constant on the blocks of the given partition. On the other hand, the partition of into conjugacy classes is determined by the group structure of , and so functions on which are constant on the blocks of this particular group-theoretic partition of are relevant from the point of view of
Definition 8.2. A function is called a class function if it is constant on conjugacy classes, meaning that for all
The following gives an alternative way to think about class functions as functions which are insensitive to any noncommutativity present in .
Theorem 8.1. A function is a class function if and only if for all
Proof: Suppose first that is a class function on . Then,
Conversely, suppose is insensitive to noncommutativity. Then,
-QED
We can now characterize the center of .
Theorem 8.2. A function belongs to if and only if it is constant on conjugacy classes.
Proof: Suppose first that is a class function; we will prove that it commutes with every For any , we have
where the second inequality follows from the fact that the substitution simply permutes the terms of the sum. Continuing the calculation, we have
where the second inequality follows from the fact that is a class function. We now conclude
as required.
Now suppose that is a central function; we will prove it is constant on conjugacy classes. Since commutes with all functions in it commutes with every elementary function . Since
and
the centrality of implies that for all . Thus is a class function, by Theorem 5.1.
-QED
Thus, the set of all functions constant on conjugacy classes of is a subalgebra of both and . The subalgebra of class functions has no special significance in , not being any more or less special than the subalgebra associated with any other partition of . But in , the subalgebra of class functions is the center of . The center of is often called the class algebra of and denoted rather than to emphasize that it is worth thinking about as a standalone object, i.e. as a commutative algebra naturally associated to the finite group .
Just as the convolution algebra has a natural basis given by indicator functions of elements of the class algebra has a natural basis given by indicator functions of conjugacy classes in Let be a set parameterizing the conjugacy classes of so the collection of these is
and this is a subset of the power set of For each let be the indicator function of so
Equivalently, in terms of the group basis of we have
Then, the functions span the class algebra of since any function constant on conjugacy classes can be written
where denotes the value for any We will show that is a basis of using the -scalar product on which is
It is clear that is an orthonormal basis of with respect to the -scalar product, and we therefore have
Since is a partition of , the scalar product is
which shows that is an orthogonal (but not orthonormal) set of functions in , hence linearly independent.
In conclusion, if is any finite group, the dimension of the convolution algebra is the cardinality of , and the dimension of the class algebra is the class number of .
Problem 8.3. Consider the multiplication tensor of i.e. For any and any , show that
Thus, the multiplication tensor of is quite an interesting object: counts solutions to the equation in , where is any particular point of the conjugacy class and are required to belong to and respectively.
Definition 3.1. A basis of orthogonal projections in is said to be a Fourier basis of
Let be a finite nonempty set.
Definition 3.2. The function algebra of is the vector space
of -valued functions on with multiplication defined by
and conjugation defined by
One says that the operations in are defined pointwise.
Problem 3.1. Prove that is indeed an algebra.
There is a natural Fourier basis in indexed by the points of For each define the corresponding elementary function by
That is, where is the Kronecker delta. The elementary functions are selfadjoint elements of because they are real-valued, and they are orthogonal projections because
Thus, is a linearly independent set in by Theorem 1.1 in Lecture 1. To see that spans , observe that any function can be written as
Using the elementary basis of , we can forget that the elements of this algebra are functions on and view them as linear combinations
Combining the fact that the elementary functions are orthogonal projections with the axioms of bilinearity and antilinearity, we recover multiplication and conjugation in in the form
and
Two sets and are said to be isomorphic if there exists a bijection between them.
Problem 3.1. Prove that two finite nonempty sets and are isomorphic if and only if their function algebras and are isomorphic.
Theorem 3.1. An algebra admits a Fourier basis if and only if it is isomorphic to a function algebra.
Proof: We have already shown that a function algebra has a Fourier basis. Conversely, let be an algebra, and let be a vector space basis of indexed by the points of a finite set whose cardinality is the dimension of Let be the function algebra of this set, and define a linear transformation
by , where is the elementary function corresponding to . This is a vector space isomorphism, since it maps a basis of onto a basis of . If is a basis of orthogonal projections in , then is also an algebra homomorphism. Indeed, by Theorem 1.2 and linearity of we have
so maps the multiplicative unit of to that of Next,
so respects multiplication. Finally,
-QED
Theorem 3.1 is simple but important and you should go over its proof carefully. The argument shows that if is a Fourier basis of then the linear transformation
defined by
is an algebra isomorphism. This isomorphism is called the Fourier transform on , and it is generally denoted as rather than Thus,
and the argument above shows that the linear isomorphism so defined is an algebra isomorphism. Note that the Fourier transform on is not canonical – it is defined in terms of a specified basis of orthogonal projections in For any element , its expansion in the Fourier basis is written
and the coefficients in this expansion are called the Fourier coefficients of We thus have
which is the elementary expansion of a function The function is called the Fourier transform of the algebra element The practical value of the Fourier transform lies in the fact that
where is the product of , which might be convoluted and difficult to calculate. On the other hand, the pointwise product of the corresponding functions is very simple, both conceptually and computationally.
In this lecture we move beyond the commutative vs noncommutative dichotomy and quantify the degree of (non)commutativity of a given algebra . This is done using the notion of a subalgebra.
Definition 2.1. A subspace of is called a subalgebra if it contains and is closed under multiplication and conjugation.
Being a subalgebra is a stronger condition than being a subspace. In particular, the zero subspace of is not a subalgebra because it does not contain . Indeed, every subalgebra of must contain the one-dimensional subspace
of scalar multiples of , which is a commutative subalgebra of isomorphic to . In this sense, is the smallest subalgebra of , and not only is it commutative but its elements commute with all elements in . We can consider the set of all elements which have the “commute with everything” property.
Definition 2.2. The center of is the set
Elements of are called central elements.
The use of the letter “Z” here comes from the German word for “center,” which is “zentrum.” Don’t forget to take your zentrum.
Theorem 2.1. The center is a subalgebra of
Proof: We have to check that the conditions stipulated by Definition 2.1 hold for – it would be bad if the center did not hold. The argument is straightforward but also worth spelling out in detail, since all the defining features of an algebra (Definition 1.1) are used.
First we need to verify that is a vector subspace of i.e. that it is closed under linear combinations. Let be any two central elements and be any element. For any two scalars , we have
Now we check that is closed under multiplication:
Now we check that is closed under conjugation:
Finally, it is clear that .
-QED
We can now quantify commutativity.
Definition 2.3. The commutativity index of is the dimension of
The commutativity index of is a positive integer between (minimally commutative, maximally noncommutative) and (maximally commutative, minimally noncommutative). Any algebra whose commutativity index is less than is called noncommutative, which is a bit misleading because every algebra contains (uncountably) many elements which commute with one another. Algebras with one-dimensional center have the lowest commutativity index; such maximally noncommutative algebras are called central-simple algebras.
We now generalize the center of an algebra as follows.
Definition 2.4. Given a subalgebra of , its centralizer is the set of all elements in which commute with every element of :
The symbol is read as “the centralizer of in .’’ In particular, the centralizer of in is .
Problem 2.1. Prove that is indeed a subalgebra of . Moreover, show that if are subalgebras of with then
Problem 2.1 suggests a way to organize the set of all subalgebras of a given algebra We know that this is a nonempty set, whose “smallest” element is and whose “largest” element is itself — we want to order everything in between.
Defintion 2.3. Given a set , a relation on is a subset of
In the context of relations, instead of ordered pairs of elements it is standard to write to denote the membership of in For example, you are familiar with the notion of an equivalence relation on a set , which is a relation written with the following properties :
Reflexivity: for all ;
Symmetry: iff ;
Transitivity: if and then .
There is a different relation which formalizes order in the same way as the above formalizes equivalence.
Defintion 2.3. A partial order on is a relation with the following properties:
Reflexivity: for all ;
Antisymmetry: if and then ;
Transitivity: if and then .
A pair consisting of a set together with a partial order on it is called a partially ordered set, or “poset.” The symbol by definition means . Importantly, note the use of the adjective “partial” – Definition 2.3 allows for the possibility that there are pairs of elements for which neither nor holds true, i.e. are incomparable. The axiomatic study of partially ordered sets is a branch of algebra called order theory.
A very basic example of a partial order is obtained by taking any set and defining a partial order on the power set by inclusion:
For example, if , then consists of the subsets of ordered as in the following Hasse diagram:
The poset of subsets of an arbitrary set has an additional attribute: every pair of subsets has a minimum and a maximum. More precisely, if we define
then is the largest subset of contained in both and
and is the smallest subset of containing both and
A partially ordered set in which we have such a notion of greatest lower bound (min) and least upper bound (max) is called a lattice, and the power set of subsets of an arbitrary set partially ordered by inclusion is such an object. Moreover, this lattice has a unique smallest element: the empty set is the only subset of satisfying for all . Similarly, the whole set is the only set satisfying for all other , making it the unique largest element of .
We now want to use the partial order concept to organize the subalgebgras of a given algebra . Starting very simply, we could forget the structure of entirely and just view it as a set, which would result in the construction above with the power set of . Of course, since is a not a finite set is uncountably infinite.
Now let us remember the vector space structure on and accordingly take to be the set of all vector subspaces of , partially ordered by inclusion, so is an induced subposet of . If we want to make into a lattice we can still use the set-theoretic definition of as intersection, because the intersection of two subspaces is again a subspace. However, the union of two subspaces is not, and we have to modify the definition to
This makes into a lattice with largest element and smallest element the zero subspace , as the empty subset of is not a vector space.
Now let us remember the algebra structure on and declare to be the set of all subalgebras of partially ordered by inclusion. Then is an induced subposet of , and once again taking to be intersection gives us a greatest lower bound operation.
Problem 2.2. Show that the intersection of any nonempty set of subalgebras of is a subalgebra. Show moreover that if all members of the family are commutative, so is their intersection.
However, our notion of least upper bound must be modified in order to make into a lattice, because the span of the union of two subalgebras of is a subspace but not necessarily a subalgebra.
Definition 2.4. For any subset , define to be the intersection of all subalgebras of containing . This is called the subalgebra generated by . It contains all scalar products, sums, products, and conjugates of elements of , and is the smallest subset of containing all of these elements.
Note that the set of subalgebras containing is always nonempty, since it contains the whole algebra , and consequently Problem 2.1 legitimizes Definition 2.4 and allows us to define the least upper bound of a pair of subalgebras by
This makes into a lattice, the lattice of subalgebras of . The maximal element of this lattice is still , and its minimal element is , since the zero space is not a subalgebra.
Finally, let be the set of all commutative subalgebras of , partially ordered by inclusion, an induced subposet of the lattice of algebras of To latticize this we can keep the same greatest lower bound operation, but must modify least upper bound to
where the right hand should be the intersection of all commutative subalgebras of the ambient algebra which contain the set This definition will fail if one of or is not contained in any larger commutative subalgebra of
Definition 2.5. A maximal abelian subalgebra (MASA) of is a commutative subalgebra with the following property: if is a commutative subalgebra with , then .
Note that “abelian” is a synonym for “commutative” and the two are used interchangeably.
Problem 2.3. Prove that any two distinct MASAs are incomparable.
MASAs can be characterized using centralizers.
Theorem 2.2. An abelian subalgebra of an algebra is a MASA if and only if it is its own centralizer:
Proof: Suppose first that is a MASA. Since is abelian we have . If is a proper subset of its centralizer, then there exists such that In this case, the algebra generated by is a commutative subalgebra of properly containing and this contradicts the maximality of
Conversely, suppose is an abelian subalgebra of such that Then for a commutative subalgebra we have
so we also have (note that the conclusion of Problem 2.1 was used here) .



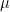


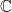


![\mathbf{E}F(a,X) = 1 + \sum_{d=1}^\infty \frac{i^d}{d!} a^d\mathbf{E}[X^d],](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7DF%28a%2CX%29+%3D+1+%2B+%5Csum_%7Bd%3D1%7D%5E%5Cinfty+%5Cfrac%7Bi%5Ed%7D%7Bd%21%7D+a%5Ed%5Cmathbf%7BE%7D%5BX%5Ed%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![\mathbf{E}[X^d] = \int\limits_{\mathbb{R}} x^d \mu(\mathrm{d}x)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5BX%5Ed%5D+%3D+%5Cint%5Climits_%7B%5Cmathbb%7BR%7D%7D+x%5Ed+%5Cmu%28%5Cmathrm%7Bd%7Dx%29&bg=FFFFFF&fg=000&s=0&c=20201002)
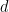

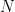





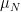











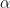
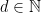





![\mathbf{E}F_N^d(A,X_N) = \sum\limits_{\alpha \in \mathsf{C}_N^d} a_1^{\alpha_1} \dots a_N^{\alpha_N} \mathbf{E}[X^{\alpha_1}_N(1)\dots X^{\alpha_N}_N(N)]F_N(\alpha).](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7DF_N%5Ed%28A%2CX_N%29+%3D+%5Csum%5Climits_%7B%5Calpha+%5Cin+%5Cmathsf%7BC%7D_N%5Ed%7D+a_1%5E%7B%5Calpha_1%7D+%5Cdots+a_N%5E%7B%5Calpha_N%7D+%5Cmathbf%7BE%7D%5BX%5E%7B%5Calpha_1%7D_N%281%29%5Cdots+X%5E%7B%5Calpha_N%7D_N%28N%29%5DF_N%28%5Calpha%29.&bg=FFFFFF&fg=000&s=0&c=20201002)





![U=[U_{xy}]](https://s0.wp.com/latex.php?latex=U%3D%5BU_%7Bxy%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002)









































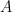


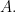




 be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product
be the real vector space of Hermitian matrices with the Hilbert-Schmidt scalar product


 we have
we have
 and non-increasing vectors
and non-increasing vectors 
 is
is


 we will have proved the claimed inequality (make sure you understand why).
we will have proved the claimed inequality (make sure you understand why).
![[|U_{ij}|^2]](https://s0.wp.com/latex.php?latex=%5B%7CU_%7Bij%7D%7C%5E2%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is a doubly stochastic matrix. Therefore, the maximum value of
is a doubly stochastic matrix. Therefore, the maximum value of  over all
over all 
 ranges over all doubly stochastic matrices. Since
ranges over all doubly stochastic matrices. Since  is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives
is a linear function on the Birkhoff polytope, it achieves its maximum value at an extreme point of this convex set, so at a permutation matrix. The vertex corresponding to the identity matrix gives
 are nonincreasing the identity permutation is the optimal matching.
are nonincreasing the identity permutation is the optimal matching. where
where  is a uniformly random unitary matrix and
is a uniformly random unitary matrix and  in
in  is uniform (Haar) measure. Then
is uniform (Haar) measure. Then  is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.
is a unitarily invariant random Hermitian matrix, and by Theorem 5.2 every unitarily invariant random Hermitian matrix is equal in law to a matrix constructed in this way.  is as close as we can get: it is uniform conditional on the distribution of its eigenvalues
is as close as we can get: it is uniform conditional on the distribution of its eigenvalues ![\varphi_{X_N}(A) = \mathbf{E}_{\mu_N}\left[e^{i \mathrm{Tr} AU_NB_NU_N^*}\right] = \mathbf{E}_{\sigma_N} \left[K_N(A,B_N)\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D_%7B%5Cmu_N%7D%5Cleft%5Be%5E%7Bi+%5Cmathrm%7BTr%7D+AU_NB_NU_N%5E%2A%7D%5Cright%5D+%3D+%5Cmathbf%7BE%7D_%7B%5Csigma_N%7D+%5Cleft%5BK_N%28A%2CB_N%29%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![K_N(A,B) = \mathbf{E}_{\eta_N}\left[e^{i\mathrm{Tr}\, AUBU^*}\right] = \int_{\mathbb{U}_N} e^{i \mathrm{Tr}\, AUBU^*} \eta_N(\mathrm{d}U)](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cmathbf%7BE%7D_%7B%5Ceta_N%7D%5Cleft%5Be%5E%7Bi%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D%5Cright%5D+%3D+%5Cint_%7B%5Cmathbb%7BU%7D_N%7D+e%5E%7Bi+%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D+%5Ceta_N%28%5Cmathrm%7Bd%7DU%29&bg=FFFFFF&fg=000&s=0&c=20201002)

 Moreover, show that
Moreover, show that ![\psi_{B_N}(A) = \mathbf{E}[K_N(A,B_N)] = \int_{\mathbb{R}^N} K_N(A,B) \sigma_N(\mathrm{d}B)](https://s0.wp.com/latex.php?latex=%5Cpsi_%7BB_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D%5BK_N%28A%2CB_N%29%5D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%5EN%7D+K_N%28A%2CB%29+%5Csigma_N%28%5Cmathrm%7Bd%7DB%29&bg=FFFFFF&fg=000&s=0&c=20201002)
 What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix
What we have shown in this lecture is that for any unitarily invariant random Hermitian matrix  we have
we have

 is the diagonal of the random matrix
is the diagonal of the random matrix 

 The
The  is exactly what appears in the exponent of the quantum Fourier kernel:
is exactly what appears in the exponent of the quantum Fourier kernel:
 rather than
rather than  ). Now, the
). Now, the ![K_N(A,B) = \frac{1!2! \dots (N-1)!}{i^{N \choose 2}}\frac{\det [ e^{ia_xb_y}]}{\det[a_x^{N-y}]\det[b_x^{N-y}]}.](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cfrac%7B1%212%21+%5Cdots+%28N-1%29%21%7D%7Bi%5E%7BN+%5Cchoose+2%7D%7D%5Cfrac%7B%5Cdet+%5B+e%5E%7Bia_xb_y%7D%5D%7D%7B%5Cdet%5Ba_x%5E%7BN-y%7D%5D%5Cdet%5Bb_x%5E%7BN-y%7D%5D%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
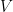 be a Hilbert space of dimension
be a Hilbert space of dimension  and
and  be the algebra of all linear operators
be the algebra of all linear operators  As we saw in Lecture 14, the trace on
As we saw in Lecture 14, the trace on  such that
such that  Thus, the only linear functional satisfying
Thus, the only linear functional satisfying  and
and  is
is

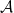 of
of  of
of  and every
and every  we have
we have 
 and the total space
and the total space  An important theorem of Burnside characterizes subalgebras of
An important theorem of Burnside characterizes subalgebras of 
 there is a third
there is a third  by Burnside’s theorem. The orthogonal complement
by Burnside’s theorem. The orthogonal complement  of
of  and we claim it is
and we claim it is  and
and  Then, for any
Then, for any 
 i.e.
i.e.  of scalar operators.
of scalar operators.  be a central element, and let
be a central element, and let  be an eigenvalue of
be an eigenvalue of  Then, the
Then, the  -eigenspace of
-eigenspace of 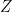 is an
is an  is an eigenvector of
is an eigenvector of  is any operator we have
is any operator we have
 is again in the
is again in the 
 We were able to do this for function algebras
We were able to do this for function algebras  where subalgebras are indexed by partitions
where subalgebras are indexed by partitions  of the finite set
of the finite set  of a given partition
of a given partition  A nice feature of this classification is that it shows every subalgebra of
A nice feature of this classification is that it shows every subalgebra of  is itself isomorphic to a function algebra, because
is itself isomorphic to a function algebra, because 
 The first step is to formulate the vector space version of partitions of a set.
The first step is to formulate the vector space version of partitions of a set. of nonzero subspaces of
of nonzero subspaces of  as the blocks of
as the blocks of 
 to be the set of all operators
to be the set of all operators  is a subalgebra of
is a subalgebra of  is the linear partition of
is the linear partition of  the subalgebra
the subalgebra  is a linear partition of
is a linear partition of  be an ordered basis of
be an ordered basis of  and let
and let  be an ordered basis of
be an ordered basis of  Then
Then  is an ordered basis of
is an ordered basis of  whose matrix relative to this ordered basis has the form
whose matrix relative to this ordered basis has the form ![[A]_{(e_1,\dots,e_m,f_1,\dots,f_n)}=\begin{bmatrix} M_1 & {} \\ {} & M_2 \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5BA%5D_%7B%28e_1%2C%5Cdots%2Ce_m%2Cf_1%2C%5Cdots%2Cf_n%29%7D%3D%5Cbegin%7Bbmatrix%7D+M_1+%26+%7B%7D+%5C%5C+%7B%7D+%26+M_2+%5Cend%7Bbmatrix%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 and
and  Thus,
Thus,  is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,
is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,
 does there exist a linear partition
does there exist a linear partition  ? If
? If  the answer is clearly “yes” since we have
the answer is clearly “yes” since we have  Thus we consider the case where
Thus we consider the case where  . Together with the corollary to Burnside’s theorem, we thus have a linear partition
. Together with the corollary to Burnside’s theorem, we thus have a linear partition  of
of  This is almost correct. Let us say that two blocks
This is almost correct. Let us say that two blocks  are
are  such that the matrix of every
such that the matrix of every  be a set parameterizing the corresponding equivalence classes of blocks, and for each
be a set parameterizing the corresponding equivalence classes of blocks, and for each  choose a representative
choose a representative  of the corresponding equivalence class.
of the corresponding equivalence class. 
 be the convolution algebra of a finite group
be the convolution algebra of a finite group  Then, the left regular representation
Then, the left regular representation 
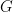 is abelian, then the Fourier transform
is abelian, then the Fourier transform 
 be any function on
be any function on 

 is the linear operator on the Hilbert space
is the linear operator on the Hilbert space  given by the image of the Fourier basis vector
given by the image of the Fourier basis vector  under the injective algebra homomorphism
under the injective algebra homomorphism  In other words,
In other words, 
 and
and 
 This says that the operators
This says that the operators  making up the image of the commutative algebra
making up the image of the commutative algebra  is the same thing as calculating the Fourier transform of the function
is the same thing as calculating the Fourier transform of the function 

 Hint: show that every
Hint: show that every 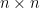 circulant matrix is the image of a function on the cyclic group of order
circulant matrix is the image of a function on the cyclic group of order 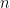 in the regular representation.
in the regular representation. 

 consisting of orthogonal projections, called its Fourier basis. Thus any function
consisting of orthogonal projections, called its Fourier basis. Thus any function  can be expanded in the group basis,
can be expanded in the group basis,

 defined by
defined by 
 defined by
defined by 
 is an algebra isomorphism
is an algebra isomorphism  Thus, we have
Thus, we have
 = \sum\limits_{h \in G} A(gh^{-1})B(h), \quad g \in G,](https://s0.wp.com/latex.php?latex=%5BA%2AB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7D%29B%28h%29%2C+%5Cquad+g+%5Cin+G%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 and on the right hand side
and on the right hand side = \widehat{A}(\lambda)\widehat{B}(\lambda), \quad \lambda \in \Lambda](https://s0.wp.com/latex.php?latex=%5B%5Cwidehat%7BA%7D%5Cwidehat%7BB%7D%5D%28%5Clambda%29+%3D+%5Cwidehat%7BA%7D%28%5Clambda%29%5Cwidehat%7BB%7D%28%5Clambda%29%2C+%5Cquad+%5Clambda+%5Cin+%5CLambda&bg=FFFFFF&fg=000&s=0&c=20201002)


 is the character basis of
is the character basis of 
 we have
we have
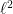 -scalar product in
-scalar product in 




 corresponding to a given group element
corresponding to a given group element  From the inversion formula, the Fourier transform of the indicator function of
From the inversion formula, the Fourier transform of the indicator function of 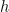 is
is 

 is the elementary basis of
is the elementary basis of  consisting of indicator functions
consisting of indicator functions 
 we have
we have


 together with the definition of the norm associated to a scalar product.
together with the definition of the norm associated to a scalar product. the
the  case of the
case of the  -norm, which for any
-norm, which for any  is defined by
is defined by
 , which is defined by
, which is defined by 
 the sum
the sum  is approximately equal to its largest term, and this concentration becomes exact in the
is approximately equal to its largest term, and this concentration becomes exact in the 


 which in terms of the character basis
which in terms of the character basis 
 we have
we have
 Since
Since  was arbitrary, the above shows that
was arbitrary, the above shows that

 it can be cancelled from both sides of the above inequality, leaving
it can be cancelled from both sides of the above inequality, leaving
 of a group
of a group 
 defined by
defined by

 is a function from the convolution algebra
is a function from the convolution algebra  Moreover, the map
Moreover, the map 
 of
of  and
and  on
on  Since
Since 

 under
under  it represents
it represents  to be a cyclic group of order four with generator
to be a cyclic group of order four with generator  is the group unit. The group basis of
is the group unit. The group basis of  and we denote these vectors by
and we denote these vectors by  for brevity. Let
for brevity. Let 

 with respect to the ordered basis
with respect to the ordered basis 
 . Moreover, it is possible to establish Corollary 8.1 directly, without appealing to Theorem 8.1. This is done constructively, by finding an explicit basis of orthogonal projections in the commutative convolution algebra
. Moreover, it is possible to establish Corollary 8.1 directly, without appealing to Theorem 8.1. This is done constructively, by finding an explicit basis of orthogonal projections in the commutative convolution algebra  for
for  is an algebra homomorphism if and only if the function
is an algebra homomorphism if and only if the function  defined by
defined by
 the unitary group of the complex numbers.
the unitary group of the complex numbers. is called a character of
is called a character of  .
.
 However, for highly noncommutative groups there may not be many nontrivial characters.
However, for highly noncommutative groups there may not be many nontrivial characters.
 To begin, recall that
To begin, recall that 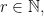 and
and  positive integers
positive integers  and consider the group
and consider the group
 is a cyclic group of order
is a cyclic group of order  with generator
with generator  Define the dual group of
Define the dual group of 

 is the additive group of integers modulo
is the additive group of integers modulo  writing
writing
 is a group isomorphism
is a group isomorphism  (Exercise: prove this, noting that because
(Exercise: prove this, noting that because  it is sufficient to show the parameterization is an injective group homomorphism).
it is sufficient to show the parameterization is an injective group homomorphism). the function
the function  defined by
defined by
 is a principal
is a principal 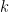 th
th  because the identity element
because the identity element  has parameters
has parameters  Moreover, for any
Moreover, for any  we have
we have
 is indeed a group homomorphism
is indeed a group homomorphism  of the convolution algebra
of the convolution algebra  We now claim that the characters form a basis of
We now claim that the characters form a basis of  which is the dimension of
which is the dimension of 
 we have
we have

 we have
we have
 we have
we have
 is an
is an  th root of unity.
th root of unity. since this highlights the symmetry
since this highlights the symmetry  The
The  symmetric matrix
symmetric matrix ![X=[\chi^\lambda_\alpha]](https://s0.wp.com/latex.php?latex=X%3D%5B%5Cchi%5E%5Clambda_%5Calpha%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is called the character table of
is called the character table of  is a symmetric unitary matrix. Another way to say the same thing is that the rescaled character basis
is a symmetric unitary matrix. Another way to say the same thing is that the rescaled character basis






 , every partition of
, every partition of  is called a class function if it is constant on conjugacy classes, meaning that
is called a class function if it is constant on conjugacy classes, meaning that  for all
for all 
 for all
for all 

 if and only if it is constant on conjugacy classes.
if and only if it is constant on conjugacy classes. For any
For any  , we have
, we have = \sum\limits_{h \in G} A(gh^{-1})B(h) = \sum\limits_{h \in G} A(g(gh)^{-1}) B(gh) = \sum\limits_{h \in G} A(gh^{-1}g^{-1})B(gh),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7D%29B%28h%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28g%28gh%29%5E%7B-1%7D%29+B%28gh%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7Dg%5E%7B-1%7D%29B%28gh%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 simply permutes the terms of the sum. Continuing the calculation, we have
simply permutes the terms of the sum. Continuing the calculation, we have = \sum\limits_{h \in G} A(gh^{-1}g^{-1})B(gh) =\sum\limits_{h \in G} A(h^{-1})B(gh) = \sum\limits_{h \in G} B(gh)A(h^{-1}),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7Dg%5E%7B-1%7D%29B%28gh%29+%3D%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28h%5E%7B-1%7D%29B%28gh%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+B%28gh%29A%28h%5E%7B-1%7D%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \sum\limits_{h \in G} B(gh^{-1})A(h) = [BA](g),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+B%28gh%5E%7B-1%7D%29A%28h%29+%3D+%5BBA%5D%28g%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 is a central function; we will prove it is constant on conjugacy classes. Since
is a central function; we will prove it is constant on conjugacy classes. Since  it commutes with every elementary function
it commutes with every elementary function  . Since
. Since = \sum\limits_{k \in G}Z(hk^{-1})E_g(k)=Z(hg^{-1}),](https://s0.wp.com/latex.php?latex=%5BZE_g%5D%28h%29+%3D+%5Csum%5Climits_%7Bk+%5Cin+G%7DZ%28hk%5E%7B-1%7D%29E_g%28k%29%3DZ%28hg%5E%7B-1%7D%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \sum\limits_{k\in G}E_g(hk^{-1})Z(k)=Z(g^{-1}h),](https://s0.wp.com/latex.php?latex=%5BE_gZ%5D%28h%29+%3D+%5Csum%5Climits_%7Bk%5Cin+G%7DE_g%28hk%5E%7B-1%7D%29Z%28k%29%3DZ%28g%5E%7B-1%7Dh%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 for all
for all  . Thus
. Thus 
 let
let  be the indicator function of
be the indicator function of  so
so 

 span the class algebra of
span the class algebra of  constant on conjugacy classes can be written
constant on conjugacy classes can be written
 denotes the value
denotes the value  for any
for any  We will show that
We will show that 

 is a partition of
is a partition of 
 is an orthogonal (but not orthonormal) set of functions in
is an orthogonal (but not orthonormal) set of functions in ![[c_{\alpha\beta\gamma}]](https://s0.wp.com/latex.php?latex=%5Bc_%7B%5Calpha%5Cbeta%5Cgamma%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of
of  i.e.
i.e.  For any
For any  and any
and any  , show that
, show that
 counts solutions to the equation
counts solutions to the equation  in
in  and
and  are required to belong to
are required to belong to  and
and  respectively.
respectively.

 = A(x)B(x), \quad x \in X,](https://s0.wp.com/latex.php?latex=%5BAB%5D%28x%29+%3D+A%28x%29B%28x%29%2C+%5Cquad+x+%5Cin+X%2C&bg=FFFFFF&fg=000&s=0&c=20201002)

 For each
For each  define the corresponding elementary function
define the corresponding elementary function  by
by
 where
where  is the
is the =E_x(z)E_y(z)=\delta_{xz}\delta_{yz}=\delta_{xy}E_x(z).](https://s0.wp.com/latex.php?latex=%5BE_xE_y%5D%28z%29%3DE_x%28z%29E_y%28z%29%3D%5Cdelta_%7Bxz%7D%5Cdelta_%7Byz%7D%3D%5Cdelta_%7Bxy%7DE_x%28z%29.&bg=FFFFFF&fg=000&s=0&c=20201002)
 is a linearly independent set in
is a linearly independent set in  can be written as
can be written as



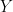 are said to be isomorphic if there exists a
are said to be isomorphic if there exists a  are isomorphic.
are isomorphic.
 , where
, where  is the elementary function corresponding to
is the elementary function corresponding to  is also an algebra homomorphism. Indeed, by Theorem 1.2 and linearity of
is also an algebra homomorphism. Indeed, by Theorem 1.2 and linearity of 


 then the linear transformation
then the linear transformation
 Thus,
Thus,
 so defined is an algebra isomorphism. Note that the Fourier transform on
so defined is an algebra isomorphism. Note that the Fourier transform on 

 The function
The function 
 is the product of
is the product of  , which might be convoluted and difficult to calculate. On the other hand, the pointwise product of the corresponding functions
, which might be convoluted and difficult to calculate. On the other hand, the pointwise product of the corresponding functions  is very simple, both conceptually and computationally.
is very simple, both conceptually and computationally.  of
of  and is closed under multiplication and conjugation.
and is closed under multiplication and conjugation. of
of 
 is the smallest subalgebra of
is the smallest subalgebra of 
 are called central elements.
are called central elements. be any two central elements and
be any two central elements and  , we have
, we have


 .
.
 (minimally commutative, maximally noncommutative) and
(minimally commutative, maximally noncommutative) and  (maximally commutative, minimally noncommutative). Any algebra
(maximally commutative, minimally noncommutative). Any algebra  have the lowest commutativity index; such maximally noncommutative algebras are called
have the lowest commutativity index; such maximally noncommutative algebras are called  is the set of all elements in
is the set of all elements in 
 .
. is indeed a subalgebra of
is indeed a subalgebra of  are subalgebras of
are subalgebras of  then
then 
 , a relation on
, a relation on  of
of 
 to denote the membership of
to denote the membership of  in
in  For example, you are familiar with the notion of an
For example, you are familiar with the notion of an  with the following properties :
with the following properties : for all
for all  ;
; iff
iff  ;
; then
then  .
. for all
for all  and
and  then
then  ;
; and
and  then
then  .
. consisting of a set together with a partial order on it is called a
consisting of a set together with a partial order on it is called a  by definition means
by definition means  . Importantly, note the use of the adjective “partial” – Definition 2.3 allows for the possibility that there are pairs of elements
. Importantly, note the use of the adjective “partial” – Definition 2.3 allows for the possibility that there are pairs of elements  for which neither
for which neither 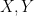 are incomparable. The axiomatic study of partially ordered sets is a branch of algebra called
are incomparable. The axiomatic study of partially ordered sets is a branch of algebra called  by inclusion:
by inclusion:
 , then
, then  subsets of
subsets of 

 is the largest subset of
is the largest subset of 

 is the smallest subset of
is the smallest subset of 
 set is the only subset of
set is the only subset of  . Similarly, the whole set
. Similarly, the whole set  is the only set satisfying
is the only set satisfying  to be the set of all vector subspaces of
to be the set of all vector subspaces of  is an
is an  as intersection, because the intersection of two subspaces is again a subspace. However, the union of two subspaces is not, and we have to modify the definition to
as intersection, because the intersection of two subspaces is again a subspace. However, the union of two subspaces is not, and we have to modify the definition to 
 , as the empty subset of
, as the empty subset of  to be the set of all subalgebras of
to be the set of all subalgebras of  is an induced subposet of
is an induced subposet of  of subalgebras of
of subalgebras of  into a lattice, because the span of the union
into a lattice, because the span of the union  of two subalgebras of
of two subalgebras of  , define
, define  to be the intersection of all subalgebras of
to be the intersection of all subalgebras of 
 be the set of all commutative subalgebras of
be the set of all commutative subalgebras of 
 This definition will fail if one of
This definition will fail if one of  is not contained in any larger commutative subalgebra of
is not contained in any larger commutative subalgebra of  with the following property: if
with the following property: if  is a commutative subalgebra with
is a commutative subalgebra with  , then
, then  .
.
 . If
. If  such that
such that  In this case, the algebra generated by
In this case, the algebra generated by  is a commutative subalgebra of
is a commutative subalgebra of  and this contradicts the maximality of
and this contradicts the maximality of 
 Then for a commutative subalgebra
Then for a commutative subalgebra  we have
we have
 (note that the conclusion of Problem 2.1 was used here) .
(note that the conclusion of Problem 2.1 was used here) . . Annals of Mathematics 18 (1916), p. 70-73.
. Annals of Mathematics 18 (1916), p. 70-73.