***Problems in this lecture due 23:59 on April 8***
Let  be a finite, connected, simple graph with vertex set
be a finite, connected, simple graph with vertex set  and edge set
and edge set  A basic (meaning fundamental, not necessarily easy) problem is to compute the number
A basic (meaning fundamental, not necessarily easy) problem is to compute the number  of
of  -step walks from
-step walks from  to
to 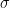 in
in 
Problem 1.1. Let 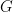 be the complete graph on
be the complete graph on  whose vertex set is
whose vertex set is  Using nothing but your brain, find a formula for
Using nothing but your brain, find a formula for  If you find this problem intractable or, worse, uninteresting, consider a degree in law or medicine.
If you find this problem intractable or, worse, uninteresting, consider a degree in law or medicine.
Math 202A provides an algebraic encoding of graphs. Let  be the Hilbert space with orthonormal basis
be the Hilbert space with orthonormal basis  . Let
. Let  be the dual basis of
be the dual basis of  so that
so that

Does using Dirac notation make this an applied math course? The question is vacuous since there is no such thing as non-applied math, but there are cultural differences between fields which are reflected in their iconography, and hopefully you can at least read a paper in quantum computing at the end of this sequence.
The adjacency operator  acts on the vertex basis of by creating a flat superposition of all vertices adjacent to a given input,
acts on the vertex basis of by creating a flat superposition of all vertices adjacent to a given input,

Equivalently, the matrix elements of  in the vertex basis are
in the vertex basis are

Thus, the selfadjoint operator  encodes the edge set
encodes the edge set 
For example, consider the complete graph on the vertex set  The computational basis in consists of the vectors
The computational basis in consists of the vectors

upon which 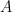 acts according to
acts according to

Problem 1.2. Show that  In particular, show that the trace of
In particular, show that the trace of  equals the total number of loops (i.e. closed walks) of length in
equals the total number of loops (i.e. closed walks) of length in
The linear algebra approach to counting walks in graphs is to find a basis of  on which acts diagonally.
on which acts diagonally.
Problem 1.3. Implement this approach for the complete graph and recover your barehands solution to Problem 1.1.
The mathematical subject which uses eigenvalues of linear operators to analyze graphs is called spectral graph theory. In particular, the spectrum of the adjacency operator on a given graph is called the adjacency spectrum of . A couple of facts worth mentioning: if is bipartite then the spectrum of is symmetric about  ; if is degree-regular then the largest eigenvalue of is the degree of any vertex.
; if is degree-regular then the largest eigenvalue of is the degree of any vertex.
Instead of asking how many walks there are between two given vertices, we may ask how far apart they are. This information is encoded in the distance operator  , whose matrix elements in the vertex basis tabulate geodesic distance in ,
, whose matrix elements in the vertex basis tabulate geodesic distance in ,

Ron Graham made the striking discovery that the determinant of the distance operator on a tree depends only on the cardinality of its vertex set. Distance eigenvalues of graphs have been much studied ever since. I found some recent interesting work on distance operators via Johann Birnick’s website; Johann is the TA for this course.
One can in a sense interpolate between and  . To do so, we consider operators
. To do so, we consider operators  corresponding to metric level sets in , meaning that
corresponding to metric level sets in , meaning that

Equivalently,

is the sum of all points on the sphere of radius centered at . We have that  is the identity operator,
is the identity operator,  is the adjacency operator, and
is the adjacency operator, and

This is in fact a finite sum, since  is the zero operator for all exceeding the diameter of .
is the zero operator for all exceeding the diameter of .
One can also consider the exponential adjacency operator

on , whose matrix elements are exponential generating functions enumerating walks between vertices by length,

For regular graphs this is essentially the heat kernel, which has been much studied. The exponential distance operator,

is the element-wise exponential of the distance operator,

and unlike  it is a relative newcomer in spectral graph theory.
it is a relative newcomer in spectral graph theory.
Looking at the power series which define and  one sees that the level set operators
one sees that the level set operators  are to
are to  as powers
as powers  of the adjacency operator are to
of the adjacency operator are to  While the first two elements of these sequences are the same, a big flaw in this symbolic analogy is that the subalgebra of
While the first two elements of these sequences are the same, a big flaw in this symbolic analogy is that the subalgebra of  generated by the (finite) set of selfadjoint operators
generated by the (finite) set of selfadjoint operators  is highly non-trivial, whereas the subalgebra of generated by the single selfadjoint operator simply consists of polynomials in this operator, which is but a small sector of
is highly non-trivial, whereas the subalgebra of generated by the single selfadjoint operator simply consists of polynomials in this operator, which is but a small sector of  In particular, it is not at all clear what relations exist between and
In particular, it is not at all clear what relations exist between and  , or even whether they commute. We will have more to say about this later.
, or even whether they commute. We will have more to say about this later.
The exponential distance operator encodes the same information as the distance operator in a manner which interfaces more readily with the formalism of statistical mechanics. More precisely, let us write  so that
so that

Then, fixing a root vertex , the th row of defines Gibbs measure (after Josiah, not Amelia) on the vertices of according to

Physically, this distribution corresponds to a thermodynamic ensemble whose states are the vertices of , with  the inverse temperature and the potential energy
the inverse temperature and the potential energy 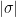 of a state being equal to its distance
of a state being equal to its distance  to the root vertex in . The partition function
to the root vertex in . The partition function

sums the energy over all states, ensuring that  is a probability measure on
is a probability measure on  . Its logarithm
. Its logarithm  is the free energy of our ensemble, and
is the free energy of our ensemble, and

is precisely the average distance to the root vertex under the non-uniform distribution  which becomes the uniform distribution on states in the high-temperature limit
which becomes the uniform distribution on states in the high-temperature limit  limit, where
limit, where  .
.
Let us try this out on a toy example, the complete graph on  . Take the root vertex to be
. Take the root vertex to be 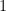 , so that the potential energy of any other vertex
, so that the potential energy of any other vertex  is
is

Thus, under the corresponding Gibbs measure on states we have

and

where the partition function is

We thus have

and setting  we recover the obvious fact that the average distance to under the uniform measure on the complete graph is
we recover the obvious fact that the average distance to under the uniform measure on the complete graph is  Indeed, for the uniform measure on the complete graph the random variable
Indeed, for the uniform measure on the complete graph the random variable  has a Bernoulli distribution on
has a Bernoulli distribution on  which assigns probability
which assigns probability  to and probability
to and probability  to .
to .
Linear operators on graphs fall under the broad umbrella of Math 202A, which treated linear maps between finite-dimensional Hilbert spaces. Math 202B gives us additional algebraic tools which apply to graphs whose vertices form a group; these are officially known as Cayley graphs.
Let be a finite group and  a symmetric set of generators in . Symmetric means that
a symmetric set of generators in . Symmetric means that 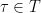 implies
implies  , and saying that
, and saying that  generates means that for any
generates means that for any  there exists
there exists 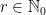 and
and  such that
such that  The Cayley graph
The Cayley graph  has vertex set , with
has vertex set , with  an edge if and only if
an edge if and only if 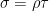 for some
for some 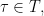 which is then necessarily unique. The fact that is symmetric means that this is a well-defined as an undirected graph without multiple edges, and the fact that generates means that the graph is connected. If does not contain the identity element
which is then necessarily unique. The fact that is symmetric means that this is a well-defined as an undirected graph without multiple edges, and the fact that generates means that the graph is connected. If does not contain the identity element  then no vertex is adjacent to itself, and we henceforth assume this to be the case. We see that for Cayley graphs
then no vertex is adjacent to itself, and we henceforth assume this to be the case. We see that for Cayley graphs  the edge set can effectively be viewed as a subset of the vertex set, since the generating
the edge set can effectively be viewed as a subset of the vertex set, since the generating  determines the adjacency relation on vertices.
determines the adjacency relation on vertices.
For a Cayley graph the space carries not just a scalar product but also a vector product, namely convolution: we have

where  is the group product of
is the group product of 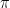 and
and  This gives us a new point of view on the adjacency operator on
This gives us a new point of view on the adjacency operator on  For any subset
For any subset  let
let

be the corresponding element of . Thus in particular

Let us allow the following extremely useful abuse of notation: we will also identify  with its image in the (right) regular representation of . Thus,
with its image in the (right) regular representation of . Thus,

In particular, is both our chosen generating set of , and also its image in the regular representation is the adjacency operator on 

More generally, let

be the sphere of radius centered at the identity element. This set becomes a vector in via quantization,

and this vector becomes an operator in  via the regular representation,
via the regular representation,

The matrix elements of the operator are

and

in which case

Thus, the image of  in the (right) regular representation is indeed the metric level set operator
in the (right) regular representation is indeed the metric level set operator 
To sum up, the adjacency eigenvalues of the Cayley graph are the eigenvalues of  acting in the regular representation of . This means that the spectral graph theory of Cayley graphs is part of the representation theory of finite groups. If we are in the incredibly fortuitous situation where is an abelian group, this comes down to using the discrete Fourier transform.
acting in the regular representation of . This means that the spectral graph theory of Cayley graphs is part of the representation theory of finite groups. If we are in the incredibly fortuitous situation where is an abelian group, this comes down to using the discrete Fourier transform.
Problem 1.4. Let 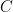 be the cyclic group of order
be the cyclic group of order 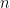 with generator
with generator  , and take the symmetric generating set
, and take the symmetric generating set  Then
Then  is a cycle graph with vertices. Find a formula for
is a cycle graph with vertices. Find a formula for  the number of -step walks between two given vertices of a cycle graph.
the number of -step walks between two given vertices of a cycle graph.
Concerning distance in Cayley graphs , we by definition have that  is equal to the minimal value of such that there exist
is equal to the minimal value of such that there exist  such that
such that

Problem 1.5. Show that for any  we have
we have  and explain why the same cannot in general be said for
and explain why the same cannot in general be said for  Show that
Show that  with the group identity.
with the group identity.
Now let us consider a nonabelian example: our group is  the symmetric group consisting of all bijections
the symmetric group consisting of all bijections  , which are generally called permutations. We will take the group law to be
, which are generally called permutations. We will take the group law to be  which is the convention used in most computer algebra systems, or so I am told. Take the generating set
which is the convention used in most computer algebra systems, or so I am told. Take the generating set

of adjacent transpositions.
Problem 1.6. Draw for 
Set  with the identity permutation.
with the identity permutation.
Now consider the metric Gibbs measure on the Cayley graph of the symmetric group  corresponding to the generating set
corresponding to the generating set  of adjacent transpositions. We take the root vertex to be
of adjacent transpositions. We take the root vertex to be  the identity permutation in
the identity permutation in 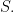 Thus,
Thus,

where  is the minimal number of adjacent transpositions whose produce is .
is the minimal number of adjacent transpositions whose produce is .
Problem 1.7. Show that  , where
, where  is the cardinality of the set
is the cardinality of the set  of inversions in the permutation Hence compute the diameter of
of inversions in the permutation Hence compute the diameter of
We conclude that the metric Gibbs measure on  is
is

This is a famous probability measure on permutations called the Mallows measure; it arises in theoretical computer science in the analysis of sorting algorithms. It is a remarkable fact that the partition function

It is a remarkable fact that this partition function can be evaluated exactly, i.e. this stat mech model is exactly solvable. For any positive integer 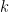 , the corresponding
, the corresponding  -number is
-number is
![[k]_q = 1+q+ \dots + q^{k-1},](https://s0.wp.com/latex.php?latex=%5Bk%5D_q+%3D+1%2Bq%2B+%5Cdots+%2B+q%5E%7Bk-1%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
so that in particular ![[k]_1=k](https://s0.wp.com/latex.php?latex=%5Bk%5D_1%3Dk&bg=FFFFFF&fg=000&s=0&c=20201002) reverts to an ordinary number at
reverts to an ordinary number at  The -factorial is accordingly defined as
The -factorial is accordingly defined as
![[k]_q! = [1]_q[2]_q \dots [k]_q.](https://s0.wp.com/latex.php?latex=%5Bk%5D_q%21+%3D+%5B1%5D_q%5B2%5D_q+%5Cdots+%5Bk%5D_q.&bg=FFFFFF&fg=000&s=0&c=20201002)
Here’s a pretty thing.
Theorem 1.1. The partition function for Mallows measure is ![Z=[n]_q!.](https://s0.wp.com/latex.php?latex=Z%3D%5Bn%5D_q%21.&bg=FFFFFF&fg=000&s=0&c=20201002)
Now you can derive many things, including the following.
Problem 1.8. Find a formula for the expected number of inversions in a random permutation whose distribution is Mallows measure. Using your result, find a formula for the expected number of inversions in a uniformly random permutation.
 . In Lecture 1 we introduced the metrics level set linear operators
. In Lecture 1 we introduced the metrics level set linear operators 
 is the adjacency operator,
is the adjacency operator,

 is the cardinality of the intersection of the sphere of radius
is the cardinality of the intersection of the sphere of radius  centered at
centered at ![[L_s,L_r]=L_sL_r - L_rL_s](https://s0.wp.com/latex.php?latex=%5BL_s%2CL_r%5D%3DL_sL_r+-+L_rL_s&bg=FFFFFF&fg=000&s=0&c=20201002)
![\langle \sigma | [L_s,L_r] |\rho\rangle = |S_\rho(r) \cap S_\sigma(s)|-|S_\rho(s) \cap S_\rho(r)|,](https://s0.wp.com/latex.php?latex=%5Clangle+%5Csigma+%7C+%5BL_s%2CL_r%5D+%7C%5Crho%5Crangle+%3D+%7CS_%5Crho%28r%29+%5Ccap+S_%5Csigma%28s%29%7C-%7CS_%5Crho%28s%29+%5Ccap+S_%5Crho%28r%29%7C%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![[L_r,L_s]=0.](https://s0.wp.com/latex.php?latex=%5BL_r%2CL_s%5D%3D0.&bg=FFFFFF&fg=000&s=0&c=20201002)
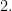 Prove that the metric level set operators on
Prove that the metric level set operators on 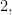 the metric does not contain any more information than the adjacency relation).
the metric does not contain any more information than the adjacency relation). we write
we write
 in the right regular representation, i.e. we identity the set
in the right regular representation, i.e. we identity the set  with the operator
with the operator  defined by
defined by 


 is the group identity. In other words,
is the group identity. In other words,  is the coefficient of the vector
is the coefficient of the vector  which is the same thing as the value of the function
which is the same thing as the value of the function  Here is a second under-appreciated characterization of this important functional, which is often referred to as the canonical group trace.
Here is a second under-appreciated characterization of this important functional, which is often referred to as the canonical group trace. of the image
of the image  in the regular representation are equal to the same number, and that that number is
in the regular representation are equal to the same number, and that that number is  Hence conclude (as was already shown in Math 202B) that the
Hence conclude (as was already shown in Math 202B) that the 
 As discussed above, we may also view
As discussed above, we may also view  as the adjacency operator on
as the adjacency operator on  is the number of length
is the number of length  commute for a very simple reason: they are the images of the vectors
commute for a very simple reason: they are the images of the vectors


 parts.
parts. is a central element in the convolution algebra
is a central element in the convolution algebra  be a set indexing the conjugacy classes in
be a set indexing the conjugacy classes in  so for the symmetric group
so for the symmetric group  For each
For each  choose a representative
choose a representative  of the corresponding isomorphism class. By Schur’s Lemma, any central element
of the corresponding isomorphism class. By Schur’s Lemma, any central element  acts in each irrep
acts in each irrep 


 is
is  because the isotypic decomposition of the regular representation is
because the isotypic decomposition of the regular representation is

 of
of 
 in which
in which  is a one-dimensional Hilbert space and
is a one-dimensional Hilbert space and  sends every
sends every 
 in which
in which

 , in which
, in which 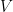 is the Hilbert space with orthonormal basis
is the Hilbert space with orthonormal basis  and
and  The character of this representation is
The character of this representation is

 -dimensional representation
-dimensional representation  of
of 


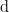 denote the corresponding metric on
denote the corresponding metric on  with
with
 where
where  is the number of factors in the
is the number of factors in the 

 are adjacent vertices, then we have
are adjacent vertices, then we have  and
and  with
with  The decomposition of a group into concentric spheres is a general thing that happens whenever one chooses a generating set; a special feature of this particular situation is that each sphere further decomposes into a disjoint union of conjugacy classes,
The decomposition of a group into concentric spheres is a general thing that happens whenever one chooses a generating set; a special feature of this particular situation is that each sphere further decomposes into a disjoint union of conjugacy classes,
 means that
means that 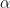 is a decomposition of
is a decomposition of  positive integers, without regard to order of the terms. Every permutation
positive integers, without regard to order of the terms. Every permutation  gives a partition
gives a partition  obtained from the lengths of the cycles in its disjoint cycle decomposition; conversely, for any partition
obtained from the lengths of the cycles in its disjoint cycle decomposition; conversely, for any partition  is a conjugacy class in
is a conjugacy class in 
 with the potential energy of
with the potential energy of 

 is the
is the 


 in the symmetric group
in the symmetric group  , and the number of geodesics
, and the number of geodesics  is
is  where
where 
 of
of  is
is

 with
with  , the larger of the two numbers swapped. Thus, emanating from every vertex of the graph we have one
, the larger of the two numbers swapped. Thus, emanating from every vertex of the graph we have one 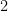 -edge, two
-edge, two  -edges, three
-edges, three 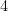 -edges, etc. Call a walk on the Cayley graph strictly monotone if the labels of the edges it traverses form a strictly increasing sequence. Thus, an
-edges, etc. Call a walk on the Cayley graph strictly monotone if the labels of the edges it traverses form a strictly increasing sequence. Thus, an  corresponds to an equation of the form
corresponds to an equation of the form
 Conclude that there exists a unique strictly monotone walk between every pair of points in
Conclude that there exists a unique strictly monotone walk between every pair of points in  be three distinct permutations in
be three distinct permutations in  and
and  It may happen
It may happen  in which case both of these triangles are flat, and have perimeter
in which case both of these triangles are flat, and have perimeter

 which we call the genus of the triple
which we call the genus of the triple  . At the other extreme from flatness, it may be that
. At the other extreme from flatness, it may be that 


 on pairs of permutations. Going even further, let us fix the second argument to be
on pairs of permutations. Going even further, let us fix the second argument to be  , where
, where  Then, we obtain a corresponding decomposition of the symmetric group
Then, we obtain a corresponding decomposition of the symmetric group
 is the set of permutations of genus
is the set of permutations of genus  . The set
. The set 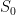 of “planar” permutations consists precisely of those
of “planar” permutations consists precisely of those  and these permutations have a special feature: the disjoint cycle decomposition of any
and these permutations have a special feature: the disjoint cycle decomposition of any  is a
is a  and in fact this map from genus zero permutations into noncrossing permutations is bijective. There is also a very natural partial order on
and in fact this map from genus zero permutations into noncrossing permutations is bijective. There is also a very natural partial order on  if and only if
if and only if  ? This is an open question. The most natural thing that I can think of is the following: given two permutations
? This is an open question. The most natural thing that I can think of is the following: given two permutations  , we declare
, we declare  and a particle emanating from
and a particle emanating from  is a maximal abelian subalgebra of an algebra
is a maximal abelian subalgebra of an algebra 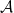 , then the centralizer
, then the centralizer  of
of 
 Now, if the containment is proper, then there exists an element
Now, if the containment is proper, then there exists an element  which does not lie in
which does not lie in 
 is by definition the intersection of all commutative subalgebras of
is by definition the intersection of all commutative subalgebras of  and this could conceivably be empty. To be concrete, imagine a single non-normal matrix
and this could conceivably be empty. To be concrete, imagine a single non-normal matrix  -closure, and by hypothesis
-closure, and by hypothesis 
 of pairwise orthogonal selfadjoint idempotents. If such a basis exists, then
of pairwise orthogonal selfadjoint idempotents. If such a basis exists, then  the orthogonality of the Fourier basis vectors can only refer to the fact that the vector product of two distinct Fourier basis vectors is the zero vector.
the orthogonality of the Fourier basis vectors can only refer to the fact that the vector product of two distinct Fourier basis vectors is the zero vector. can be expanded on the Fourier basis,
can be expanded on the Fourier basis,
 One of our most basic but important theorems from early on in the course is that the map
One of our most basic but important theorems from early on in the course is that the map  is an algebra isomorphism
is an algebra isomorphism  This algebra isomorphism is called the Fourier transform on
This algebra isomorphism is called the Fourier transform on 
 which sends each
which sends each  . A good name for the homomorphism
. A good name for the homomorphism  would be the
would be the  together is the left-regular representation of
together is the left-regular representation of  consisting of left multiplication operators
consisting of left multiplication operators  ,
, 
 , and we also are able to identify a Frobenius scalar product on the commutative algebra
, and we also are able to identify a Frobenius scalar product on the commutative algebra  and the Wedderburn transform
and the Wedderburn transform  are in play. They are moreover related in a very useful way: the Fourier basis
are in play. They are moreover related in a very useful way: the Fourier basis 

 is the convolution algebra of a finite abelian group,
is the convolution algebra of a finite abelian group,  we started from the observation that the set
we started from the observation that the set  of multiplicative characters of
of multiplicative characters of  This allows us to define a Fourier basis in
This allows us to define a Fourier basis in 
 of
of  is a commutative algebra associated to
is a commutative algebra associated to 
 Let
Let  be the set of conjugacy classes in
be the set of conjugacy classes in  let
let  be the indicator function of
be the indicator function of 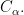 Then, the set
Then, the set  is an orthogonal basis of
is an orthogonal basis of 


 is the number of pairs
is the number of pairs  such that
such that  where
where  Let
Let 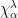 denote
denote  for any
for any  In Lecture 25, we posed the following problem which expresses the connection coefficients of
In Lecture 25, we posed the following problem which expresses the connection coefficients of  we have
we have

 -norm of
-norm of  and show that
and show that 
 nonzero functions
nonzero functions


 leaving
leaving

 let
let 



 which are constant on the conjugacy classes of
which are constant on the conjugacy classes of  then the operator
then the operator  is a scalar multiple of the the identity operator,
is a scalar multiple of the the identity operator,


 is an algebra homomorphism, given in terms of the character of
is an algebra homomorphism, given in terms of the character of 
 be the subspace of
be the subspace of  We will show that
We will show that  consists solely of the zero function. That is, if
consists solely of the zero function. That is, if 

 rather than the convolution algebra
rather than the convolution algebra 
 in every irreducible representation
in every irreducible representation  which says the following.
which says the following.

 with rows and columns indexed by
with rows and columns indexed by 
 with rows and columns indexed by
with rows and columns indexed by 


 we have
we have





 is finite, and there is a formula for the multiplicity of a given irreducible in a given representation.
is finite, and there is a formula for the multiplicity of a given irreducible in a given representation. be any finite-dimensional unitary representation of
be any finite-dimensional unitary representation of  If not, then it contains a proper subrepresentation, i.e. a nonzero subspace
If not, then it contains a proper subrepresentation, i.e. a nonzero subspace  which is
which is  is also
is also  and
and  we have
we have

 of
of  and
and 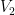 , and after finitely many steps you will produce a binary tree whose leaves are irreducible subrepresentations of
, and after finitely many steps you will produce a binary tree whose leaves are irreducible subrepresentations of  We thus have a “prime factorization”
We thus have a “prime factorization”
 is the number of leaves in the tree isomorphic to
is the number of leaves in the tree isomorphic to  This is called the isotypic decomposition of
This is called the isotypic decomposition of 


 of
of 
 implies that
implies that  for all
for all 


 be the category of finite-dimensional unitary representations
be the category of finite-dimensional unitary representations 
 which are vector spaces of linear transformations. Namely, for any two unitary representations
which are vector spaces of linear transformations. Namely, for any two unitary representations  is the subspace of
is the subspace of  consisting of those linear transformations which satisfy
consisting of those linear transformations which satisfy 
 are said to intertwine the actions
are said to intertwine the actions 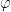 and
and  Equivalently,
Equivalently,  The first thing we did was prove a dimension formula, which we restate now for ease of reference.
The first thing we did was prove a dimension formula, which we restate now for ease of reference.



 is one-dimensional.
is one-dimensional.  is the space of all linear operators
is the space of all linear operators  such that
such that 
 , and e know that
, and e know that  .
. and let
and let  Then,
Then,  is again in the algebra
is again in the algebra  but at the same time
but at the same time  is a nontrivial
is a nontrivial  , which is the same as
, which is the same as 


 which admits no proper non-trivial stable subspace
which admits no proper non-trivial stable subspace  is
is 

 is irreducible.
is irreducible.  Consequently,
Consequently, 
 be an orthonormal basis and let
be an orthonormal basis and let  be the corresponding elementary basis of
be the corresponding elementary basis of  commutes with all elementary operators. Then, for any
commutes with all elementary operators. Then, for any  we have
we have




 .
.  of finite-dimensional Hilbert spaces. What this means is that the same Hilbert space
of finite-dimensional Hilbert spaces. What this means is that the same Hilbert space  , but at the same time hom-spaces in
, but at the same time hom-spaces in  of two unitary representations
of two unitary representations 
 is that its kernel and image are subspaces of
is that its kernel and image are subspaces of 
 We say that
We say that  for all
for all  and
and 
 is a
is a  is a
is a  In particular,
In particular,  is a unitary representation of
is a unitary representation of  to
to  and nonzero pairwise orthogonal subspaces
and nonzero pairwise orthogonal subspaces  and
and  of
of 
 has the form
has the form  with
with  an isometric isomorphism.
an isometric isomorphism. and the restriction of
and the restriction of  Moreover, the map
Moreover, the map  is an isometric isomorphism in
is an isometric isomorphism in 
 a space
a space  be the full subcategory of
be the full subcategory of 
 this yields the following.
this yields the following.