Let 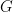 be a finite abelian group.
be a finite abelian group.
Theorem 13.1. For every  the Fourier basis of
the Fourier basis of  is an eigenbasis for the image of
is an eigenbasis for the image of 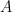 in the left regular representation, and the Fourier transform of is its spectrum: we have
in the left regular representation, and the Fourier transform of is its spectrum: we have

This result has many applications because many interesting matrices can be realized in the left regular representation of an abelian group, and in any such situation Theorem 13.1 explicitly gives us the eigenvalues and eigenvectors of the matrix in question. Last lecture we considered the case of cyclic group, whose elements become circulant matrices in the regular representation.
Let us give another example, this time taking

to be the group of vertices of the  -dimensional unit cube. In this case, the convolution algebra
-dimensional unit cube. In this case, the convolution algebra  is
is  -dimensional and the group basis is
-dimensional and the group basis is

with  ranging over all -dimensional vectors with entries in
ranging over all -dimensional vectors with entries in  . The convolution product of two basis vectors is
. The convolution product of two basis vectors is

with coordinate addition performed mod 2. In addition to being a group, it is natural to view  as a graph which reflects the geometry of the -dimensional cube: we consider two vertices
as a graph which reflects the geometry of the -dimensional cube: we consider two vertices  of the -dimensional cube adjacent if they differ in a single coordinate. Equivalently, we have
of the -dimensional cube adjacent if they differ in a single coordinate. Equivalently, we have  for some
for some  where
where  are the vectors
are the vectors

In more general terminology, we are identifying with its Cayley graph corresponding to the generators 
Adjacency in can also be expressed in , since  are adjacent if and only if
are adjacent if and only if

for some  This means that the Wedderburn transform of
This means that the Wedderburn transform of

is the adjacency operator of the graph , and hence that we can calculate the eigenvalues and eigenvectors of  explicitly using Theorem 13.1.
explicitly using Theorem 13.1.
For the Boolean cube  the character table is
the character table is

where  is the usual dot product. Thus, the Fourier basis of is
is the usual dot product. Thus, the Fourier basis of is

and this is an eigenbasis of . Now by direct computation

The sum

giving the eigenvalue of on  can be simplified: every coordinate of
can be simplified: every coordinate of 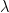 equal to zero contributes
equal to zero contributes 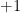 and every coordinate of equal to
and every coordinate of equal to 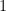 contributes
contributes 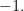 Thus writing
Thus writing  for the number of entries equal to one in (this is called the Hamming weight of in coding theory), we have
for the number of entries equal to one in (this is called the Hamming weight of in coding theory), we have  terms equal to one and terms equal to minus one, giving
terms equal to one and terms equal to minus one, giving

From this we can conclude that the eigenvalues of the -dimensional hypercube are the integers

and that the multiplicity of the eigenvalue  is equal to the number of -vectors with Hamming weight
is equal to the number of -vectors with Hamming weight  , which is
, which is 
Like this:
Like Loading...
Published by Jonathan Novak
Mathematician at UC San Diego.
View all posts by Jonathan Novak