In this pair of lectures we consider the familiar topic of subspaces and projections, continuing our program of studying a subject you already know from a (possibly) new point of view. Probably you have heard of the textbook Linear Algebra Done Right, which prompted a reactionary response in the form an antithetical textbook called Linear Algebra Done Wrong. As to which is better, the debate rages on. Math 202A is Linear Algebra Done Weird. I believe that title is unclaimed; let me know if you have a better one to suggest.
As in previous lectures, we will use category-theoretic thinking to guide us towards analogies between the classical computational category  of finite sets and the quantum computational category
of finite sets and the quantum computational category  of finite-dimensional Hilbert spaces.
of finite-dimensional Hilbert spaces.
In this pair of lectures, we look at subobjects in these categories and compare and contrast the classical (set-theoretic) and quantum (linear-algebraic) aspects of subobjects. In both cases (and indeed much more generally), we can describe subobjects algebraically as equivalence classes of idempotent endomorphisms. In the classical computational category  there is no canonical way to choose a representative of the equivalence class of idempotents which correspond to a given subobject. However, in the quantum computational category the geometry of Hilbert space singles out a natural representative in every equivalence class of idempotents characterized by an orthogonality feature.
there is no canonical way to choose a representative of the equivalence class of idempotents which correspond to a given subobject. However, in the quantum computational category the geometry of Hilbert space singles out a natural representative in every equivalence class of idempotents characterized by an orthogonality feature.
We start on the classical side, where subobjects are just subsets. We have a functor  from finite sets to finite lattices which sends
from finite sets to finite lattices which sends  to its power set,
to its power set,

The partial order in  is containment, meaning that for
is containment, meaning that for  we define
we define

What makes a lattice (as opposed to just a poset) is the fact that we have also the meet and join operations,

which give the smallest set containing both  and the largest set contained in both
and the largest set contained in both  respectively.
respectively.
The subset lattice has a couple of additional properties. First, it is graded, with rank function given by subset cardinality. This means that decomposes into a disjoint union of antichains

in which  and
and

has cardinality

Second, the subset lattice has a natural anti-isomorphism (i.e. order-reversing bijection) given by

Taking complements maps  bijectively onto
bijectively onto  which is why
which is why

Furthermore, for any  we have
we have

Our definition of the power set functor  is not complete until we say where it sends a given set function
is not complete until we say where it sends a given set function  . The corresponding
. The corresponding  is defined by
is defined by
 = f(Y) = \{f(x) \colon x \in y\}.](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BP%7D%28f%29%5D%28Y%29+%3D+f%28Y%29+%3D+%5C%7Bf%28x%29+%5Ccolon+x+%5Cin+y%5C%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
As an exercise, you should check that  really is a morphism in
really is a morphism in 
Now let us consider how we can detect subobjects of algebraically, using functions on 
Definition 10.1. A function  is said to be a retraction onto if
is said to be a retraction onto if  for all
for all  and
and  for all
for all 
Notice that Definition 10.1 only applies to nonempty subsets of . Another remark is that retractions are usually considered as morphisms in the category  whose objects are topological spaces and whose morphisms are continuous functions. We can include
whose objects are topological spaces and whose morphisms are continuous functions. We can include  in by giving every set the discrete topology.
in by giving every set the discrete topology.
Now let us discuss a question raised by Lani Southern: what does it mean to say that there is no “canonical” retraction of onto  The precise meaning of this is that there is no way to assign to each pair
The precise meaning of this is that there is no way to assign to each pair  consisting of a finite set and a subset
consisting of a finite set and a subset  a specific retraction
a specific retraction  of onto
of onto 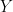 which is equivariant with respect to all automorphisms of that preserve In more detail, let
which is equivariant with respect to all automorphisms of that preserve In more detail, let  denote the subgroup of
denote the subgroup of  consisting of all automorphisms (permutations)
consisting of all automorphisms (permutations) 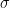 of satisfying
of satisfying  Call a rule
Call a rule  which assigns to set/subset pairs a corresponding retraction canonical if
which assigns to set/subset pairs a corresponding retraction canonical if

Proposition 10.2. If  and
and  is nonempty, no canonical retraction exists.
is nonempty, no canonical retraction exists.
Proof: Suppose otherwise, and let be a canonical retraction of onto . Pick a point  Then, for every
Then, for every  we have
we have

In particular, this holds for every permutation which has our chosen point  as a fixed point and permutes the points of arbitrarily, so the above forces
as a fixed point and permutes the points of arbitrarily, so the above forces  to be fixed by every permutation of
to be fixed by every permutation of  which in turn forces
which in turn forces  a contradiction.
a contradiction. 
In order to get past the above, we would need to break the symmetry of For example, this could mean promoting the structureless finite set to a metric space  Then, for any nonempty
Then, for any nonempty  we can define a retraction of onto by declaring
we can define a retraction of onto by declaring  to be the point of closest to
to be the point of closest to 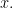 However, even here we need to impose a rule for breaking ties (two distinct minimizers). Once we do this, the retraction is canonical in the sense that it is equivariant with respect to all isometries of
However, even here we need to impose a rule for breaking ties (two distinct minimizers). Once we do this, the retraction is canonical in the sense that it is equivariant with respect to all isometries of  which preserve tie breakers.
which preserve tie breakers.
Definition 10.2. A function is called an idempotent if 
Idempotents allow us to discuss retractions without specifying what they retract onto.
Problem 10.1. Prove that an idempotent is a retraction onto its image  Conversely, show that if is a retraction of onto a subset then
Conversely, show that if is a retraction of onto a subset then 
Let  denote the set of idempotent functions in
denote the set of idempotent functions in  . Define an equivalence relation on by
. Define an equivalence relation on by

Then, associated to each is the equivalence class of idempotent functions with image
![[f]_Y = \{f \in \mathrm{End}(X) \colon \mathrm{Im}(f)=Y,\ f^2=f\}.](https://s0.wp.com/latex.php?latex=%5Bf%5D_Y+%3D+%5C%7Bf+%5Cin+%5Cmathrm%7BEnd%7D%28X%29+%5Ccolon+%5Cmathrm%7BIm%7D%28f%29%3DY%2C%5C+f%5E2%3Df%5C%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
Problem 10.2. Prove that ![Y \mapsto [f]_Y](https://s0.wp.com/latex.php?latex=Y+%5Cmapsto+%5Bf%5D_Y&bg=FFFFFF&fg=000&s=0&c=20201002) is a bijection
is a bijection 
There is another way to encode subsets if we do not insists on self-maps.
Defintion 10.3. The indicator function of is the function  defined by
defined by

The function

which sends each subset to its indicator function  is a bijection (binary encoding of subsets).
is a bijection (binary encoding of subsets).
Now let us transport the above to the quantum computational category by means of our favorite functor

Recall that the quantization functor  sends a finite set to the free Hilbert space
sends a finite set to the free Hilbert space  inside of which lives on as an orthonormal basis. Conversely, if
inside of which lives on as an orthonormal basis. Conversely, if 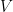 is an arbitrary Hilbert space then we can choose an orthonormal basis of and identity it with
is an arbitrary Hilbert space then we can choose an orthonormal basis of and identity it with 
On the Hilbert space side, the subobject functor

sends a Hilbert space to

with partial order again given by set containment. Thus,  only includes subsets of which are themselves objects of
only includes subsets of which are themselves objects of  The meet and join operations in are
The meet and join operations in are

Moreover, if  is a linear transformation the corresponding order homomorphism
is a linear transformation the corresponding order homomorphism  is defined by
is defined by
 = A(W) = \{Aw \colon w \in W\} = \mathrm{Im}(A).](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BL%7D%28A%29%5D%28W%29+%3D+A%28W%29+%3D+%5C%7BAw+%5Ccolon+w+%5Cin+W%5C%7D+%3D+%5Cmathrm%7BIm%7D%28A%29.&bg=FFFFFF&fg=000&s=0&c=20201002)
The subspace lattice of the Hilbert space is graded by dimension: it decomposes into a disjoint union of  antichains
antichains

where  Although each
Although each  is uncountably infinite set, it has much more structure than just being a very big set. In fact, these sets are important enough that they have a special name.
is uncountably infinite set, it has much more structure than just being a very big set. In fact, these sets are important enough that they have a special name.
Definition 10.4. The set is called the Grassmannian of 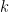 -planes in
-planes in 
Note to self: if we’re going to be using ostentatious names, perhaps should be called the Pascalian of -sets in
Now let  be the free Hilbert space over the finite set Then, every subset
be the free Hilbert space over the finite set Then, every subset  quantizes to
quantizes to  giving
giving  special subspaces of called coordinate subspaces relative to The coordinate subspaces of form an induced sublattice of isomorphic to
special subspaces of called coordinate subspaces relative to The coordinate subspaces of form an induced sublattice of isomorphic to  Complementary subsets of quantize to complementary coordinate subspaces of
Complementary subsets of quantize to complementary coordinate subspaces of
Problem 10.3. Prove that for any we have  Moreover, prove that we have the internal direct sum decomposition
Moreover, prove that we have the internal direct sum decomposition 
Of course, not every subspace  is a coordinate subspace of
is a coordinate subspace of  . For example, for two distinct points
. For example, for two distinct points  the line in spanned by the vector
the line in spanned by the vector  does not contain any point of
does not contain any point of
Problem 10.4. Prove that for any we have the internal direct sum decomposition  (Hint: you can deduce this directly from Problem 10.3 by constructing an appropriate unitary operator on ).
(Hint: you can deduce this directly from Problem 10.3 by constructing an appropriate unitary operator on ).
Now let us again consider the question of encoding subobjects of algebraically, this time as linear operators on rather than arbitrary functions.
Definition 10.5. Given  a linear retraction of onto
a linear retraction of onto  is an operator
is an operator  such that
such that  and the restriction of
and the restriction of  to is the identity operator
to is the identity operator 
Problem 10.5. Prove that linear operator  is a retraction onto its image if and only if it is idempotent,
is a retraction onto its image if and only if it is idempotent, 
As in the set-theoretic setting, let  denote the set of idempotent operator on
denote the set of idempotent operator on  and define an equivalence relation on by declaring two idempotents equivalent if and only if they have the same image.
and define an equivalence relation on by declaring two idempotents equivalent if and only if they have the same image.
Problem 10.6. The map ![W \mapsto [P]_W](https://s0.wp.com/latex.php?latex=W+%5Cmapsto+%5BP%5D_W&bg=FFFFFF&fg=000&s=0&c=20201002) which sends a subspace
which sends a subspace  to the equivalence class
to the equivalence class ![[P]_W](https://s0.wp.com/latex.php?latex=%5BP%5D_W&bg=FFFFFF&fg=000&s=0&c=20201002) of idempotent operators with image is a bijection
of idempotent operators with image is a bijection 
Now we come to a key difference between the classical computational category and the quantum computational category In the classical setting, given a point and a subset , either  or
or  In the quantum setting, given a vector
In the quantum setting, given a vector  and a subspace we can quantify how much
and a subspace we can quantify how much  is or is not
is or is not 
Definition 10.6. For and define

and call this quantity the distance from the vector to the subspace 
Note that the distance from to is indeed well-defined, since the set of distances  with
with  is bounded below by zero. The question of whether or not the minimum is attained is answered in the following.
is bounded below by zero. The question of whether or not the minimum is attained is answered in the following.
Theorem 10.7. For any and any there exists a unique  such that
such that 
Proof: Suppose first that is a coordinate subspace of  That is, we have
That is, we have  for a nonempty and hence
for a nonempty and hence  where
where  For any vector
For any vector  consider its expansion in the orthonormal basis
consider its expansion in the orthonormal basis 

and define

Then,  We claim that
We claim that  and that
and that  is the unique point of which achieves this minimum. To see this, we first compute
is the unique point of which achieves this minimum. To see this, we first compute

On the other hand, for any we have

which is strictly larger than  unless we have
unless we have

in which case 
To finish, observe that the argument above holds even when is not a coordinate subspace of , thanks to Problem 10.4.
In view of Theorem 10.7, the above definition is legitimate.
Definition 10.8. For any subspace we define the orthogonal projection to be the linear operator characterized by

It is clear from the definition that is an idempotent with image  hence it is a retraction of onto (Problem 10.5). As for the name “orthogonal projection,” this is justified by the following.
hence it is a retraction of onto (Problem 10.5). As for the name “orthogonal projection,” this is justified by the following.
Problem 10.7. Prove that  and that
and that 
Hence, we see an important difference between the classical computational category and the quantum computational category : for a finite set and a subset there is no canonical representative of the class ![[f]_Y](https://s0.wp.com/latex.php?latex=%5Bf%5D_Y&bg=FFFFFF&fg=000&s=0&c=20201002) of idempotents with image whereas in the quantized setting we do have a canonical linear retraction onto any subspace characterized by orthogonality.
of idempotents with image whereas in the quantized setting we do have a canonical linear retraction onto any subspace characterized by orthogonality.
To finish, let us consider the case of a coordinate subspace of  i.e.
i.e.  Let be the corresponding orthogonal projection operator. The matrix elements of in the orthonormal basis are described as follows: for two distinct points we have
Let be the corresponding orthogonal projection operator. The matrix elements of in the orthonormal basis are described as follows: for two distinct points we have  and for any we have
and for any we have  That is, the orthogonal projection incorporates the binary encoding of the subset
That is, the orthogonal projection incorporates the binary encoding of the subset  as its diagonal.
as its diagonal.
Let us note that the following question remains open: if we are given an idempotent operator we currently have no algebraic criterion for determining whether or not  is an orthogonal projection. To determine this, we would have to examine the geometry of
is an orthogonal projection. To determine this, we would have to examine the geometry of  meaning that we would have to compute its image
meaning that we would have to compute its image  and check that
and check that  In fact, there is an algebraic characterization of which idempotents actually are orthogonal projections: it is precisely the selfadjoint ones. I mention this because you probably already know it. If you don’t that’s even better, because we will prove this characterization as a theorem after we establish the singular value decomposition, which we shall use to define the adjoint of a general linear transformation.
In fact, there is an algebraic characterization of which idempotents actually are orthogonal projections: it is precisely the selfadjoint ones. I mention this because you probably already know it. If you don’t that’s even better, because we will prove this characterization as a theorem after we establish the singular value decomposition, which we shall use to define the adjoint of a general linear transformation.