The convolution and class algebras  and
and  of a group
of a group 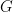 are apparently quite different from the other types of algebras we have seen, namely function algebras
are apparently quite different from the other types of algebras we have seen, namely function algebras  and linear algebras
and linear algebras  However, they are in fact closely related.
However, they are in fact closely related.
Theorem 9.1. The convolution algebra is isomorphic to a subalgebra of a linear algebra.
Proof: Since has a natural scalar product, the 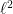 -scalar product
-scalar product

it is a Hilbert space as well as an algebra. For each  , consider the function
, consider the function  defined by
defined by

Observe that  is a linear operator on
is a linear operator on  i.e.
i.e.

Thus,  is a function from the convolution algebra to the linear algebra
is a function from the convolution algebra to the linear algebra  Moreover, the map itself is a linear transformation, i.e.
Moreover, the map itself is a linear transformation, i.e.

We claim that is an injective linear transformation. Since is a linear transformation of , it is completely determined by its action on the group basis  of . Thus, it suffices to show that the linear operators
of . Thus, it suffices to show that the linear operators  and
and  on are distinct unless
on are distinct unless  Since and are linear operators on they are uniquely determined by their actions on the group basis of . We have
Since and are linear operators on they are uniquely determined by their actions on the group basis of . We have

hence

From this we can conclude that the image of in  under is a subspace isomorphic to . It remains to show that is not just a linear transformation, but an algebra homomorphism, and we leave this as an exercise (that you really should do).
under is a subspace isomorphic to . It remains to show that is not just a linear transformation, but an algebra homomorphism, and we leave this as an exercise (that you really should do).
-QED
The proof of Theorem 8.1 is the linear version of Cayley’s theorem from group theory: instead of representing as a subgroup of the group of permutations of  it represents as a subalgebra of the algebra of linear operators on
it represents as a subalgebra of the algebra of linear operators on  This is called the left regular representation of
This is called the left regular representation of
Corollary 9.2. The class algebra is isomorphic to a function algebra.
Proof: Since is a subalgebra of , and since is isomorphic to a subalgebra of a linear algebra, is isomorphic to a subalgebra of a linear algebra. Thus, is isomorphic to a commutative subgalgebra of a linear algebra, and we have previously shown that all commutative subalgebras of linear algebras are isomorphic to function algebras.
-QED
For an example illustrating how the proof of Theorem 8.1 works, let us take  to be a cyclic group of order four with generator
to be a cyclic group of order four with generator  , so that
, so that  is the group unit. The group basis of is thus
is the group unit. The group basis of is thus  and we denote these vectors by
and we denote these vectors by  for brevity. Let be any function on and let
for brevity. Let be any function on and let

be its expansion in the group basis, so that

Problem 9.1. Show by direct calculation that the matrix of  with respect to the ordered basis of is
with respect to the ordered basis of is

In the case where is an abelian group, as in the example above, we have that  . Moreover, it is possible to establish Corollary 8.1 directly, without appealing to Theorem 8.1. This is done constructively, by finding an explicit basis of orthogonal projections in the commutative convolution algebra called its Fourier basis. The advantage of this direct approach is that it also gives us an explicit description of the spectrum of all matrices in the left regular representation of This is very useful in applications – in particular, matrices in the left regular representation of a cyclical group are called circulant matrices and they are important in engineering.
. Moreover, it is possible to establish Corollary 8.1 directly, without appealing to Theorem 8.1. This is done constructively, by finding an explicit basis of orthogonal projections in the commutative convolution algebra called its Fourier basis. The advantage of this direct approach is that it also gives us an explicit description of the spectrum of all matrices in the left regular representation of This is very useful in applications – in particular, matrices in the left regular representation of a cyclical group are called circulant matrices and they are important in engineering.
To see begin to see where a projection basis of might come from, recall that we previously showed the non-existence of an algebra homomorphism  for
for 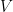 a Hilbert space of dimension at least two. This reflects the fact that linear algebras
a Hilbert space of dimension at least two. This reflects the fact that linear algebras  are maximally noncommuative. But we have also seen that for a group with at least two elements, the dimension of is at least two, so convolution algebras are always at least one degree more commutative than linear algebras, and therefore might admit homomorphisms to the complex numbers.
are maximally noncommuative. But we have also seen that for a group with at least two elements, the dimension of is at least two, so convolution algebras are always at least one degree more commutative than linear algebras, and therefore might admit homomorphisms to the complex numbers.
Theorem 9.3. A linear transformation  is an algebra homomorphism if and only if the function
is an algebra homomorphism if and only if the function  defined by
defined by

is a group homomorphism taking values in  the unitary group of the complex numbers.
the unitary group of the complex numbers.
Problem 9.2. Prove Theorem 8.3.
Definition 9.1. A group homomorphism  is called a character of
is called a character of  The set of all characters of is denoted
The set of all characters of is denoted  .
.
Observe first of all that is a set of functions on is a subset of the space of all 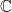 -valued functions on It is this special subset of functions tethered to the group law in that we look to for orthogonal projections. No matter what the group is, the set is nonempty: it contains at least the trivial character defined by
-valued functions on It is this special subset of functions tethered to the group law in that we look to for orthogonal projections. No matter what the group is, the set is nonempty: it contains at least the trivial character defined by 
 However, for highly noncommutative groups there may not be many nontrivial characters.
However, for highly noncommutative groups there may not be many nontrivial characters.
Problem 9.3. Determine the Fourier dual of the symmetric group 
For abelian groups the situation is much better and in fact we always have  To begin, recall that every finite abelian group is isomorphic to a product of cyclic groups. We thus fix a positive integer
To begin, recall that every finite abelian group is isomorphic to a product of cyclic groups. We thus fix a positive integer 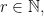 and
and  positive integers
positive integers  and consider the group
and consider the group

where  is a cyclic group of order
is a cyclic group of order  with generator
with generator  Define the dual group of to be
Define the dual group of to be

That is,

where  is the additive group of integers modulo
is the additive group of integers modulo 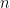 . We can parameterize by the points of
. We can parameterize by the points of  writing
writing

Indeed, the parameterization  is a group isomorphism
is a group isomorphism  (Exercise: prove this, noting that because
(Exercise: prove this, noting that because  it is sufficient to show the parameterization is an injective group homomorphism).
it is sufficient to show the parameterization is an injective group homomorphism).
Theorem 9.4. For every  the function
the function  defined by
defined by

where  is a principal
is a principal 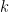 th root of unity, is a character of and every character of is of this form.
th root of unity, is a character of and every character of is of this form.
Proof: For any it is clear that  because the identity element
because the identity element  has parameters
has parameters  Moreover, for any
Moreover, for any  we have
we have

so  is indeed a group homomorphism
is indeed a group homomorphism  The fact that every homomorphism is for some
The fact that every homomorphism is for some  is left as an exercise.
is left as an exercise.
-QED
We now have a special subset  of the convolution algebra of the finite abelian group , namely the set of all homomorphisms to the unitary group
of the convolution algebra of the finite abelian group , namely the set of all homomorphisms to the unitary group  We now claim that the characters form a basis of Since the number of characters is
We now claim that the characters form a basis of Since the number of characters is  which is the dimension of , it is sufficient to show that is a linearly independent set in
which is the dimension of , it is sufficient to show that is a linearly independent set in
Theorem 9.5. The set  is orthogonal with respect to the -scalar product on – we have
is orthogonal with respect to the -scalar product on – we have

Proof: For any  we have
we have

where

Thus if  we have
we have

and if  we have
we have

where the denominator of each fraction is nonzero and the numerator is zero, because  is an
is an  th root of unity.
th root of unity.
-QED
The orthogonal basis of is called its character basis. It is convenient to write  since this highlights the symmetry
since this highlights the symmetry  The
The  symmetric matrix
symmetric matrix ![X=[\chi^\lambda_\alpha]](https://s0.wp.com/latex.php?latex=X%3D%5B%5Cchi%5E%5Clambda_%5Calpha%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is called the character table of and Theorem 8.3 says that
is called the character table of and Theorem 8.3 says that  is a symmetric unitary matrix. Another way to say the same thing is that the rescaled character basis
is a symmetric unitary matrix. Another way to say the same thing is that the rescaled character basis

is an orthonormal basis of the convolution algebra In fact, the further scaling

is even better, for the following reason.
Theorem 9.6. The elements of the basis  are orthogonal projections in
are orthogonal projections in
Proof: For any we have

For any we have

The internal sum is

where the final equality is Theorem 8.3. Thus

-QED
Since we know that any algebra with a basis of orthogonal projections is isomorphic to the function algebra (Lecture 3), Theorem 8.4 gives the promised second proof of the fact that the convolution algebra of an abelian group is isomorphic to a function algebra. In this particular case, the basis is known as the Fourier basis of








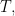














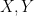


























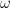










 be the convolution algebra of a finite group
be the convolution algebra of a finite group  be a linear map from
be a linear map from 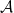 into the algebra of linear operators on a Hilbert space
into the algebra of linear operators on a Hilbert space  We define an associated function on the underlying group
We define an associated function on the underlying group 
 is the elementary function on
is the elementary function on  is a function with domain
is a function with domain  is an algebra homomorphism if and only if
is an algebra homomorphism if and only if  the unitary group of the algebra
the unitary group of the algebra  is an algebra homomorphism from
is an algebra homomorphism from  we have
we have

 is the identity operator on
is the identity operator on 
 is invertible in
is invertible in  Thus
Thus  This is verified by
This is verified by
 to
to  It is sufficient to check this for the elementary basis, and we have
It is sufficient to check this for the elementary basis, and we have


 is the algebra of complex numbers and
is the algebra of complex numbers and  is the unit circle in
is the unit circle in  In this one-dimensional setting, we gathered enough information to construct the Fourier transform on
In this one-dimensional setting, we gathered enough information to construct the Fourier transform on  consisting of a Hilbert space
consisting of a Hilbert space 
 and
and  are unitary representations of
are unitary representations of  such that
such that 
 If
If  as above is a vector space isomorphism, then we say that
as above is a vector space isomorphism, then we say that  i.e. an isometric isomorphism. To be completely explicit, there is
i.e. an isometric isomorphism. To be completely explicit, there is  such that
such that 
 be a linear representation of
be a linear representation of  be the corresponding unitary representation of
be the corresponding unitary representation of 
 , the unitary representation
, the unitary representation  obtained by restricting each
obtained by restricting each  to
to  , which we successfully achieved in our development of the Fourier transform; we called the parameterization set
, which we successfully achieved in our development of the Fourier transform; we called the parameterization set  be a set parameterizing isomorphism classes of irreducible unitary representations of
be a set parameterizing isomorphism classes of irreducible unitary representations of  We know absolutely nothing about
We know absolutely nothing about  be a representative of the corresponding isomorphism class of irreducible unitary representations. Let
be a representative of the corresponding isomorphism class of irreducible unitary representations. Let  be an orthonormal basis, and for each
be an orthonormal basis, and for each 


 is an orthogonal basis of the convolution algebra
is an orthogonal basis of the convolution algebra 
 is just a homomorphic image of
is just a homomorphic image of  of
of  for some given Hilbert space
for some given Hilbert space  Then, Burnside’s theorem says that either
Then, Burnside’s theorem says that either  or there is a proper non-trivial subspace
or there is a proper non-trivial subspace  invariant under all operators
invariant under all operators  In this situation,
In this situation,  is defined by declaring
is defined by declaring  to be the restriction of
to be the restriction of 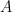 to the invariant subspace
to the invariant subspace  In the case where
In the case where  the pair
the pair  is a linear representation of
is a linear representation of  the identity homomorphism; this is called the tautological representation or defining representation of
the identity homomorphism; this is called the tautological representation or defining representation of 
 are representations of
are representations of  a linear transformation
a linear transformation  is said to be a homomorphism of representations (or an intertwining transformation) if
is said to be a homomorphism of representations (or an intertwining transformation) if 

 is a vector subspace of the space
is a vector subspace of the space 
 is said to be an isomorphism of representations. When such an intertwining linear isomorphism exists, we say that
is said to be an isomorphism of representations. When such an intertwining linear isomorphism exists, we say that 
 of
of  of
of  -basis of
-basis of  in the
in the  -basis of
-basis of  for every algebra element
for every algebra element 
 , which is a subalgebra of
, which is a subalgebra of  is the subalgebra consisting of all operators
is the subalgebra consisting of all operators  that commute with every operator
that commute with every operator 

 if and only if
if and only if  which is exactly the condition for
which is exactly the condition for 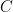 to be an element of
to be an element of 
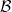 -invariant subspaces of
-invariant subspaces of 
 we have the following.
we have the following.
 is the centralizer of
is the centralizer of  the statement is equivalent to the fact that the center of
the statement is equivalent to the fact that the center of  We claim that
We claim that  is a
is a  -invariant subspace of
-invariant subspace of  then for any
then for any  we have
we have
 is again in
is again in  Since
Since  or
or  and since
and since  is a
is a  -invariant subspace of
-invariant subspace of  i.e.
i.e.  for
for  Then, for any
Then, for any 
 remains in the image of
remains in the image of  as claimed.
as claimed. and
and  As we saw in Lecture 14, the trace on
As we saw in Lecture 14, the trace on  such that
such that  Thus, the only linear functional satisfying
Thus, the only linear functional satisfying  and
and  is
is

 we have
we have 
 and the total space
and the total space 
 there is a third
there is a third  by Burnside’s theorem. The orthogonal complement
by Burnside’s theorem. The orthogonal complement  of
of  and we claim it is
and we claim it is  and
and 
 i.e.
i.e.  of scalar operators.
of scalar operators.  be a central element, and let
be a central element, and let  be an eigenvalue of
be an eigenvalue of  Then, the
Then, the  -eigenspace of
-eigenspace of 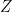 is an
is an  is an eigenvector of
is an eigenvector of 
 is again in the
is again in the 
 where subalgebras are indexed by partitions
where subalgebras are indexed by partitions  of the finite set
of the finite set  . The classification is very simple: the subalgebra
. The classification is very simple: the subalgebra  of a given partition
of a given partition  A nice feature of this classification is that it shows every subalgebra of
A nice feature of this classification is that it shows every subalgebra of 
 The first step is to formulate the vector space version of partitions of a set.
The first step is to formulate the vector space version of partitions of a set. of nonzero subspaces of
of nonzero subspaces of 
 to be the set of all operators
to be the set of all operators  is a subalgebra of
is a subalgebra of  is the linear partition of
is the linear partition of  the subalgebra
the subalgebra  is a linear partition of
is a linear partition of  be an ordered basis of
be an ordered basis of  and let
and let  be an ordered basis of
be an ordered basis of  Then
Then  is an ordered basis of
is an ordered basis of  whose matrix relative to this ordered basis has the form
whose matrix relative to this ordered basis has the form ![[A]_{(e_1,\dots,e_m,f_1,\dots,f_n)}=\begin{bmatrix} M_1 & {} \\ {} & M_2 \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5BA%5D_%7B%28e_1%2C%5Cdots%2Ce_m%2Cf_1%2C%5Cdots%2Cf_n%29%7D%3D%5Cbegin%7Bbmatrix%7D+M_1+%26+%7B%7D+%5C%5C+%7B%7D+%26+M_2+%5Cend%7Bbmatrix%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 and
and  Thus,
Thus,  is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,
is not isomorphic to a linear algebra, but rather to a direct sum of linear algebras,
 does there exist a linear partition
does there exist a linear partition  ? If
? If  the answer is clearly “yes” since we have
the answer is clearly “yes” since we have  Thus we consider the case where
Thus we consider the case where  . Together with the corollary to Burnside’s theorem, we thus have a linear partition
. Together with the corollary to Burnside’s theorem, we thus have a linear partition  of
of  This is almost correct. Let us say that two blocks
This is almost correct. Let us say that two blocks  are
are  such that the matrix of every
such that the matrix of every  of the corresponding equivalence class.
of the corresponding equivalence class. 
 and let
and let  be an orthonormal basis.
be an orthonormal basis.

 are equal if and only if
are equal if and only if  for all
for all 



 ;
; with equality if and only if
with equality if and only if 




 makes sense even if the basis
makes sense even if the basis 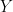 be two orthonormal bases of
be two orthonormal bases of  .
.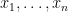 of
of  of
of  defined by
defined by  is unitary. We have
is unitary. We have 

 for the same reason as above. We have thus shown that Definition 14.3 gives the same linear functional on
for the same reason as above. We have thus shown that Definition 14.3 gives the same linear functional on 
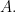
 That is, every operator has an eigenvalue.
That is, every operator has an eigenvalue.
 ?
?

 for all
for all 
 defined by
defined by



 we have
we have


 and consider the matrix element
and consider the matrix element
 form an orthonormal basis of
form an orthonormal basis of 
 for its matrix elements relative
for its matrix elements relative  We claim that
We claim that
 be the operator on the right hand side of the above equation. Then, the matrix elements of
be the operator on the right hand side of the above equation. Then, the matrix elements of 
 of the function algebra
of the function algebra  of the linear algebra
of the linear algebra  are orthogonal projections spanning a commutative subalgebra of
are orthogonal projections spanning a commutative subalgebra of 
 is a scalar multiple of the trace.
is a scalar multiple of the trace. of
of  , we have
, we have

 such that
such that  for all
for all  Thus for any
Thus for any 

 the Fourier basis of
the Fourier basis of 

 is
is  -dimensional and the group basis is
-dimensional and the group basis is 
 ranging over all
ranging over all  . The convolution product of two basis vectors is
. The convolution product of two basis vectors is
 of the
of the  for some
for some  where
where  are the vectors
are the vectors


 This means that the Wedderburn transform of
This means that the Wedderburn transform of 
 the character table is
the character table is
 is the usual dot product. Thus, the Fourier basis of
is the usual dot product. Thus, the Fourier basis of 


 can be simplified: every coordinate of
can be simplified: every coordinate of 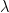 equal to zero contributes
equal to zero contributes 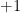 and every coordinate of
and every coordinate of 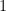 contributes
contributes 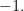 Thus writing
Thus writing  for the number of entries equal to one in
for the number of entries equal to one in  terms equal to one and
terms equal to one and 

 is equal to the number of
is equal to the number of  , which is
, which is 


 be any function on
be any function on 

 is the linear operator on the Hilbert space
is the linear operator on the Hilbert space  given by the image of the Fourier basis vector
given by the image of the Fourier basis vector  In other words,
In other words, 
 and
and 
 This says that the operators
This says that the operators  is the same thing as calculating the Fourier transform of the function
is the same thing as calculating the Fourier transform of the function 

 Hint: show that every
Hint: show that every 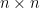 circulant matrix is the image of a function on the cyclic group of order
circulant matrix is the image of a function on the cyclic group of order 



 defined by
defined by 
 defined by
defined by 
 is an algebra isomorphism
is an algebra isomorphism  Thus, we have
Thus, we have
 = \sum\limits_{h \in G} A(gh^{-1})B(h), \quad g \in G,](https://s0.wp.com/latex.php?latex=%5BA%2AB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7D%29B%28h%29%2C+%5Cquad+g+%5Cin+G%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \widehat{A}(\lambda)\widehat{B}(\lambda), \quad \lambda \in \Lambda](https://s0.wp.com/latex.php?latex=%5B%5Cwidehat%7BA%7D%5Cwidehat%7BB%7D%5D%28%5Clambda%29+%3D+%5Cwidehat%7BA%7D%28%5Clambda%29%5Cwidehat%7BB%7D%28%5Clambda%29%2C+%5Cquad+%5Clambda+%5Cin+%5CLambda&bg=FFFFFF&fg=000&s=0&c=20201002)







 corresponding to a given group element
corresponding to a given group element  From the inversion formula, the Fourier transform of the indicator function of
From the inversion formula, the Fourier transform of the indicator function of 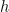 is
is 

 is the elementary basis of
is the elementary basis of  consisting of indicator functions
consisting of indicator functions 
 we have
we have


 together with the definition of the norm associated to a scalar product.
together with the definition of the norm associated to a scalar product. the
the  case of the
case of the  -norm, which for any
-norm, which for any  is defined by
is defined by
 , which is defined by
, which is defined by 
 the sum
the sum  is approximately equal to its largest term, and this concentration becomes exact in the
is approximately equal to its largest term, and this concentration becomes exact in the 


 which in terms of the character basis
which in terms of the character basis 
 we have
we have
 Since
Since  was arbitrary, the above shows that
was arbitrary, the above shows that

 it can be cancelled from both sides of the above inequality, leaving
it can be cancelled from both sides of the above inequality, leaving

 , every partition of
, every partition of  is called a class function if it is constant on conjugacy classes, meaning that
is called a class function if it is constant on conjugacy classes, meaning that  for all
for all 
 for all
for all 

 if and only if it is constant on conjugacy classes.
if and only if it is constant on conjugacy classes. For any
For any  , we have
, we have = \sum\limits_{h \in G} A(gh^{-1})B(h) = \sum\limits_{h \in G} A(g(gh)^{-1}) B(gh) = \sum\limits_{h \in G} A(gh^{-1}g^{-1})B(gh),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7D%29B%28h%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28g%28gh%29%5E%7B-1%7D%29+B%28gh%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7Dg%5E%7B-1%7D%29B%28gh%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 simply permutes the terms of the sum. Continuing the calculation, we have
simply permutes the terms of the sum. Continuing the calculation, we have = \sum\limits_{h \in G} A(gh^{-1}g^{-1})B(gh) =\sum\limits_{h \in G} A(h^{-1})B(gh) = \sum\limits_{h \in G} B(gh)A(h^{-1}),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7Dg%5E%7B-1%7D%29B%28gh%29+%3D%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28h%5E%7B-1%7D%29B%28gh%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+B%28gh%29A%28h%5E%7B-1%7D%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \sum\limits_{h \in G} B(gh^{-1})A(h) = [BA](g),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+B%28gh%5E%7B-1%7D%29A%28h%29+%3D+%5BBA%5D%28g%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 is a central function; we will prove it is constant on conjugacy classes. Since
is a central function; we will prove it is constant on conjugacy classes. Since  it commutes with every elementary function
it commutes with every elementary function  . Since
. Since = \sum\limits_{k \in G}Z(hk^{-1})E_g(k)=Z(hg^{-1}),](https://s0.wp.com/latex.php?latex=%5BZE_g%5D%28h%29+%3D+%5Csum%5Climits_%7Bk+%5Cin+G%7DZ%28hk%5E%7B-1%7D%29E_g%28k%29%3DZ%28hg%5E%7B-1%7D%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \sum\limits_{k\in G}E_g(hk^{-1})Z(k)=Z(g^{-1}h),](https://s0.wp.com/latex.php?latex=%5BE_gZ%5D%28h%29+%3D+%5Csum%5Climits_%7Bk%5Cin+G%7DE_g%28hk%5E%7B-1%7D%29Z%28k%29%3DZ%28g%5E%7B-1%7Dh%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 for all
for all 
 let
let  be the indicator function of
be the indicator function of  so
so 

 span the class algebra of
span the class algebra of  constant on conjugacy classes can be written
constant on conjugacy classes can be written
 denotes the value
denotes the value  for any
for any  We will show that
We will show that 

 is a partition of
is a partition of 
 is an orthogonal (but not orthonormal) set of functions in
is an orthogonal (but not orthonormal) set of functions in ![[c_{\alpha\beta\gamma}]](https://s0.wp.com/latex.php?latex=%5Bc_%7B%5Calpha%5Cbeta%5Cgamma%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of
of  i.e.
i.e.  For any
For any  and any
and any  , show that
, show that
 counts solutions to the equation
counts solutions to the equation  in
in  and
and  are required to belong to
are required to belong to  and
and  respectively.
respectively.