Author: Haixiao Wang
As demonstrated in [1], expander graphs are a sparse graph that mimic the structure properties of complete graphs, quantified by vertex, edge or spectral expansion. At the same time, expander constructions have spawned research in pure and applied mathematics, with several applications to complexity theory, design of robust computer networks, and the theory of error-correcting codes.
This lecture is organized as follows. We introduce two different definitions of expanders in the first section, and then explore the relationship between them in second part.
17.1. Two Definitions
We start our discussion in expansion with two definitions of expansion: combinatorial and spectral. In the rest of this post, we consider an undirected graph 
, where self loops and multiple edges are allowed. Given two subsets 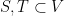


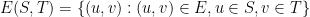
17.1.1. Combinatorial expansion
Intuitively, a graph 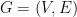
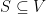

Definition 1(Boundary):
- The Edge Boundary of a set
, is the set of edges
, which is the set of edges between disjoint set
- The Vertex Boundary of a set
.
Obviously, vertex boundary 
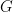
Definition 2(Expander): For some ![\varepsilon \in [0, 1]](https://s0.wp.com/latex.php?latex=%5Cvarepsilon+%5Cin+%5B0%2C+1%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

-edge-expander if
.
.
Remark 3: The reason for the restriction 
Problem 1: Show that the complete graph 
- at least a
-edge-expander.
- a
-vertex-expander. (We only consider
From the definition above, the maximum
Definition 4(Cheeger Constant): The Edge Expansion Ratio, or Cheeger constant, of graph 

Remark 5: Actually, Cheeger constant can be defined alternatively as 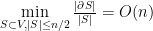
![\varepsilon\in [0, 1]](https://s0.wp.com/latex.php?latex=%5Cvarepsilon%5Cin+%5B0%2C+1%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
17.1.2. Spectral Expansion
To simplify our discussion, we focus on regular graphs in the rest of this lecture. Let 
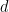
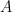
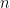

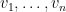

- The largest eigenvalue is
and the corresponding eigenvector is
.
- The graph
.
- The graph is bipartite if and only if
.
The definition of spectral expansion and spectral gap then follows.
Definition 6(Spectral Expansion): A graph 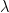

In other words, the second largest eigenvalue of 
Definition 7(Ramanujan graph): A connected 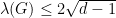
We now refer to the spectral gap.
Definition 8(Spectral Gap): The spectral gap of 
Remark 9: Sometimes the spectral gap is defined as 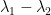
Problem 2:
- Show that the complete graph
. Actually, we can also show that the one-sided spectral gap is
- Show that the complete bipartite graph
has spectral gap
. (Hint: use the spectral property above.)
17.2. Relating Two Definitions
It is not so obvious that the combinatorial and spectral versions of expansion are related. In this section, we will introduce two relations between edge and spectral expansion: the Expander-Mixing Lemma and Cheeger’s inequality.
17.2.1. The Expander-Mixing Lemma
Lemma 10(Expander-Mixing Lemma[2]): Let 
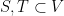
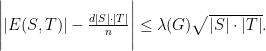
As we can see, the left-hand side measures the deviation between two quantities:
: the number of edges between the two subsets
: the expected number of edges between two subsets
.
The Expander-Mixing lemma tell us a small 
Lemma 11(Expander-Mixing Lemma Converse [4]): Let

for any two disjoint subsets 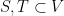


Proof of Expander-Mixing Lemma: Recall that the adjacency matrix 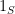




Observing that 
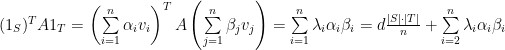
where the last step follows from the facts 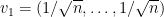

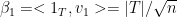

Remark 12: If we normalize the adjacency matrix 



![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

It is sometimes convenient to consider the normalized spectrum. For example in random graph theory, it would be convenient to look at the normalized spectrum when the expected degree 
Regular
Corollary 13: An independent set , in a graph 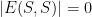
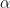
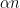
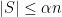
Corollary 14: Given a graph 




17.2.2. Cheeger’s Inequality
As we have seen from previous discussion, spectral expansion implies strong structural properties on the edge-structure of graphs. In this section, we introduce another famous result, Cheeger’s inequality, indicating that the Cheeger constant(Edge Expansion Ratio) of a graph 
Theorem 15(Cheeger’s inequality, [3]): Let 

In the normalized scenario 
![\bar{\lambda}_{1}, \cdots, \bar{\lambda}_n \in [-1, 1]](https://s0.wp.com/latex.php?latex=%5Cbar%7B%5Clambda%7D_%7B1%7D%2C+%5Ccdots%2C+%5Cbar%7B%5Clambda%7D_n+%5Cin+%5B-1%2C+1%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

Remark 16: The proof for the normalized scenario is different from the regular scenario. We should start from the desired quantity and finish the calculation step by step. However, the strategy are the same. We use the Rayleigh Quotient to obtain upper bound and lower bound.
In the context of 
Theorem 17([5]): For every

The 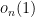
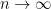
[1]. Shlomo Horry, N. L. and Wigderson, A. (2006). Expander graphs andtheir applications.BULLETIN (New Series) OF THE AMERICAN MATHEMATICAL SOCIETY, 43(4).
[2]. Alon, N. and Chung, F. R. K. (1988). Explicit construction of linear sized tolerantnetworks.Discrete Mathematics, 42
[3]. Cheeger, J. (1970). A lower bound for the smallest eigenvalue of the laplacian.Problems inanalysis, 26.[Nilli, 1991] Nilli, A. (1991). On the secon
[4]. Yonatan Bilu, N. L. (2006). Lifts, discrepancy and nearly optimal spectral gap.Com-binatorica, 26
[5]. Nilli, A. (1991). On the second eigenvalue of a graph.Discrete Mathematics, 91(2):207–210.
[6]. Lovett, S. (2021). Lecture notes for expander graphs and high-dimensional expanders.