*** Problems due April 26 at 23:59 ***
Week Four review and preview.
We began with the algebraic approach to graphs, which you can think of as a natural road to go down after Math 202A. Given a finite, connected, simple graph  with vertex set
with vertex set  , we pass to the Hilbert space
, we pass to the Hilbert space  with orthonormal basis
with orthonormal basis  We encode the edge set
We encode the edge set  as a linear transformation of
as a linear transformation of  which by abuse of notation we also denote
which by abuse of notation we also denote  because it contains exactly the same information. That is, we define the adjacency operator by
because it contains exactly the same information. That is, we define the adjacency operator by

where the sum is over all  such that
such that  The adjacency operator is self-adjoint, and we could equally well define it by
The adjacency operator is self-adjoint, and we could equally well define it by

where the sum is over all  such that Either definition of is consistent with
such that Either definition of is consistent with

More generally, for any nonnegative integer  the matrix element
the matrix element  equals the number of -step walks
equals the number of -step walks  in the graph . The linear algebraic approach is to find an orthonormal basis
in the graph . The linear algebraic approach is to find an orthonormal basis  such that belongs to the maximal commutative subalgebra
such that belongs to the maximal commutative subalgebra  consisting of operators which act diagonally on
consisting of operators which act diagonally on 
We also observed that the adjacency operator is the first member of a sequence  of selfjadoint linear operators on which we called the level operators of the graph
of selfjadoint linear operators on which we called the level operators of the graph  These operators encode not just adjacency in
These operators encode not just adjacency in  but its complete structure as a finite connected metric space. By definition,
but its complete structure as a finite connected metric space. By definition,

where 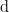 is geodesic distance in . That is,
is geodesic distance in . That is,  acts on an input vertex
acts on an input vertex  by summing all vertices
by summing all vertices  in the sphere of radius centered at
in the sphere of radius centered at  . Equivalently,
. Equivalently,

We noted that although is a finite family of selfadjoint operators in  , it may not be a commutative family. Indeed, we have
, it may not be a commutative family. Indeed, we have

where  and
and  are the spheres of radii and
are the spheres of radii and  centered at the vertices and
centered at the vertices and  respectively. There is no general reason why this would be equal to
respectively. There is no general reason why this would be equal to

Indeed, the subalgebra  of
of  generated by the selfadjoint operators
generated by the selfadjoint operators 
 is in general not well-understood.
is in general not well-understood.
Problem 9.1. If is a finite connected simple graph of diameter 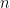 , show that
, show that  is an orthogonal set in
is an orthogonal set in  with respect to the Hilbert-Schmidt (aka Frobenius) scalar product. In particular, conclude that is a subalgebra of dimension at least
with respect to the Hilbert-Schmidt (aka Frobenius) scalar product. In particular, conclude that is a subalgebra of dimension at least 
Although the algebra generated by the selfadjoint operators  is not well-understood, the complete sequence of level operators can be conveniently wrapped into a single operator
is not well-understood, the complete sequence of level operators can be conveniently wrapped into a single operator

called the exponential distance operator of The sum is finite because is the zero operator for all which exceed the diameter of  Note that
Note that  is really a one-parameter family of operators in depending on
is really a one-parameter family of operators in depending on  ; note also that is selfadjoint for
; note also that is selfadjoint for  The reason for the name “exponential distance operator” is that
The reason for the name “exponential distance operator” is that

which says that the matrix of is the entrywise exponential of the distance matrix of

In recent years, graph theorists have grappled with the spectral theory of without recognizing its true significance: the exponential distance operator encodes the same information as the distance operator in a way which interfaces more meaningfully with statistical mechanics on graphs. We spent some time exploring this in Week One.
Now we move on to a concrete case of the above in which is a specific family of graphs. Namely, we consider the graphs  in which
in which  is the symmetric group and
is the symmetric group and  is the conjugacy class of transpositions. This looks strange because the edge set of a graph is not a subset of its vertex set; however for Cayley graphs of groups it can be regarded as such. More precisely, two vertices
is the conjugacy class of transpositions. This looks strange because the edge set of a graph is not a subset of its vertex set; however for Cayley graphs of groups it can be regarded as such. More precisely, two vertices  are adjacent in
are adjacent in  if and only if there exists
if and only if there exists  such that
such that  The fact that we have group law means that we can consider adjacency as induced by multiplication. This same feature propagates up to the level of linear operators, where we can also identify with the adjacency operator
The fact that we have group law means that we can consider adjacency as induced by multiplication. This same feature propagates up to the level of linear operators, where we can also identify with the adjacency operator  using convolution in
using convolution in  which is itself induced by multiplication in
which is itself induced by multiplication in 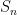 . Namely, for any arbitrary subset
. Namely, for any arbitrary subset  we have a corresponding vector in
we have a corresponding vector in 

which in turn gives becomes an operator  ,
,

Applying this recipe to the conjugacy class implements the adjacency operator on as right multiplication by  More generally,
More generally,  is the sphere of radius one centered at the identity permutation
is the sphere of radius one centered at the identity permutation  If we apply this recipe to the sphere
If we apply this recipe to the sphere  of radius centered at
of radius centered at  we first get the vector
we first get the vector

which in turn becomes the operator

These facts hold for all Cayley graphs. What is special about the case is that all of the spheres  are invariant under conjugation, and in fact are disjoint unions of conjugacy classes in an especially transparent way,
are invariant under conjugation, and in fact are disjoint unions of conjugacy classes in an especially transparent way,

where  is the conjugacy class of permutations of cycle type
is the conjugacy class of permutations of cycle type  This immediately implies that
This immediately implies that

is a central element in and hence that  are commuting selfadjoint operators. In particular, there exists an orthonormal basis
are commuting selfadjoint operators. In particular, there exists an orthonormal basis  such that
such that  belong to the corresponding diagonal subalgebra
belong to the corresponding diagonal subalgebra  Actually, we can say something stronger. Starting with a subset , when we make the chain of identifications
Actually, we can say something stronger. Starting with a subset , when we make the chain of identifications

the first arrow is quantization and the second is the regular representation. Saying that is conjugation invariant is exactly the same thing as saying that which in turn means (by Schur’s Lemma) that acts as multiplication by a scalar operator with eigenvalue  in every irreducible subrepresentation
in every irreducible subrepresentation  of
of  So, not only are the operators
So, not only are the operators  simultaneously diagonalizable, they are actually simultaneously diagonal in any orthonormal basis
simultaneously diagonalizable, they are actually simultaneously diagonal in any orthonormal basis  of any irreducible representation . But this is all abstractly true — what we do not have is a concrete formula for the Fourier transform
of any irreducible representation . But this is all abstractly true — what we do not have is a concrete formula for the Fourier transform  of acting in a given irreducible representation
of acting in a given irreducible representation  In particular, we do not have any explicit numerical understanding of the spectrum of the adjacency operator
In particular, we do not have any explicit numerical understanding of the spectrum of the adjacency operator  of the graph
of the graph  and this is the information that we wish to obtain.
and this is the information that we wish to obtain.
The first step down the path to explicitly diagonalizing the level operators of  is recognize path is to recognize that the central elements
is recognize path is to recognize that the central elements  are nonlinear functions of a fundamental family of non central elements which are even more granular than conjugacy classes. Namely, we decompose
are nonlinear functions of a fundamental family of non central elements which are even more granular than conjugacy classes. Namely, we decompose
 ,
,
where  is the set of transpositions of the form
is the set of transpositions of the form  with
with  These are the Jucys-Murphy subsets of , and the corresponding algebra elements
These are the Jucys-Murphy subsets of , and the corresponding algebra elements

give a decomposition

into pairwise orthogonal elements whose norms are

Even though the Jucys-Murphy elements do not lie in the center  of the convolution algebra they commute with one another. Hence, the Jucys-Murphy operators
of the convolution algebra they commute with one another. Hence, the Jucys-Murphy operators  are commuting selfadjoint operators, and hence are simultaneously diagonalizable. The simple but important way to see this commutativity is to recognize that we have a chain of groups
are commuting selfadjoint operators, and hence are simultaneously diagonalizable. The simple but important way to see this commutativity is to recognize that we have a chain of groups

in which  is identified with the subgroup of consisting of permutations which fix
is identified with the subgroup of consisting of permutations which fix  This gives a chain of subalgebras
This gives a chain of subalgebras

in which  is the span of all permutations which fix Each of these subalgebras comes with its own center
is the span of all permutations which fix Each of these subalgebras comes with its own center  and while the commutative subalgebras
and while the commutative subalgebras

are not nested (in fact  for
for  ) they commute with one another, and the the JM-elements
) they commute with one another, and the the JM-elements  belong to the commutative subalgebra
belong to the commutative subalgebra  generated by their union,
generated by their union,

We proved that  pairwise commute by showing that they are contained in the algebra
pairwise commute by showing that they are contained in the algebra  Indeed, we have that
Indeed, we have that

is contained in the commutative algebra generated by  in The key result which marks the transition from linear algebra to polynomial algebra in Math 202C is the following.
in The key result which marks the transition from linear algebra to polynomial algebra in Math 202C is the following.
Theorem 9.1. We have

where  is the elementary symmetric polynomial of degree
is the elementary symmetric polynomial of degree 
A good way to test your understanding of this key result is to solve the following problem.
Problem 9.2. Prove that the exponential distance operator of the Cayley graph factors as

Deduce from this that is invertible for all complex  satisfying
satisfying 
Theorem 9.1 is what led us into a discussion of polynomials in general, and symmetric polynomials in particular. The algebra ![\mathcal{P}_n=\mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D_n%3D%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of polynomials in commuting selfadjoint variables has basis
of polynomials in commuting selfadjoint variables has basis

indexed by the set  of nonnegative integer vectors
of nonnegative integer vectors  We equip
We equip  with the scalar product in which
with the scalar product in which  is orthonormal. We then have the orthogonal decomposition
is orthonormal. We then have the orthogonal decomposition

where

with 
We consider the (infinite-dimensional) unitary representation  of the symmetric group in which is the polynomial algebra as above and
of the symmetric group in which is the polynomial algebra as above and

The space of invariants ![\mathcal{S}_n=\mathcal{P}_n^{S_n}=\mathbb{C}[x_1,\dots,x_n]^{S_n}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D_n%3D%5Cmathcal%7BP%7D_n%5E%7BS_n%7D%3D%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D%5E%7BS_n%7D&bg=FFFFFF&fg=000&s=0&c=20201002) is (by definition) the algebra of symmetric polynomials in commuting selfadjoint variables. It has the orthogonal decomposition
is (by definition) the algebra of symmetric polynomials in commuting selfadjoint variables. It has the orthogonal decomposition

with  An orthogonal basis for
An orthogonal basis for  is given by the monomial symmetric polynomials
is given by the monomial symmetric polynomials

where 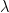 ranges over the set
ranges over the set  of nonnegative integer vectors with weakly decreasing coordinates, and
of nonnegative integer vectors with weakly decreasing coordinates, and  is the set of all
is the set of all 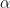 ’s whose weakly decreasing rearrangement is .
’s whose weakly decreasing rearrangement is .
Problem 9.3. Give a bijection  between
between  and the set of all -element subsets of
and the set of all -element subsets of  Express the sum of the elements of
Express the sum of the elements of  in terms of the sum
in terms of the sum  of the coordinates of
of the coordinates of 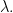
The elementary symmetric polynomials  are defined by
are defined by
 ,
,
where  is the vector whose first coordinates equal
is the vector whose first coordinates equal 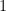 and remaining coordinates equal
and remaining coordinates equal  For
For  , we declare
, we declare  to be the zero polynomial. Let
to be the zero polynomial. Let  be the set of nonnegative integer vectors of infinite length whose coordinates are weakly decreasing and eventually equal zero, and define
be the set of nonnegative integer vectors of infinite length whose coordinates are weakly decreasing and eventually equal zero, and define
 .
.
The condition  is necessary and sufficient in order that
is necessary and sufficient in order that  is not the zero polynomial, and we proved that
is not the zero polynomial, and we proved that

is a basis of  This result is called the fundamental theorem of symmetric polynomials.
This result is called the fundamental theorem of symmetric polynomials.
We are now going to consider a further algebraic consequence of this result. Let  be the convolution algebra of the symmetric group . For each
be the convolution algebra of the symmetric group . For each  the symmetric group is isomorphic to the subgroup of consisting of permutations which fix the numbers Thus we can view as the subalgebra of with basis
the symmetric group is isomorphic to the subgroup of consisting of permutations which fix the numbers Thus we can view as the subalgebra of with basis 
 Let
Let  denote the center of sitting inside The Jucys-Murphy algebra
denote the center of sitting inside The Jucys-Murphy algebra  is by definition the commutative subalgebra of generated by the set
is by definition the commutative subalgebra of generated by the set

Within this subalgebra we have the Jucys-Murphy elements

where  is the conjugacy class of transpositions in
is the conjugacy class of transpositions in 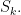 One of our first results is that level sets
One of our first results is that level sets

are elementary symmetric polynomials evaluated on JM-elements,

Since  , combining this with the fundamental theorem of symmetric polynomials gives the following.
, combining this with the fundamental theorem of symmetric polynomials gives the following.
Theorem 9.2. For any ![f \in \mathcal{S}_n=\mathbb{C}[x_1,\dots,x_n]^{S_n},](https://s0.wp.com/latex.php?latex=f+%5Cin+%5Cmathcal%7BS%7D_n%3D%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D%5E%7BS_n%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) we have
we have 
In words, this says that when you evaluate any arbitrary symmetric polynomial on the Jucys-Murphy elements and expand this out as a linear combination of permutations, every pair of conjugate permutations appears with the same coefficient.
As an example, let us consider the complete homogeneous symmetric polynomials, which are defined as
 ,
,
where the sum is over all partitions of .
Problem 9.4 Prove that

and deduce from this that

where 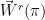 is the number of -step monotone walks
is the number of -step monotone walks  on the Cayley graph of
on the Cayley graph of 
Thus, the function counts factorizations

of a given permutation into transpositions subject to the condition

Problem 9.2 shows that depends only on the cycle type of  Although this fact has been known for over fifteen years, no combinatorial explanation has been found.
Although this fact has been known for over fifteen years, no combinatorial explanation has been found.
I will say a bit more about this enumerative problem since I know that some of you are Stirling number aficionados. For any permutation 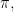 the minimum length of a factorization of
the minimum length of a factorization of 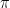 into transpositions is
into transpositions is  and this upper bound of course applies to weakly monotone factorizations as well. Moreover, since we know that there exists a unique strictly monotone geodesic
and this upper bound of course applies to weakly monotone factorizations as well. Moreover, since we know that there exists a unique strictly monotone geodesic  there is at least one weakly monotone geodesic.
there is at least one weakly monotone geodesic.
Theorem 9.2. The number of weakly monotone factorizations of a full cycle  into
into  transpositions is
transpositions is

where  are the central factorial numbers of the second kind.
are the central factorial numbers of the second kind.
The central factorial numbers are certain generalizations of Stirling numbers which appear in quite a variety of situations.
The upshot of the above is that we actually know a few things about the algebra  for the all-transpositions Cayley graph of the symmetric group. Not only do we know that the distance operators
for the all-transpositions Cayley graph of the symmetric group. Not only do we know that the distance operators  , we have a polynomial representation of them in terms of the JM-operators
, we have a polynomial representation of them in terms of the JM-operators  In particular, we know that the commutative algebra
In particular, we know that the commutative algebra  is a subalgebra of . Over the course of the next two lectures, we will prove that in fact
is a subalgebra of . Over the course of the next two lectures, we will prove that in fact  We will then pivot and give a completely different spectral description of this algebra in terms of a distinguished orthonormal basis of , known as its Gelfand-Tsetlin basis.
We will then pivot and give a completely different spectral description of this algebra in terms of a distinguished orthonormal basis of , known as its Gelfand-Tsetlin basis.

![\mathcal{S}_n=\mathbb{C}[x_1,\dots,x_n]^{S_n}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D_n%3D%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D%5E%7BS_n%7D&bg=FFFFFF&fg=000&s=0&c=20201002)




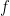




![g \in \mathcal{P}_n=\mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=g+%5Cin+%5Cmathcal%7BP%7D_n%3D%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

;

![\mathcal{Z}_n=\mathbb{C}[|J_1\rangle,\dots,|J_n\rangle]^{S_n}=\mathbb{C}[|L_0\rangle,\dots,|L_{n-1}\rangle],](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BZ%7D_n%3D%5Cmathbb%7BC%7D%5B%7CJ_1%5Crangle%2C%5Cdots%2C%7CJ_n%5Crangle%5D%5E%7BS_n%7D%3D%5Cmathbb%7BC%7D%5B%7CL_0%5Crangle%2C%5Cdots%2C%7CL_%7Bn-1%7D%5Crangle%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)





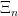

![\mathcal{P}_\mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D_%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=FFFFFF&fg=000&s=0&c=20201002)


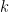
 with orthonormal basis
with orthonormal basis  and consider the selfadjoint operators
and consider the selfadjoint operators
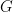 . We have that
. We have that  while the nonzero operators
while the nonzero operators  form an orthogonal set in
form an orthogonal set in  generated by the selfadjoint operators
generated by the selfadjoint operators 
 corresponding to a symmetric set of generators
corresponding to a symmetric set of generators  we are in a more favorable situation because the operator
we are in a more favorable situation because the operator 
 and leverage the group structure of
and leverage the group structure of  of order
of order  This graph is easy to picture: it is a cycle on
This graph is easy to picture: it is a cycle on 
 This is a nonabelian group, and yet the operators
This is a nonabelian group, and yet the operators 
 denotes the conjugacy class of permutations of cycle type
denotes the conjugacy class of permutations of cycle type 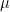 , belong to the center
, belong to the center  of
of  generate a subalgebra
generate a subalgebra 

 are the Jucys-Murphy elements and
are the Jucys-Murphy elements and 

 so that Theorem 10.1 is equivalent to the following.
so that Theorem 10.1 is equivalent to the following. of symmetric polynomials indexed by partitions
of symmetric polynomials indexed by partitions  such that
such that 



 and
and  such that
such that 


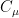 of conjugacy classes in
of conjugacy classes in  to be the partition
to be the partition  obtained by subtracting
obtained by subtracting  Then, the decomposition of the levels
Then, the decomposition of the levels 
 is the conjugacy class of permutations in
is the conjugacy class of permutations in  In this language, the data we have so far is
In this language, the data we have so far is 
 — what is actually true is that
— what is actually true is that 

 of homogeneous degree
of homogeneous degree 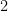 symmetric polynomial in
symmetric polynomial in 
 is, so it remains to calculate
is, so it remains to calculate 

 copies of
copies of  giving a net contribution of
giving a net contribution of 
 with
with  so the product gives one of the two distinct three-cycles
so the product gives one of the two distinct three-cycles  or
or  and the opposite product
and the opposite product  gives the other one, so that
gives the other one, so that 


 ,
, as a symmetric polynomial in the JM-elements.
as a symmetric polynomial in the JM-elements.  in
in  the class expansion of the monomial symmetric polynomials
the class expansion of the monomial symmetric polynomials  of degree three is
of degree three is
 becomes
becomes 
 as
as  this is the triangular system
this is the triangular system
 of the Cayley graph
of the Cayley graph  but in fact for every partition
but in fact for every partition  there holds a class expansion
there holds a class expansion ,
, are polynomials in
are polynomials in  and modulo lower levels
and modulo lower levels  , we have
, we have
 means that
means that  are partitions of
are partitions of  with weakly decreasing coordinates. Then, each
with weakly decreasing coordinates. Then, each  can be viewed as a partition of the number
can be viewed as a partition of the number


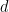 component
component  of the algebra
of the algebra 
![e_r(x_1,\dots,x_n) = \sum\limits_{\substack{I \subseteq [n] \\ |I|=r}} \prod\limits_{i \in I} x_i.](https://s0.wp.com/latex.php?latex=e_r%28x_1%2C%5Cdots%2Cx_n%29+%3D+%5Csum%5Climits_%7B%5Csubstack%7BI+%5Csubseteq+%5Bn%5D+%5C%5C+%7CI%7C%3Dr%7D%7D+%5Cprod%5Climits_%7Bi+%5Cin+I%7D+x_i.&bg=FFFFFF&fg=000&s=0&c=20201002)
 denote the set of all partitions of
denote the set of all partitions of  with weakly decreasing coordinates whose total sum
with weakly decreasing coordinates whose total sum  We extend the definition of the elementary symmetric polynomial multiplicatively by defining
We extend the definition of the elementary symmetric polynomial multiplicatively by defining 
 . Then, in order for
. Then, in order for  not to be the zero polynomial it is necessary and sufficient that
not to be the zero polynomial it is necessary and sufficient that  which is equivalent to the condition
which is equivalent to the condition  The fundamental theorem of symmetric polynomials says that
The fundamental theorem of symmetric polynomials says that
 Equivalently, the claim is that
Equivalently, the claim is that
 we have
we have
 is the number of
is the number of  matrices with entries in
matrices with entries in  whose row sums are encoded by
whose row sums are encoded by  Note that this is consistent with what we have seen: if
Note that this is consistent with what we have seen: if  then there cannot be a
then there cannot be a  and all the coefficients
and all the coefficients  are zero. Second (this is a homework problem), we have
are zero. Second (this is a homework problem), we have  unless
unless  in
in  and moreover
and moreover 
 we have
we have
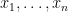 to lighten the notation. Now let
to lighten the notation. Now let  be such that
be such that  Since transpose of Young diagrams is an involution, this is equivalent to
Since transpose of Young diagrams is an involution, this is equivalent to  , and the above becomes
, and the above becomes

 we have
we have

 spans
spans  which cannot be represented as a linear combination of the elementary polynomials
which cannot be represented as a linear combination of the elementary polynomials  Let us choose such an
Let us choose such an 

 equal zero. Choose a nonzero coefficient
equal zero. Choose a nonzero coefficient  is exactly
is exactly  contradiction.
contradiction.  is a basis of the finite-dimensional Hilbert space
is a basis of the finite-dimensional Hilbert space  we conclude that
we conclude that
![\mathcal{S}_n = \mathbb{C}[e_1,\dots,e_n],](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D_n+%3D+%5Cmathbb%7BC%7D%5Be_1%2C%5Cdots%2Ce_n%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![\mathbb{C}[e_1,\dots,e_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Be_1%2C%5Cdots%2Ce_n%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of all polynomials in variables
of all polynomials in variables

![\mathcal{S}_n^d = \mathbb{C}[x_1,\dots,x_n]^{S_n}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D_n%5Ed+%3D+%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D%5E%7BS_n%7D&bg=FFFFFF&fg=000&s=0&c=20201002) , and we are trying to prove that
, and we are trying to prove that 
 is the partition obtained by transposing the Young diagram of
is the partition obtained by transposing the Young diagram of 
![\mathbb{C}[x_1,\dots,x_n]^{S_n}=\mathbb{C}[e_1,\dots,e_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D%5E%7BS_n%7D%3D%5Cmathbb%7BC%7D%5Be_1%2C%5Cdots%2Ce_n%5D&bg=FFFFFF&fg=000&s=0&c=20201002) . Note that since
. Note that since 
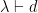 with
with 


![e_{\lambda_i}(x_1,\dots,x_n)=\sum\limits_{\substack{S \subseteq [n] \\ |S|=\lambda_i}} \prod\limits_{i \in S} x_i](https://s0.wp.com/latex.php?latex=e_%7B%5Clambda_i%7D%28x_1%2C%5Cdots%2Cx_n%29%3D%5Csum%5Climits_%7B%5Csubstack%7BS+%5Csubseteq+%5Bn%5D+%5C%5C+%7CS%7C%3D%5Clambda_i%7D%7D+%5Cprod%5Climits_%7Bi+%5Cin+S%7D+x_i&bg=FFFFFF&fg=000&s=0&c=20201002)
![[n]=\{1,\dots,n\}.](https://s0.wp.com/latex.php?latex=%5Bn%5D%3D%5C%7B1%2C%5Cdots%2Cn%5C%7D.&bg=FFFFFF&fg=000&s=0&c=20201002) To visualize the monomials which occur in this expansion, write down the
To visualize the monomials which occur in this expansion, write down the 
 a total of
a total of 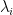 distinct entries from the first row of the above matrix,
distinct entries from the first row of the above matrix,  distinct entries from the second row, etc. This selection process can be recorded by setting all chosen elements to
distinct entries from the second row, etc. This selection process can be recorded by setting all chosen elements to  , leaving a
, leaving a  The meaning of the list
The meaning of the list  of column sums of this
of column sums of this  is the number of times the variable
is the number of times the variable  was chosen,
was chosen,  is the number of times the variable
is the number of times the variable 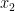 was chosen, etc., so that
was chosen, etc., so that  Thus the number of times the monomial
Thus the number of times the monomial
 the number of
the number of 
 is the weakly decreasing rearrangement of
is the weakly decreasing rearrangement of  we have
we have  since permuting columns has no effect on row sums.
since permuting columns has no effect on row sums. 
 is a basis of
is a basis of  we want to exploit properties of the “matrix” of coefficients
we want to exploit properties of the “matrix” of coefficients  The quotes indicate the fact that, since we have not said how the elements of
The quotes indicate the fact that, since we have not said how the elements of  should be ordered, we have not said how the numbers
should be ordered, we have not said how the numbers  and
and  with weakly decreasing coordinates and total sum equal to
with weakly decreasing coordinates and total sum equal to  if and only if
if and only if


 and that moreover
and that moreover 



 Now we quantize, meaning that we replace
Now we quantize, meaning that we replace 






 On the other hand,
On the other hand, 

 acts on
acts on 
 This permutation action gives rise to a unitary representation
This permutation action gives rise to a unitary representation 


 latex S_n$-invariant vectors in this unitary representation, i.e. polynomials with the property that
latex S_n$-invariant vectors in this unitary representation, i.e. polynomials with the property that

 may be identified with the set of partitions of
may be identified with the set of partitions of  is the corresponding orbit sum
is the corresponding orbit sum
 is an orthogonal basis of
is an orthogonal basis of  This is the basis of monomial symmetric polynomials, which have the form
This is the basis of monomial symmetric polynomials, which have the form
 actually is a monomial.
actually is a monomial.

 , the coefficient of the monomial
, the coefficient of the monomial  in the product
in the product  is
is 
 .$
.$![\mathcal{P}_n=\mathbb{C}[e_1,\dots,e_n],](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D_n%3D%5Cmathbb%7BC%7D%5Be_1%2C%5Cdots%2Ce_n%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) where
where ![e_r(x_1,\dots,x_n) = \sum\limits_{\substack{I \subset [n] \\ |I|=r}} \prod\limits_{i \in I} x_i.](https://s0.wp.com/latex.php?latex=e_r%28x_1%2C%5Cdots%2Cx_n%29+%3D+%5Csum%5Climits_%7B%5Csubstack%7BI+%5Csubset+%5Bn%5D+%5C%5C+%7CI%7C%3Dr%7D%7D+%5Cprod%5Climits_%7Bi+%5Cin+I%7D+x_i.&bg=FFFFFF&fg=000&s=0&c=20201002)
![[n]=\{1,\dots,n\},](https://s0.wp.com/latex.php?latex=%5Bn%5D%3D%5C%7B1%2C%5Cdots%2Cn%5C%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) so
so  It is notationally convenient to define
It is notationally convenient to define  to be the constant polynomial
to be the constant polynomial  Then, for any partition
Then, for any partition  i.e. for any vector
i.e. for any vector  from the set
from the set 

 is the number of nonzero coordinates of
is the number of nonzero coordinates of  . Now, the set of partitions with largest part at most
. Now, the set of partitions with largest part at most  Thus, Newton’s theorem is equivalent to the following.
Thus, Newton’s theorem is equivalent to the following. the set
the set  is a vector space basis of
is a vector space basis of 
 . In particular, we have
. In particular, we have 


 is equal to the number of permutations in
is equal to the number of permutations in  disjoint cycles.
disjoint cycles. is the classical problem of summing powers of consecutive numbers. At some point in your life you undoubtedly learned that
is the classical problem of summing powers of consecutive numbers. At some point in your life you undoubtedly learned that 

 in general. The problem is “solved” by
in general. The problem is “solved” by  is much cleaner, and may help to mend this childhood trauma.
is much cleaner, and may help to mend this childhood trauma.

 are called weak
are called weak 

 are zero. Note that
are zero. Note that 

 is finite-dimensional, and determine its dimension.
is finite-dimensional, and determine its dimension.






 are said to be
are said to be 
 in
in ![\mathcal{P}_n = \mathbb{C}[x_1,\dots,x_n].](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D_n+%3D+%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D.&bg=FFFFFF&fg=000&s=0&c=20201002) This will allow us to more readily access your existing
This will allow us to more readily access your existing 

 is called a specialization when
is called a specialization when 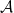 is commutative.
is commutative. is uniquely determine by the images
is uniquely determine by the images  , since with the image of a general polynomial
, since with the image of a general polynomial

 in a commutative algebra
in a commutative algebra ![\Xi \colon \mathbb{C}[x_1,\dots,x_n] \to \mathcal{A}](https://s0.wp.com/latex.php?latex=%5CXi+%5Ccolon+%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D+%5Cto+%5Cmathcal%7BA%7D&bg=FFFFFF&fg=000&s=0&c=20201002) such that
such that 
 determined by
determined by 



 which is the number
which is the number
 admits a second description as the the image of a univariate polynomial
admits a second description as the the image of a univariate polynomial  under the specialization
under the specialization  .
. , determine the distribution of
, determine the distribution of 
 . Probability theory provides efficient tools for doing this when the random variables
. Probability theory provides efficient tools for doing this when the random variables  when
when  ,
, is the center of the subalgebra
is the center of the subalgebra 



 under the JM-specialization. The polynomials in question are the
under the JM-specialization. The polynomials in question are the 



 on the all-transpositions Cayley graph of
on the all-transpositions Cayley graph of  As described in Lecture 1, the metric level set operators on any graph interpolate between the adjacency operator and the distance operator. However, the polynomial decomposition of these operators given above is a special feature of the all-transpositions Cayley graph of the symmetric group, and we will soon diagonalize the Jucys-Murphy operators
As described in Lecture 1, the metric level set operators on any graph interpolate between the adjacency operator and the distance operator. However, the polynomial decomposition of these operators given above is a special feature of the all-transpositions Cayley graph of the symmetric group, and we will soon diagonalize the Jucys-Murphy operators 

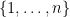 to the unitary group of
to the unitary group of 


 contains a space of invariants,
contains a space of invariants, ![\mathcal{S}_n = \mathcal{P}_n^{S_n} = \mathbb{C}[x_1,\dots,x_n]^{S_n},](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BS%7D_n+%3D+%5Cmathcal%7BP%7D_n%5E%7BS_n%7D+%3D+%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D%5E%7BS_n%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)


 whose cardinality is easy to compute (Problem 4.1). However, the number of orbits into which
whose cardinality is easy to compute (Problem 4.1). However, the number of orbits into which  be the set of weak
be the set of weak  can be permuted so that they become a weakly decreasing list of numbers, hence the orbits of
can be permuted so that they become a weakly decreasing list of numbers, hence the orbits of 
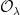 is the set of compositions which sort to the partition
is the set of compositions which sort to the partition 
 and elementary symmetric polynomials
and elementary symmetric polynomials  of a finite group
of a finite group  gives the orthogonal projection
gives the orthogonal projection 
 projects each monomial in
projects each monomial in  Our convention is that permutations are multiplied left-to-right,
Our convention is that permutations are multiplied left-to-right,  We identify $lates S_n$ with its Cayley graph
We identify $lates S_n$ with its Cayley graph  as generated by the conjugacy class of transpositions,
as generated by the conjugacy class of transpositions,
 for
for  Under this identification,
Under this identification, 

 is the set of partitions of
is the set of partitions of  is the number of terms in the partition
is the number of terms in the partition 
 is a selfadjoint element in the convolution algebra
is a selfadjoint element in the convolution algebra  , namely
, namely
 on
on  commute. In particular, these selfadjoint operators are simultaneously diagonalizable. In this Lecture, we will obtain a different combinatorial decomposition of
commute. In particular, these selfadjoint operators are simultaneously diagonalizable. In this Lecture, we will obtain a different combinatorial decomposition of 
 with
with  , the larger of the two elements it transposes. We defined a walk on
, the larger of the two elements it transposes. We defined a walk on  which is the diameter of
which is the diameter of  The figure below illustrates this for
The figure below illustrates this for  with
with 



 .
.





 is included only for notational convenience, as a sequence with initial index
is included only for notational convenience, as a sequence with initial index  is in bijection with
is in bijection with


 and
and
 are selfadjoint operators satisfying
are selfadjoint operators satisfying
 is the adjacency operator on
is the adjacency operator on 


 -subsets, but at the same time it has many advantages. To see these we first the need the following fact.
-subsets, but at the same time it has many advantages. To see these we first the need the following fact.

 form an inductive chain
form an inductive chain
 This gives an inductive chain of algebras,
This gives an inductive chain of algebras,

 for
for 
 commutes with every element of
commutes with every element of  Indeed, assuming
Indeed, assuming  , the center
, the center  consists of all elements commuting with every element of
consists of all elements commuting with every element of  and
and 

 where
where  is the number of partitions of
is the number of partitions of 

 , let
, let 
 . This is an element of
. This is an element of  and indeed an element of
and indeed an element of  Now observe that
Now observe that 
 as a difference of elements in
as a difference of elements in  be the complete graph on
be the complete graph on  and
and 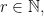 let
let 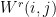 denote the number of
denote the number of  in
in 
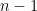 choices for the next vertex to visit. We claim that
choices for the next vertex to visit. We claim that 
 and let
and let  be the transposition which transposes
be the transposition which transposes 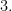 Let
Let  act on the set of walks
act on the set of walks  by
by 
 to the set of
to the set of  , and in fact this bijection is an involution because
, and in fact this bijection is an involution because  The same argument shows that
The same argument shows that  , just use
, just use  instead.
instead.
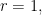 we have
we have  and
and  For
For  we have
we have  and
and  We thus conjecture that
We thus conjecture that






