Here is a link to the slides from today’s Zoom lecture: https://web.goodnotes.com/s/GPePlT3BSSbzDsGPUrqG2G#page-5
Note that some of this material was typed up towards the end of the Lecture 5 notes.
Here is a link to the slides from today’s Zoom lecture: https://web.goodnotes.com/s/GPePlT3BSSbzDsGPUrqG2G#page-5
Note that some of this material was typed up towards the end of the Lecture 5 notes.
Let 
Let
be the function from Hermitian matrices to standard Euclidean space defined by
Theorem 5.1 (Hoffman-Wielandt Inequality). For any 
Proof: By the spectral theorem, there are unitary matrices 

The square of the Hilbert-Schmidt norm of the difference 
and
Therefore, if we can show
holds for all 
Now,
and ![[|U_{ij}|^2]](https://s0.wp.com/latex.php?latex=%5B%7CU_%7Bij%7D%7C%5E2%5D&bg=FFFFFF&fg=000&s=0&c=20201002)


as 

and since the coordinates of 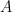

– QED
Now let 
Theorem 5.2. The following are equivalent:
is invariant under unitary conjugation; is invariant under unitary conjugation; is equal in distribution to a random Hermitian matrix of the form  where
where  is a uniformly random unitary matrix and
is a uniformly random unitary matrix and  is a random real diagonal matrix independent of .
is a random real diagonal matrix independent of .We have already proved the equivalence of (1) and (2).
Problem 5.2. Complete the proof of Theorem 5.1.
At this point we have enough information to explain how the characteristic function of a unitarily invariant random Hermitian determines the joint distribution of its eigenvalues.
Theorem 5.2. The characteristic function of a unitarily invariant random Hermitian matrix is equal to the quantum characteristic function of its eigenvalues.
Obviously, this statement needs to be explained.
Let 




Because 

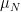

In terms of characteristic functions, this says that
where
is the characteristic function of a uniformly random Hermitian matrix from the 

which we call the quantum Fourier kernel, because it is a superposition of standard 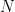
Problem 5.3. Prove that indeed 

If
deserves to be called the quantum characteristic function of random vector 

where
where 
The conclusion to be drawn from all of this is that figuring out how to analyze the eigenvalues of a unitarily invariant random Hermitian matrix 

Before telling you how we will do this, let me tell you how we won’t. The main reason the Hoffman-Weilandt theorem was presented in this lecture is that the proof makes you think about maximizing the function
over unitary matrices 

(I am going to stop writing the Haar measure 

Theorem 5.4 (HCIZ Formula). For any
This is a very interesting formula which makes manifest all the symmetries of the quantum Fourier kernel claimed in Problem 5.3 (but, you should solve that problem without using the determinantal formula). It is also psychologically satisfying in that it shows exactly how the quantum Fourier kernel is built out of classical one-dimensional Fourier kernels. However, it is not really good for much else. We will explain this further in the coming lectures. But first we will adapt all of the above to random rectangular matrices.
We have defined the characteristic function of a random Hermitian matrix 
where the argument 
which carries the Hilbert-Schmidt scalar product
Equivalently,
where 

“A random Hermitian matrix
A natural construction of this form arises from the Spectral Theorem. The set
of unitary matrices is a group under matrix multiplication, called the unitary group of rank 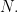
from 
Problem 4.1. Prove that 
One formulation of the Spectral Theorem says: the conjugation orbit
of any Hermitian matrix 

Definition 4.1. A random Hermitian matrix 
for all 

Unitary invariance is a basic symmetry with many ramifications. First of all, it leads to a massive reduction in complexity by allowing us to view the characteristic function of 

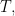


The diagonal Hermitian matrix
can be viewed as a vector 
on
Problem 4.2. Prove that the characteristic function of a unitarily invariant random Hermitian matrix
Now we discuss the probabilistic ramifications of unitary invariance, i.e. what Definition 4.2 implies about the distribution of
Theorem 4.1. The distribution of a unitarily invariant random Hermitian matrix 
Proof: For 
Consequently, we have
which is exactly the characteristic function of the real random vector
Thus, the characteristic function 

-QED
It is important to note that exchangeable random variables are identically distributed, but not necessarily independent.
Problem 4.3. Prove that the diagonal matrix elements of a unitarily invariant random Hermitian matrix 

Now we characterize unitary invariance as a feature of the distribution of a random Hermitian matrix.
Theorem 4.2. A random Hermitian matrix 
Proof: Note that for any random Hermitian matrix
by cyclic invariance of the trace. If
which is equivalent to equidistribution of 

-QED
Theorem 4.2 is quite important for the following reason. Define a random linear operator acting on 
The matrix of 






Lecture slides: https://share.goodnotes.com/s/Rhz5cq25WnLksLyCWa1ML5
Problem 3.1. True or false: the set of unistochastic matrices is a connected subset of the Birkhoff polytope.
Let 

Definition 1.1. A random variable taking values in 
Every random variable leads a double life: it is both a function into
Definition 1.2. The distribution of 
Strictly speaking, it is not correct to conflate 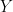
Definition 1.2. The characteristic function of
That is, the characteristic function of a random variable is the Fourier transform of its distribution.
Problem 1.1. Prove that the characteristic function of a random variable is an absolutely continuous function from
The characteristic function of
Random Matrix Theory is one of the most active areas of research in contemporary probability theory. It is a beautiful blend of algebra and probability which enjoys striking connections with many other fields, including combinatorics, number theory, physics, statistics, and something called “data science.” Strangely, RMT makes no use of characteristic functions – I am not aware of a single textbook on random matrices which even defines the characteristic function of a random matrix, despite the fact that this is simply a special case of the above construction.
To be concrete, let us take 
where 
Problem 1.2. Prove that the above really does define a scalar product on the space of Hermitian matrices, and write down an orthonormal basis.
Everything we have said so far about random variables taking values in a general Euclidean space 



The random operator 
The statistical behavior of the geometric invariants of 


In recent years the question of whether a Fourier-analytic approach to random matrices might be possible after all has begun to be reconsidered. I do not claim to have a satisfactory answer to this question, but we will explore it in this topics course and perhaps see the beginnings of an answer. To get the most out of this endeavor, it would be best to absorb the standard approach to random matrix theory at the same time. The course notes by Todd Kemp and Terence Tao are both excellent resources which are freely available online.











![\varphi_{X_N}(A) = \mathbf{E}_{\mu_N}\left[e^{i \mathrm{Tr} AU_NB_NU_N^*}\right] = \mathbf{E}_{\sigma_N} \left[K_N(A,B_N)\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D_%7B%5Cmu_N%7D%5Cleft%5Be%5E%7Bi+%5Cmathrm%7BTr%7D+AU_NB_NU_N%5E%2A%7D%5Cright%5D+%3D+%5Cmathbf%7BE%7D_%7B%5Csigma_N%7D+%5Cleft%5BK_N%28A%2CB_N%29%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
![K_N(A,B) = \mathbf{E}_{\eta_N}\left[e^{i\mathrm{Tr}\, AUBU^*}\right] = \int_{\mathbb{U}_N} e^{i \mathrm{Tr}\, AUBU^*} \eta_N(\mathrm{d}U)](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cmathbf%7BE%7D_%7B%5Ceta_N%7D%5Cleft%5Be%5E%7Bi%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D%5Cright%5D+%3D+%5Cint_%7B%5Cmathbb%7BU%7D_N%7D+e%5E%7Bi+%5Cmathrm%7BTr%7D%5C%2C+AUBU%5E%2A%7D+%5Ceta_N%28%5Cmathrm%7Bd%7DU%29&bg=FFFFFF&fg=000&s=0&c=20201002)



![\psi_{B_N}(A) = \mathbf{E}[K_N(A,B_N)] = \int_{\mathbb{R}^N} K_N(A,B) \sigma_N(\mathrm{d}B)](https://s0.wp.com/latex.php?latex=%5Cpsi_%7BB_N%7D%28A%29+%3D+%5Cmathbf%7BE%7D%5BK_N%28A%2CB_N%29%5D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%5EN%7D+K_N%28A%2CB%29+%5Csigma_N%28%5Cmathrm%7Bd%7DB%29&bg=FFFFFF&fg=000&s=0&c=20201002)




![K_N(A,B) = \frac{1!2! \dots (N-1)!}{i^{N \choose 2}}\frac{\det [ e^{ia_xb_y}]}{\det[a_x^{N-y}]\det[b_x^{N-y}]}.](https://s0.wp.com/latex.php?latex=K_N%28A%2CB%29+%3D+%5Cfrac%7B1%212%21+%5Cdots+%28N-1%29%21%7D%7Bi%5E%7BN+%5Cchoose+2%7D%7D%5Cfrac%7B%5Cdet+%5B+e%5E%7Bia_xb_y%7D%5D%7D%7B%5Cdet%5Ba_x%5E%7BN-y%7D%5D%5Cdet%5Bb_x%5E%7BN-y%7D%5D%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
![\varphi_{X}(T) = \mathbf{E}\left[e^{i\langle T,X \rangle}\right],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28T%29+%3D+%5Cmathbf%7BE%7D%5Cleft%5Be%5E%7Bi%5Clangle+T%2CX+%5Crangle%7D%5Cright%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)














![\varphi_{X}(A) = \mathbb{E}[e^{i\mathrm{Tr}\, AX}] = \mathbb{E}[e^{i(a_1X_{11} + \dots + a_NX_{NN})}],](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28A%29+%3D+%5Cmathbb%7BE%7D%5Be%5E%7Bi%5Cmathrm%7BTr%7D%5C%2C+AX%7D%5D+%3D+%5Cmathbb%7BE%7D%5Be%5E%7Bi%28a_1X_%7B11%7D+%2B+%5Cdots+%2B+a_NX_%7BNN%7D%29%7D%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)







![\varphi_{X}(T) = \mathbf{E}\left[ e^{i \langle T,X\rangle} \right] = \int\limits_{\mathbb{L}} e^{i \langle T,X \rangle} \mu_{X}(\mathrm{d}X), \quad T \in \mathbb{L}.](https://s0.wp.com/latex.php?latex=%5Cvarphi_%7BX%7D%28T%29+%3D+%5Cmathbf%7BE%7D%5Cleft%5B+e%5E%7Bi+%5Clangle+T%2CX%5Crangle%7D+%5Cright%5D+%3D+%5Cint%5Climits_%7B%5Cmathbb%7BL%7D%7D+e%5E%7Bi+%5Clangle+T%2CX+%5Crangle%7D+%5Cmu_%7BX%7D%28%5Cmathrm%7Bd%7DX%29%2C+%5Cquad+T+%5Cin+%5Cmathbb%7BL%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)


