Let  be the category whose objects are complex vector spaces
be the category whose objects are complex vector spaces 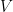 equipped with a scalar product
equipped with a scalar product  and whose morphisms are linear transformations. We call pairs
and whose morphisms are linear transformations. We call pairs  Hilbert spaces, and our convention is that the scalar product is linear in the second slot. The standard definition of Hilbert space includes an extra clause which we do not need and will omit (see below),
Hilbert spaces, and our convention is that the scalar product is linear in the second slot. The standard definition of Hilbert space includes an extra clause which we do not need and will omit (see below),
Problem 2.1. Prove that  is an isomorphism if and only if it is a bijection. That is, isomorphisms in are precisely linear bijections.
is an isomorphism if and only if it is a bijection. That is, isomorphisms in are precisely linear bijections.
The Hilbert space norm on is defined by

To prove that this really is a norm, one needs the Cauchy-Schwarz inequality in order to verify the triangle inequality,

Problem 2.2. Prove the reverse triangle inequality:  . Make sure you understand why this implies that the function
. Make sure you understand why this implies that the function  defined by
defined by  is continuous, in fact
is continuous, in fact 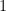 -Lipschitz.
-Lipschitz.
An important fact is that the scalar product in a Hilbert space can be recovered from the norm.
Theorem 2.3. (Polarization) For any  we have
we have

Two vectors  in Hilbert space are said to be orthogonal if
in Hilbert space are said to be orthogonal if 
Theorem 2.4. (Pythagoras) For any orthogonal vectors  , we have
, we have 
An important generalization of the Pythagorean theorem is the following.
Theorem 2.5 (Parallelogram Law) For any we have 
Much of the importance of the Parallelogram Law is that it characterizes when a normed vector space is a Hilbert space. This remarkable fact was first noticed by von Neumann.
Problem 2.3. If is a complex vector space equipped with a norm  then there exists a scalar product on such that
then there exists a scalar product on such that  if and only if the Parallelogram Law holds.
if and only if the Parallelogram Law holds.
The standard definition of Hilbert space includes an extra completeness condition which we was not used above, and will not be used going forward. Therefore, we omit this condition from our definition of what constitutes a Hilbert space.
We define the quantization functor

as follows. First, for every finite set  we declare
we declare

to be the vector space of complex-valued functions on together with the scalar product

Second, if 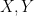 are finite sets and
are finite sets and  is a function, then we declare
is a function, then we declare  to be the linear transformation defined by
to be the linear transformation defined by
 = \sum\limits_{x \in f^{-1}(y)} a(x).](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BF%7D%28f%29a%5D%28y%29+%3D+%5Csum%5Climits_%7Bx+%5Cin+f%5E%7B-1%7D%28y%29%7D+a%28x%29.&bg=FFFFFF&fg=000&s=0&c=20201002)
In words, ](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BF%7D%28f%29a%5D%28y%29&bg=FFFFFF&fg=000&s=0&c=20201002) is the sum of the values of
is the sum of the values of  over the points in the fiber of
over the points in the fiber of 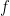 over
over  Assuming are disjoint, you can visualize this by associating to the bipartite graph with vertex set
Assuming are disjoint, you can visualize this by associating to the bipartite graph with vertex set  and edges
and edges  given by input-output pairs of . This bipartite graph is a disjoint union of star graphs: each star consists of a hub vertex
given by input-output pairs of . This bipartite graph is a disjoint union of star graphs: each star consists of a hub vertex  and the remaining vertices of the star are the points of which map to
and the remaining vertices of the star are the points of which map to 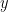 via
via  The function
The function  acts on
acts on 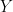 by summing the values of
by summing the values of  over non-hub vertices.
over non-hub vertices.
Problem 2.4. Prove that finite sets and are isomorphic if and only if the Hilbert spaces  and
and  are isomorphic.
are isomorphic.
Now let us explain why we refer to  as the quantization functor. For each
as the quantization functor. For each  the corresponding elementary function
the corresponding elementary function  is defined by
is defined by

A basic feature of these functions is their orthogonality,

Theorem 2.6. For any , there exist unique scalars 
 such that
such that

Proof: To prove existence, check that  works. For uniqueness, imagine we have two such representations of and then use evaluations of to show these representations are the same.
works. For uniqueness, imagine we have two such representations of and then use evaluations of to show these representations are the same. 
Theorem 2.6 allow us to develop an alternative perspective which is widely used in algebra: we view complex-valued functions on as formal 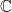 -linear combinations of its points,
-linear combinations of its points,

This is really just notation, and one should remember that the expression above is just a different way of writing down the function  ,
,  The formal linear combination perspective on functions is also widely used in physics. A set
The formal linear combination perspective on functions is also widely used in physics. A set  for example the natural set
for example the natural set ![X=[n],](https://s0.wp.com/latex.php?latex=X%3D%5Bn%5D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) can be viewed as the state space of a particle
can be viewed as the state space of a particle  on the integer lattice which may be located at any of the sites
on the integer lattice which may be located at any of the sites  . The particle is “classical” in the sense of classical mechanics: it has a definite location, which may be any of the sites
. The particle is “classical” in the sense of classical mechanics: it has a definite location, which may be any of the sites 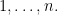 A quantum particle does not have a definition location: before it is observed, it exists simultaneously in each of the states
A quantum particle does not have a definition location: before it is observed, it exists simultaneously in each of the states  , and only after it is observed does its location become definite. A (pure) quantum state is a formal linear combination
, and only after it is observed does its location become definite. A (pure) quantum state is a formal linear combination

of classical states  such that
such that

where the amplitude  is the probability that will be in state once it is observed. Thus, (pure) quantum states are the same thing as unit vectors in the Hilbert space
is the probability that will be in state once it is observed. Thus, (pure) quantum states are the same thing as unit vectors in the Hilbert space  In applying the functor , we are passing from the state space of a classical particle to the state space of a quantum particle.
In applying the functor , we are passing from the state space of a classical particle to the state space of a quantum particle.
Mathematically, many features of Hilbert space can be viewed as quantum generalizations of familiar set-theoretic properties. For example, let  and
and  be two subsets of and let
be two subsets of and let

be their indicator functions in whose norms are  and
and  If and are disjoint, then
If and are disjoint, then  and
and 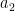 are orthogonal in , and the Pythogorean theorem
are orthogonal in , and the Pythogorean theorem

reproduces  However, the Pythagorean theorem holds for all pairs of orthogonal vectors in , not just indicator functions of disjoint subsets of
However, the Pythagorean theorem holds for all pairs of orthogonal vectors in , not just indicator functions of disjoint subsets of  Similarly, the Parallelogram Law can be seen as a quantum generalization of the inclusion-exclusion principle.
Similarly, the Parallelogram Law can be seen as a quantum generalization of the inclusion-exclusion principle.
Definition 2.7. A Hilbert space is said to be finite-dimensional if there exists a finite set such that is isomorphic to Otherwise, it is said to be infinite-dimensional.
This definition is non-traditional, but it has certain advantages. In particular, thanks to Problem 2.4 we can define the dimension of a finite-dimensional Hilbert space to be the cardinality of any finite set such that is isomorphic to
Problem 2.4. Prove that finite-dimensional Hilbert spaces and  are isomorphic if and only if they have the same dimension.
are isomorphic if and only if they have the same dimension.
A more traditional approach to dimension is based on the following definition.
Definition 2.8. A finite set  of vectors in a Hilbert space is said to be linearly independent if
of vectors in a Hilbert space is said to be linearly independent if

It is easy to see that any finite orthonormal set  is linear independent. The converse is also true.
is linear independent. The converse is also true.
Proposition 2.9. (Gram-Schmidt) If contains a linearly independent set of cardinality 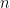 , then it contains an orthonormal set of cardinality
, then it contains an orthonormal set of cardinality 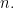
From here we establish the equivalence of Definition 2.7 and the standard definition of dimension.
Theorem 2.10. A Hilbert space has dimension  if and only if it contains an orthonormal set of cardinality and does not contain an orthonormal set of cardinality
if and only if it contains an orthonormal set of cardinality and does not contain an orthonormal set of cardinality 



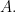











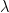










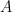













 and the quantum computational category focused on contrasting
and the quantum computational category focused on contrasting  with
with  We have seen already that
We have seen already that
 and an exponential function of
and an exponential function of  Of course, the cardinality of
Of course, the cardinality of  is infinite, but its quantum cardinality,
is infinite, but its quantum cardinality,
 and a linear function of
and a linear function of 


 The cardinality of
The cardinality of  may be called the rank of the set function
may be called the rank of the set function  if and only if
if and only if  if and only if
if and only if 

 is larger. On the other hand, the concept of rank itself is an elementary combinatorial notion, and one can find an explicit formula for the number of rank
is larger. On the other hand, the concept of rank itself is an elementary combinatorial notion, and one can find an explicit formula for the number of rank  morphisms in
morphisms in 

 The rank of the linear transformation
The rank of the linear transformation  . The rank of
. The rank of  and this bound is achieved if and only if
and this bound is achieved if and only if 
 of full rank morphisms in
of full rank morphisms in  the operator norm and the Frobenius norm, and we did not specify which is being used in Theorem 4.1. This is because these two norms generate the same topology, as do all norms on a finite-dimensional vector space.
the operator norm and the Frobenius norm, and we did not specify which is being used in Theorem 4.1. This is because these two norms generate the same topology, as do all norms on a finite-dimensional vector space.
 is called the nullity of
is called the nullity of 
 Consider the associated orthogonal decompositions,
Consider the associated orthogonal decompositions,
 This result is purely algebraic, and does not involve in the Hilbert space structure on
This result is purely algebraic, and does not involve in the Hilbert space structure on  which are quantizations of set maps, i.e. the case where
which are quantizations of set maps, i.e. the case where  for
for  In this case, using purely combinatorial reasoning, one can construct an orthonormal basis for
In this case, using purely combinatorial reasoning, one can construct an orthonormal basis for  has a very explicit description in terms of the combinatorial statistics of the underlying set function
has a very explicit description in terms of the combinatorial statistics of the underlying set function 
 we started to compare the two. This comparison begins with matrices: matrices over
we started to compare the two. This comparison begins with matrices: matrices over  suffice to encode both objects and morphisms in
suffice to encode both objects and morphisms in  i.e. made into something more than a set. First, the existence of a vector space structure on
i.e. made into something more than a set. First, the existence of a vector space structure on  be orthonormal bases, which is the same thing as saying
be orthonormal bases, which is the same thing as saying  What we showed is that
What we showed is that  Indeed, for each
Indeed, for each  define a corresponding elementary transformation
define a corresponding elementary transformation  by
by
 is a basis of
is a basis of 
 of
of  Indeed, for any
Indeed, for any  we have that
we have that
 are unit vectors. Thus, each morphism in the elementary basis
are unit vectors. Thus, each morphism in the elementary basis  of
of 



 This points us to a much better norm on
This points us to a much better norm on 
 of
of  are Lipschitz functions. Definition 3.1 does not care that we used orthonormal bases of
are Lipschitz functions. Definition 3.1 does not care that we used orthonormal bases of  coincides with the operator norm.
coincides with the operator norm. we have
we have

 on
on 
 and
and  would we have arrived at the same Hermitian form on
would we have arrived at the same Hermitian form on  is basis independent, like the operator norm
is basis independent, like the operator norm  , or whether it is basis dependent, like
, or whether it is basis dependent, like 
 such that
such that  for every
for every 
 is automatically an automorphism. Isometric automorphisms of
is automatically an automorphism. Isometric automorphisms of  then again an isometry
then again an isometry  are not the same, just like the matrix of set isomorphism
are not the same, just like the matrix of set isomorphism  is a unitary operator if and only if the image
is a unitary operator if and only if the image  of an orthonormal basis
of an orthonormal basis  is an orthonormal basis of
is an orthonormal basis of 


 we have
we have
 we are dealing with the dual space of
we are dealing with the dual space of  be the
be the  let
let  be their
be their  be the
be the ![f \in \mathrm{Hom}(X,Y) \iff \left[ (x,y_1)\in f \text{ and } (x,y_2) \in f \implies y_1=y_2\right].](https://s0.wp.com/latex.php?latex=f+%5Cin+%5Cmathrm%7BHom%7D%28X%2CY%29+%5Ciff+%5Cleft%5B+%28x%2Cy_1%29%5Cin+f+%5Ctext%7B+and+%7D+%28x%2Cy_2%29+%5Cin+f+%5Cimplies+y_1%3Dy_2%5Cright%5D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 to denote
to denote 


 A function which is both injective and surjective is called
A function which is both injective and surjective is called ![[n]=\{1,\dots,n\},](https://s0.wp.com/latex.php?latex=%5Bn%5D%3D%5C%7B1%2C%5Cdots%2Cn%5C%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002) where
where ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=FFFFFF&fg=000&s=0&c=20201002) and
and ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=FFFFFF&fg=000&s=0&c=20201002) are isomorphic if and only if
are isomorphic if and only if  in which case
in which case ![[m]=[n].](https://s0.wp.com/latex.php?latex=%5Bm%5D%3D%5Bn%5D.&bg=FFFFFF&fg=000&s=0&c=20201002) Thus, the
Thus, the  of
of ![\mathrm{Hom}(X,[n])](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BHom%7D%28X%2C%5Bn%5D%29&bg=FFFFFF&fg=000&s=0&c=20201002) contains an isomorphism. This natural number is called the
contains an isomorphism. This natural number is called the  Let
Let  and
and  prove that
prove that  Let
Let 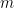 and
and 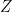 be a set, not necessarily finite.
be a set, not necessarily finite.
![\mathrm{Hom}([m] \times [n],Z).](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BHom%7D%28%5Bm%5D+%5Ctimes+%5Bn%5D%2CZ%29.&bg=FFFFFF&fg=000&s=0&c=20201002)
![M \in \mathrm{Hom}([m] \times [n],Z)](https://s0.wp.com/latex.php?latex=M+%5Cin+%5Cmathrm%7BHom%7D%28%5Bm%5D+%5Ctimes+%5Bn%5D%2CZ%29&bg=FFFFFF&fg=000&s=0&c=20201002) , the notation
, the notation  is used for its values, and we write
is used for its values, and we write  instead of
instead of ![\mathrm{Hom}([m] \times [n],Z)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BHom%7D%28%5Bm%5D+%5Ctimes+%5Bn%5D%2CZ%29&bg=FFFFFF&fg=000&s=0&c=20201002) for the set of
for the set of 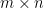 matrices over
matrices over  This is because matrices
This is because matrices  are typically thought of as two-dimensional arrays populated by elements of
are typically thought of as two-dimensional arrays populated by elements of 

 are called column matrices because they are visualized as arrays consisting of a single column,
are called column matrices because they are visualized as arrays consisting of a single column,
 are called row matrices because they are visualized as arrays consisting of a single row,
are called row matrices because they are visualized as arrays consisting of a single row,
 which are called
which are called  is a finite set, binary matrices are morphisms in
is a finite set, binary matrices are morphisms in ![\mathrm{Hom}([n],X)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BHom%7D%28%5Bn%5D%2CX%29&bg=FFFFFF&fg=000&s=0&c=20201002) contains an isomorphism
contains an isomorphism  An isomorphism
An isomorphism ![g \in \mathrm{Hom}([n],X)](https://s0.wp.com/latex.php?latex=g+%5Cin+%5Cmathrm%7BHom%7D%28%5Bn%5D%2CX%29&bg=FFFFFF&fg=000&s=0&c=20201002) is referred to as an ordering of
is referred to as an ordering of 
![[] \in \mathrm{Hom}(X,B^{n \times 1})](https://s0.wp.com/latex.php?latex=%5B%5D+%5Cin+%5Cmathrm%7BHom%7D%28X%2CB%5E%7Bn+%5Ctimes+1%7D%29&bg=FFFFFF&fg=000&s=0&c=20201002) by
by![[x_1]=\begin{bmatrix} 1 \\ 0 \\ \vdots \\ 0\end{bmatrix}, [x_2]=\begin{bmatrix} 0 \\ 1 \\ \vdots \\ 0\end{bmatrix},\dots,[x_n]=\begin{bmatrix} 0 \\ 0 \\ \vdots \\ 1\end{bmatrix}.](https://s0.wp.com/latex.php?latex=%5Bx_1%5D%3D%5Cbegin%7Bbmatrix%7D+1+%5C%5C+0+%5C%5C+%5Cvdots+%5C%5C+0%5Cend%7Bbmatrix%7D%2C+%5Bx_2%5D%3D%5Cbegin%7Bbmatrix%7D+0+%5C%5C+1+%5C%5C+%5Cvdots+%5C%5C+0%5Cend%7Bbmatrix%7D%2C%5Cdots%2C%5Bx_n%5D%3D%5Cbegin%7Bbmatrix%7D+0+%5C%5C+0+%5C%5C+%5Cvdots+%5C%5C+1%5Cend%7Bbmatrix%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 and the output
and the output ![[x]](https://s0.wp.com/latex.php?latex=%5Bx%5D&bg=FFFFFF&fg=000&s=0&c=20201002) is called the column matrix of
is called the column matrix of  respectively, and let
respectively, and let 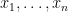 and
and  be orderings of these sets. Using these orderings, we can define an injective function
be orderings of these sets. Using these orderings, we can define an injective function ![[] \in \mathrm{Hom}(\mathrm{Hom}(X,Y),B^{m \times n})](https://s0.wp.com/latex.php?latex=%5B%5D+%5Cin+%5Cmathrm%7BHom%7D%28%5Cmathrm%7BHom%7D%28X%2CY%29%2CB%5E%7Bm+%5Ctimes+n%7D%29&bg=FFFFFF&fg=000&s=0&c=20201002) by
by![[f]_{ij} = \begin{cases} 1, \text{ if }f(x_j)=y_i \\ 0, \text{ otherwise}. \end{cases}.](https://s0.wp.com/latex.php?latex=%5Bf%5D_%7Bij%7D+%3D+%5Cbegin%7Bcases%7D+1%2C+%5Ctext%7B+if+%7Df%28x_j%29%3Dy_i+%5C%5C+0%2C+%5Ctext%7B+otherwise%7D.+%5Cend%7Bcases%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
![] \in \mathrm{Hom}(\mathrm{Hom}(X,Y),B^{m \times n})](https://s0.wp.com/latex.php?latex=%5D+%5Cin+%5Cmathrm%7BHom%7D%28%5Cmathrm%7BHom%7D%28X%2CY%29%2CB%5E%7Bm+%5Ctimes+n%7D%29&bg=FFFFFF&fg=000&s=0&c=20201002) is called the binary encoding of
is called the binary encoding of ![[f]](https://s0.wp.com/latex.php?latex=%5Bf%5D&bg=FFFFFF&fg=000&s=0&c=20201002) may be equivalently stated as follows: for each
may be equivalently stated as follows: for each  column
column 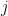 of
of ![[f(x_j)]](https://s0.wp.com/latex.php?latex=%5Bf%28x_j%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002) relative to the ordering
relative to the ordering  be three finite sets of cardinalities
be three finite sets of cardinalities  respectively. Let
respectively. Let  be orderings of these sets. Let
be orderings of these sets. Let  be given functions, and let
be given functions, and let  be their
be their ![[f] \in B^{m \times n},\ [g] \in B^{l \times m},\ [g \circ f] \in B^{l \times n},](https://s0.wp.com/latex.php?latex=%5Bf%5D+%5Cin+B%5E%7Bm+%5Ctimes+n%7D%2C%5C+%5Bg%5D+%5Cin+B%5E%7Bl+%5Ctimes+m%7D%2C%5C+%5Bg+%5Ccirc+f%5D+%5Cin+B%5E%7Bl+%5Ctimes+n%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 and
and  relative to the given orderings of
relative to the given orderings of 
 defined by
defined by ![M=\sum\limits_{k=1}^m [g]_{ik}[f]_{kj}](https://s0.wp.com/latex.php?latex=M%3D%5Csum%5Climits_%7Bk%3D1%7D%5Em+%5Bg%5D_%7Bik%7D%5Bf%5D_%7Bkj%7D&bg=FFFFFF&fg=000&s=0&c=20201002)
 and that
and that ![[g \circ f]=M.](https://s0.wp.com/latex.php?latex=%5Bg+%5Ccirc+f%5D%3DM.&bg=FFFFFF&fg=000&s=0&c=20201002)

 be the corresponding singular values: the restriction of
be the corresponding singular values: the restriction of  has the form
has the form  where
where  is an isometric isomorphism. As a decomposition of
is an isometric isomorphism. As a decomposition of 
 is the orthogonal projection of
is the orthogonal projection of  is an orthogonal set in
is an orthogonal set in 

 into a direct sum of orthogonal lines instead of incorporating the multiplicity factor
into a direct sum of orthogonal lines instead of incorporating the multiplicity factor  The two ways of thinking about the SVD — blocks and lines — are both correct, but we have to keep in mind that the block decomposition is unique whereas the line decomposition is only unique when the number
The two ways of thinking about the SVD — blocks and lines — are both correct, but we have to keep in mind that the block decomposition is unique whereas the line decomposition is only unique when the number 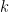 of singular values
of singular values  is equal to the rank of
is equal to the rank of  is the morphism
is the morphism  defined by
defined by
 is the orthogonal projection of
is the orthogonal projection of 
 comes to us as an isometric isomorphism. Then, the singular value decompositions of
comes to us as an isometric isomorphism. Then, the singular value decompositions of 

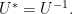
 Geometrically, this just says that swapping left and right singular blocks twice is the same as not swapping them at all.
Geometrically, this just says that swapping left and right singular blocks twice is the same as not swapping them at all. and
and  In this setting there are two further coincidences that could potentially occur: the left and right singular blocks of
In this setting there are two further coincidences that could potentially occur: the left and right singular blocks of  or
or  In the first case we say that
In the first case we say that 


 in
in  I have not yet succeeded in finding such an argument, and while I plan to try again on my own time you may be getting tired of me constantly turning things upside down and inside out and generally treating linear algebra results we can look up as if they were open research problems. If so, you may have given up on Math 202A, which is fine with me provided you are working on the mathematics that matters to you. I mean this sincerely and will extend the following provision: if you have fallen behind on 202A homework sets because you are composing your mathematical opus, you can turn in that work for homework credit in 202A.
I have not yet succeeded in finding such an argument, and while I plan to try again on my own time you may be getting tired of me constantly turning things upside down and inside out and generally treating linear algebra results we can look up as if they were open research problems. If so, you may have given up on Math 202A, which is fine with me provided you are working on the mathematics that matters to you. I mean this sincerely and will extend the following provision: if you have fallen behind on 202A homework sets because you are composing your mathematical opus, you can turn in that work for homework credit in 202A.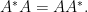
 is selfadjoint. Then, because
is selfadjoint. Then, because 
 is an isometric automorphism of
is an isometric automorphism of  The same reasoning applied to
The same reasoning applied to  gives
gives
 we have
we have 
 we can cancel it to get
we can cancel it to get


 , and since
, and since  Combining these gives
Combining these gives  and we conclude that a selfadjoint unitary operator
and we conclude that a selfadjoint unitary operator 
 is the identity operator on
is the identity operator on  and latex
and latex  and in fact all solutions are mixtures of these two. More precisely, let
and in fact all solutions are mixtures of these two. More precisely, let 


 and
and  are nonzero subspaces, as the examples
are nonzero subspaces, as the examples  already show.
already show. 
 with
with 
 as multiplication by
as multiplication by  acts in
acts in  as multiplication by
as multiplication by  In words, the condition that
In words, the condition that  and since
and since  is nonzero.
is nonzero.
 are nonzero subspaces such that
are nonzero subspaces such that
 are nonzero real numbers. Each
are nonzero real numbers. Each  is a signed singular block of
is a signed singular block of  and each
and each 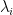 is a signed singular value of
is a signed singular value of  and orthogonal decompositions
and orthogonal decompositions
 are the left singular blocks of
are the left singular blocks of  are the right singular blocks of
are the right singular blocks of  are the singular values of
are the singular values of  is the singular spectrum of
is the singular spectrum of  the positive number
the positive number  is the multiplicity of the singular value
is the multiplicity of the singular value  and if this number is equal to one we say that
and if this number is equal to one we say that  distinct singular values
distinct singular values  . In this case, the left singular blocks
. In this case, the left singular blocks  are one-dimensional subspaces and we call them the left singular lines of
are one-dimensional subspaces and we call them the left singular lines of  are one-dimensional subspaces of
are one-dimensional subspaces of  the right singular lines of
the right singular lines of  positive numbers
positive numbers 

 the block and line forms of the SVD are literally the same statement. However, when
the block and line forms of the SVD are literally the same statement. However, when  , they are not, because the line form becomes ambiguous: there is at least one
, they are not, because the line form becomes ambiguous: there is at least one  such that we are decomposing each of the singular blocks
such that we are decomposing each of the singular blocks  into a direct sum of orthogonal lines, and these decompositions can be performed arbitrarily and independently. I have generally been pretty sloppy about accounting for this, because it almost never happens.
into a direct sum of orthogonal lines, and these decompositions can be performed arbitrarily and independently. I have generally been pretty sloppy about accounting for this, because it almost never happens. of morphisms with simple singular spectrum is a dense open set in
of morphisms with simple singular spectrum is a dense open set in  is one-dimensional is an operator norm dense open set in
is one-dimensional is an operator norm dense open set in  a morphism with simple singular spectrum. Theorem 2.3 is an extra incantation which mystically causes these results to hold on all of
a morphism with simple singular spectrum. Theorem 2.3 is an extra incantation which mystically causes these results to hold on all of  Let
Let 
 and
and 
 is the operator
is the operator

 satisfy
satisfy 
 is the identity operator. We thus have
is the identity operator. We thus have

 in the upstairs SVD of
in the upstairs SVD of 

 is the operator
is the operator






 is the morphism
is the morphism

 is
is 
 is once again the SV-weighted sum of orthogonal projections onto the left singular lines of
is once again the SV-weighted sum of orthogonal projections onto the left singular lines of 
 and
and  are given by weighted projection sums
are given by weighted projection sums
 of endomorphisms of an underlying Hilbert space
of endomorphisms of an underlying Hilbert space  be any two finite-dimensional Hilbert spaces, and let
be any two finite-dimensional Hilbert spaces, and let 
 is the rank of
is the rank of  are lines, the numbers
are lines, the numbers  are positive, and the restrictions
are positive, and the restrictions  are of the form
are of the form  with
with 
 and second it refers to a corresponding decomposition of the transformation
and second it refers to a corresponding decomposition of the transformation 
 is the orthogonal projection of
is the orthogonal projection of  The best way to consider this operator decomposition is an orthogonal decomposition of
The best way to consider this operator decomposition is an orthogonal decomposition of  the coordinates of
the coordinates of  ,
,


 and
and  are unitary operators then the Frobenius scalar product satisfies
are unitary operators then the Frobenius scalar product satisfies
 ,
,
 is an orthonormal set in
is an orthonormal set in  and let
and let  This means that, for each
This means that, for each  we have
we have

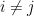 and consider the scalar product
and consider the scalar product 
 , so
, so  is the zero vector in
is the zero vector in  is the zero vector in
is the zero vector in  but we can extend the orthonormal set
but we can extend the orthonormal set  to an orthonormal basis, relative to the Frobenius scalar product. Then, the SVD simply says that the singular values of
to an orthonormal basis, relative to the Frobenius scalar product. Then, the SVD simply says that the singular values of 
 of two morphisms
of two morphisms  to its
to its  th largest singular value (so there are
th largest singular value (so there are  of these functionals). These functionals are nonlinear and it is difficult to say much about them in general. One thing we can say immediately is that
of these functionals). These functionals are nonlinear and it is difficult to say much about them in general. One thing we can say immediately is that 
 is the operator norm of
is the operator norm of 

 has the form
has the form  Corresponding to this, we have an “upstairs” decomposition
Corresponding to this, we have an “upstairs” decomposition
 and
and  of the Hilbert space
of the Hilbert space ![[A]_{\{E_i\}}=\begin{bmatrix} \sigma_1 \\ \vdots \\ \sigma_r \\ 0 \\ \vdots \\ 0 \end{bmatrix}.](https://s0.wp.com/latex.php?latex=%5BA%5D_%7B%5C%7BE_i%5C%7D%7D%3D%5Cbegin%7Bbmatrix%7D+%5Csigma_1+%5C%5C+%5Cvdots+%5C%5C+%5Csigma_r+%5C%5C+0+%5C%5C+%5Cvdots+%5C%5C+0+%5Cend%7Bbmatrix%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 the vector
the vector  defined by
defined by 
![[A_q]_{\{E_i\}}=\begin{bmatrix} \sigma_1 \\ \vdots \\ \sigma_q \\ 0 \\ \vdots \\ 0 \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5BA_q%5D_%7B%5C%7BE_i%5C%7D%7D%3D%5Cbegin%7Bbmatrix%7D+%5Csigma_1+%5C%5C+%5Cvdots+%5C%5C+%5Csigma_q+%5C%5C+0+%5C%5C+%5Cvdots+%5C%5C+0+%5Cend%7Bbmatrix%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 Remembering that
Remembering that  are morphism and not just inert vectors, we ask: what is the significance of
are morphism and not just inert vectors, we ask: what is the significance of  as a linear transformation from
as a linear transformation from  morphisms in
morphisms in  is any morphism of rank
is any morphism of rank  in Frobenius norm.
in Frobenius norm.
 Our task is to demonstrate that if
Our task is to demonstrate that if  then
then
 be a point in the Grassmannian of
be a point in the Grassmannian of 
 where
where  is the orthogonal projection of
is the orthogonal projection of 
 is called the compression of
is called the compression of  and by construction it has rank
and by construction it has rank  It remains now to optimize the functional
It remains now to optimize the functional 
 To do this we will express
To do this we will express  in terms of the singular data of
in terms of the singular data of  and
and  be ordered orthonormal bases adapted to the downstairs decompositions
be ordered orthonormal bases adapted to the downstairs decompositions
 and
and  are orthonormal bases of
are orthonormal bases of 
 are left singular vectors for
are left singular vectors for  are right singular vectors for
are right singular vectors for  in
in  form an orthonormal basis of the kernel of
form an orthonormal basis of the kernel of  in
in  form an orthonormal basis for the complement of the image of
form an orthonormal basis for the complement of the image of  we associate the compression numbers
we associate the compression numbers  defined as the norms
defined as the norms
 is in fact independent of which unit vector
is in fact independent of which unit vector  we sample from the line
we sample from the line  since any other unit sample from
since any other unit sample from  with nonnegativity due to the fact that these numbers are norms, and the upper bound due to the fact that they are norms of projections of unit vectors. In fact, there is one more constraint on the compression numbers of a
with nonnegativity due to the fact that these numbers are norms, and the upper bound due to the fact that they are norms of projections of unit vectors. In fact, there is one more constraint on the compression numbers of a 


 is at most the Frobenius norm of
is at most the Frobenius norm of 



 realize the above maximizer, and that the corresponding compression is
realize the above maximizer, and that the corresponding compression is 