This course is the second quarter of Math 202, a three-quarter graduate course sequence in applied algebra at UCSD. Briefly, the 202 sequence is arranged as follows.
Math 202A (Fall): vectors and transformations.
Math 202B (Winter): algebras and representations.
Math 202C (Spring): tensors and invariants.
In Math 202B, the term “vector space” will always mean a finite-dimensional complex vector space.
Definition 1.1. An algebra is a vector space 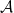 of positive dimension equipped with an associative, bilinear, unital multiplication and an antilinear, antimultiplicative, involutive conjugation.
of positive dimension equipped with an associative, bilinear, unital multiplication and an antilinear, antimultiplicative, involutive conjugation.
The prototypical example of an algebra is  , the complex number system, elements of which are called scalars and denoted by lower-case Greek letters,
, the complex number system, elements of which are called scalars and denoted by lower-case Greek letters,

There are some exceptions: integers like zero and one are denoted  and
and 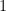 as usual, and we write
as usual, and we write  for the imaginary unit. Elements of a general algebra are denoted by upper-case Roman letters,
for the imaginary unit. Elements of a general algebra are denoted by upper-case Roman letters,

Multiplication in is a function  whose values are denoted by concatenating its arguments:
whose values are denoted by concatenating its arguments:  . Associativity means that the symbol
. Associativity means that the symbol  is unambiguous because its two possible meanings coincide:
is unambiguous because its two possible meanings coincide:

Bilinearity means that multiplication in interacts with its vector space structure according to the rule

We do not assume multiplication is commutative.
Problem 1.1. Let  denote the zero vector in . Prove that
denote the zero vector in . Prove that  for all
for all  .
.
Later, when we are more familiar with algebras and there is less chance of confusion, we will sometimes omit the subscript and write for the zero vector in a general algebra  as it will generally be clear from context whether this symbol represents a scalar or a vector.
as it will generally be clear from context whether this symbol represents a scalar or a vector.
Unital means that there exists a vector  such that
such that

for all . Any such vector is called a multiplicative unit. Note that because the dimension of is positive, any multiplicative unit 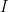 is distinct from the additive unit
is distinct from the additive unit  In fact, there is only one multiplicative unit.
In fact, there is only one multiplicative unit.
Problem 1.2. Let  be multiplicative units in . Prove that
be multiplicative units in . Prove that  .
.
Henceforth we write  for the unique multiplicative unit. Later on, we may omit the subscript and simply write for the multiplicative unit if it causes no confusion to do so. An element is said to be invertible if there exists
for the unique multiplicative unit. Later on, we may omit the subscript and simply write for the multiplicative unit if it causes no confusion to do so. An element is said to be invertible if there exists  such that
such that  .
.
Problem 1.3. Suppose  are such that and
are such that and  . Prove that
. Prove that  .
.
When we say that  is the inverse of
is the inverse of 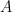 , and that is the inverse of
, and that is the inverse of  This is written
This is written  and
and  .
.
Multiplication in an algebra can be described numerically as follows. Let  be a vector space basis of indexed by the points of some finite nonempty set
be a vector space basis of indexed by the points of some finite nonempty set  Then,
Then,  can be represented as a linear combinations
can be represented as a linear combinations

According to bilinearity we have

Each product of basis vectors can also be resolved into a linear combination of basis vectors,

As the indices  range over
range over  we get a three dimensional array
we get a three dimensional array ![[\gamma_{xyz}]](https://s0.wp.com/latex.php?latex=%5B%5Cgamma_%7Bxyz%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of complex numbers called the multiplication tensor of relative to the basis
of complex numbers called the multiplication tensor of relative to the basis 
 The elements of this three-tensor are called the connection coefficients of relative to the basis
The elements of this three-tensor are called the connection coefficients of relative to the basis  This set of
This set of  numbers completely determines multiplication in , since
numbers completely determines multiplication in , since

From a practical perspective, one would like to find a vector space basis of such that the corresponding multiplication tensor is sparse, i.e. many connection coefficients are zero, so that the computational cost of performing multiplication is minimized – this is the basic idea behind Strassen’s algorithm for matrix multiplication.
Problem 1.4. Prove that a two-dimensional algebra must be commutative.
Conjugation is a function  whose values are denoted by a superscript asterisk:
whose values are denoted by a superscript asterisk:  . Antilinearity means that conjugation interacts with the vector space operations according to the rule
. Antilinearity means that conjugation interacts with the vector space operations according to the rule

Antimultiplicativity means that conjugation interacts with multiplication according to the rule

Involutive means that conjugation is 2-periodic,

Just like multiplication, conjugation in can be described with respect to a linear basis Indeed, for each basis vector we can write its conjugate as

This gives a two-dimensional array which completely describes conjugation in , the conjugation tensor ![[\eta_{xy}]](https://s0.wp.com/latex.php?latex=%5B%5Ceta_%7Bxy%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) relative to the the basis For any
relative to the the basis For any

then

Problem 1.5. Prove that the set  of invertible elements in an algebra is a multiplicative group. Moreover, prove that is closed under conjugation: is invertible if and only if
of invertible elements in an algebra is a multiplicative group. Moreover, prove that is closed under conjugation: is invertible if and only if  is invertible, and in fact
is invertible, and in fact  .
.
In any algebra , we define the following element classes:
- Selfadjoint:
 .
.
- Idempotent:
 .
.
- Unitary:
 .
.
- Normal :
 .
.
Problem 1.6. Prove the the set  of all selfadjoint elements in an algebra is an additive group, and in fact a real vector space. Show that every can be written uniquely in the form
of all selfadjoint elements in an algebra is an additive group, and in fact a real vector space. Show that every can be written uniquely in the form  with
with 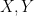 selfadjoint. We say that is the real part of , and that
selfadjoint. We say that is the real part of , and that 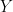 is its imaginary part.
is its imaginary part.
Definition 1.2. A nonzero selfadjoint idempotent  is called a projection. Projections
is called a projection. Projections  are said to be orthogonal if
are said to be orthogonal if 
Sets of pairwise orthogonal projections play an important role in the study of algebras.
Theorem 1.1. Any set of pairwise orthogonal projections in an algebra is linearly independent.
Proof: Let be a set of pairwise orthogonal projections in indexed by the elements of some set Thus  are such that
are such that  where
where  is the Kronecker delta. Let
is the Kronecker delta. Let

be a vector in the span of Then, for any  we have
we have

Thus if  we must have
we must have  for each
for each
-QED
According to Theorem 1.1, the maximum cardinality of a set of pairwise orthogonal projections in is 
Definition 1.3. A basis of consisting of pairwise orthogonal projections is called a Fourier basis.
If admits a Fourier basis, it is a commutative algebra, and the corresponding conjugation and multiplication tensors are the two- and three-dimensional identity matrices. In this sense, algebras which admit a Fourier basis are the simplest algebras.
Theorem 1.2. Let be a Fourier basis of  Then,
Then,

Proof: Take any and let
be its expansion in the given basis. Then, we have

and

By uniqueness of the multiplicative unit in , we conclude that 
-QED
Just as selfadjoint elements in are analogous to real numbers, unitary elements in are analogous to complex numbers of modulus one.
Problem 1.8. Prove that the set  of all unitary elements in is a subgroup of . We call the unitary group of
of all unitary elements in is a subgroup of . We call the unitary group of
As for normal elements, these are in bijection with pairs of commuting selfadjoint elements.
Theorem 1.3. Given , let  be its decomposition into real and imaginary parts. Then is normal if and only if and commute.
be its decomposition into real and imaginary parts. Then is normal if and only if and commute.
Proof: Suppose first that and are commuting selfadjoint elements. We will prove that is normal. We have

and

so

Now suppose that is a normal element. We have

and

The two expressions agree: 
-QED
Commutativity of real and imaginary parts characterizes normalcy at the level of elements. Normalcy itself characterizes commutativity at the level of algebras.
Theorem 1.4. An algebra is commutative if and only if all its elements are normal.
Proof: One direction is obvious: if is a commutative algebra, then certainly every element commutes with its conjugate.
Conversely, suppose that every element of is normal. Let  be any two selfadjoint elements, and set . Then, since is normal, we have
be any two selfadjoint elements, and set . Then, since is normal, we have

which shows that Since were arbitrary selfadjoint elements of , we have shown that any two selfadjoint elements of commute. It remains to show that  commute even if they are not selfadjoint. Then we can write
commute even if they are not selfadjoint. Then we can write  and
and  where
where  are selfadjoint and thus commute with one another. Thus,
are selfadjoint and thus commute with one another. Thus,

and

are equal.
-QED
Now let us consider functions between possibly different algebras and 
Definition 1.4. A linear transformation  is said to be an algebra homomorphism if
is said to be an algebra homomorphism if

and

and moreover

We say that and 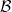 are isomorphic if there is which is both a vector space isomorphism and an algebra homomorphism; such a map is called an algebra isomorphism.
are isomorphic if there is which is both a vector space isomorphism and an algebra homomorphism; such a map is called an algebra isomorphism.
The word “isomorphic” means “same shape” in Greek. Two objects which have the same shape need not be the same in all ways, and similarly saying that two algebras are isomorphic should not be taken to mean that they are the same set. To emphasize this distinction, one writes  to indicate that and are isomorphic algebras.
to indicate that and are isomorphic algebras.
Problem 1.9. Prove that every one-dimensional algebra is isomorphic to the complex number system 
As stipulated above, all vector spaces (and hence all algebras) in Math 202B are defined over You may wonder about algebras with real scalars, and as we now explain these can be naturally included in our framework. Let be a real algebra, i.e. a finite-dimensional vector space over  together with an associative, bilinear, unital multiplication and a linear, involutive conjugation.
together with an associative, bilinear, unital multiplication and a linear, involutive conjugation.
Definition 1.5. The complexification of is the algebra whose elements are ordered pairs of elements  We write
We write  as and define algebraic operations in from those in as follows: for
as and define algebraic operations in from those in as follows: for  and
and  we declare
we declare




Problem 1.10. Prove that Definition 1.5 does indeed define an algebra in the sense of Definition 1.1.
We say that an element of the complexificiation of a real algebra is real if it has the form  for some
for some 
Theorem 1.5. The complexification of a real algebra is commutative if every real element of is selfadjoint.
Proof: Let  and
and  be real elements of Then, the product
be real elements of Then, the product  is also a real element of . By hypothesis,
is also a real element of . By hypothesis,  and
and  are selfadjoint elements of and therefore
are selfadjoint elements of and therefore

Now writing  we have that the real part of is
we have that the real part of is  and its imaginary part is
and its imaginary part is  Since
Since  commute, is normal, by Theorem 1.3. Thus every element of is normal, hence is commutative by Theorem 1.4.
commute, is normal, by Theorem 1.3. Thus every element of is normal, hence is commutative by Theorem 1.4.
-QED

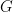




























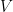



































 is just a homomorphic image of
is just a homomorphic image of  of
of  for some given Hilbert space
for some given Hilbert space  Then, Burnside’s theorem says that either
Then, Burnside’s theorem says that either  or there is a proper non-trivial subspace
or there is a proper non-trivial subspace  invariant under all operators
invariant under all operators  In this situation,
In this situation,  is defined by declaring
is defined by declaring  to be the restriction of
to be the restriction of  In the case where
In the case where  the pair
the pair  is a linear representation of
is a linear representation of  the identity homomorphism; this is called the tautological representation or defining representation of
the identity homomorphism; this is called the tautological representation or defining representation of 
 are representations of
are representations of  is said to be a homomorphism of representations (or an intertwining transformation) if
is said to be a homomorphism of representations (or an intertwining transformation) if 

 is a vector subspace of the space
is a vector subspace of the space  of all linear transformations
of all linear transformations 
 is said to be an isomorphism of representations. When such an intertwining linear isomorphism exists, we say that
is said to be an isomorphism of representations. When such an intertwining linear isomorphism exists, we say that  of
of  of
of  -basis of
-basis of  in the
in the  -basis of
-basis of  for every algebra element
for every algebra element 
 , which is a subalgebra of
, which is a subalgebra of  is the subalgebra consisting of all operators
is the subalgebra consisting of all operators  that commute with every operator
that commute with every operator 

 if and only if
if and only if  which is exactly the condition for
which is exactly the condition for 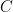 to be an element of
to be an element of 

 we have the following.
we have the following.
 is the centralizer of
is the centralizer of  the statement is equivalent to the fact that the center of
the statement is equivalent to the fact that the center of  We claim that
We claim that  is a
is a  -invariant subspace of
-invariant subspace of  then for any
then for any 
 is again in
is again in  Since
Since  or
or  and since
and since  is a
is a  -invariant subspace of
-invariant subspace of  Indeed, suppose
Indeed, suppose  i.e.
i.e.  for
for  Then, for any
Then, for any 
 remains in the image of
remains in the image of  as claimed.
as claimed.

 be any function on
be any function on 
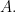 Taking the left regular representation, we have
Taking the left regular representation, we have
 is the linear operator on the Hilbert space
is the linear operator on the Hilbert space  given by the image of the Fourier basis vector
given by the image of the Fourier basis vector  under the injective algebra homomorphism
under the injective algebra homomorphism  In other words,
In other words, 
 and
and 
 This says that the operators
This says that the operators  making up the image of the commutative algebra
making up the image of the commutative algebra  and moreover that calculating the eigenvalues of the operator
and moreover that calculating the eigenvalues of the operator  is the same thing as calculating the Fourier transform of the function
is the same thing as calculating the Fourier transform of the function 

 Hint: show that every
Hint: show that every 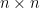 circulant matrix is the image of a function on the cyclic group of order
circulant matrix is the image of a function on the cyclic group of order 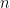 in the regular representation.
in the regular representation. 
 , every partition of
, every partition of  is called a class function if it is constant on conjugacy classes, meaning that
is called a class function if it is constant on conjugacy classes, meaning that  for all
for all 
 for all
for all 

 belongs to
belongs to  if and only if it is constant on conjugacy classes.
if and only if it is constant on conjugacy classes. For any
For any  , we have
, we have = \sum\limits_{h \in G} A(gh^{-1})B(h) = \sum\limits_{h \in G} A(g(gh)^{-1}) B(gh) = \sum\limits_{h \in G} A(gh^{-1}g^{-1})B(gh),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7D%29B%28h%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28g%28gh%29%5E%7B-1%7D%29+B%28gh%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7Dg%5E%7B-1%7D%29B%28gh%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 simply permutes the terms of the sum. Continuing the calculation, we have
simply permutes the terms of the sum. Continuing the calculation, we have = \sum\limits_{h \in G} A(gh^{-1}g^{-1})B(gh) =\sum\limits_{h \in G} A(h^{-1})B(gh) = \sum\limits_{h \in G} B(gh)A(h^{-1}),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28gh%5E%7B-1%7Dg%5E%7B-1%7D%29B%28gh%29+%3D%5Csum%5Climits_%7Bh+%5Cin+G%7D+A%28h%5E%7B-1%7D%29B%28gh%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+B%28gh%29A%28h%5E%7B-1%7D%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \sum\limits_{h \in G} B(gh^{-1})A(h) = [BA](g),](https://s0.wp.com/latex.php?latex=%5BAB%5D%28g%29+%3D+%5Csum%5Climits_%7Bh+%5Cin+G%7D+B%28gh%5E%7B-1%7D%29A%28h%29+%3D+%5BBA%5D%28g%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 is a central function; we will prove it is constant on conjugacy classes. Since
is a central function; we will prove it is constant on conjugacy classes. Since 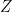 commutes with all functions in
commutes with all functions in  it commutes with every elementary function
it commutes with every elementary function  . Since
. Since = \sum\limits_{k \in G}Z(hk^{-1})E_g(k)=Z(hg^{-1}),](https://s0.wp.com/latex.php?latex=%5BZE_g%5D%28h%29+%3D+%5Csum%5Climits_%7Bk+%5Cin+G%7DZ%28hk%5E%7B-1%7D%29E_g%28k%29%3DZ%28hg%5E%7B-1%7D%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 = \sum\limits_{k\in G}E_g(hk^{-1})Z(k)=Z(g^{-1}h),](https://s0.wp.com/latex.php?latex=%5BE_gZ%5D%28h%29+%3D+%5Csum%5Climits_%7Bk%5Cin+G%7DE_g%28hk%5E%7B-1%7D%29Z%28k%29%3DZ%28g%5E%7B-1%7Dh%29%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 for all
for all  rather than
rather than 
 let
let  be the indicator function of
be the indicator function of  so
so 
 of
of 
 span the class algebra of
span the class algebra of  constant on conjugacy classes can be written
constant on conjugacy classes can be written
 denotes the value
denotes the value  for any
for any  We will show that
We will show that 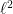 -scalar product on
-scalar product on 

 is a partition of
is a partition of 
 is an orthogonal (but not orthonormal) set of functions in
is an orthogonal (but not orthonormal) set of functions in ![[c_{\alpha\beta\gamma}]](https://s0.wp.com/latex.php?latex=%5Bc_%7B%5Calpha%5Cbeta%5Cgamma%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of
of  i.e.
i.e.  For any
For any  and any
and any  , show that
, show that
 counts solutions to the equation
counts solutions to the equation  in
in  is any particular point of the conjugacy class
is any particular point of the conjugacy class  and
and  are required to belong to
are required to belong to  and
and  respectively.
respectively.
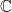 -valued functions on
-valued functions on  = A(x)B(x), \quad x \in X,](https://s0.wp.com/latex.php?latex=%5BAB%5D%28x%29+%3D+A%28x%29B%28x%29%2C+%5Cquad+x+%5Cin+X%2C&bg=FFFFFF&fg=000&s=0&c=20201002)

 are defined
are defined  define the corresponding elementary function
define the corresponding elementary function  by
by
 where
where =E_x(z)E_y(z)=\delta_{xz}\delta_{yz}=\delta_{xy}E_x(z).](https://s0.wp.com/latex.php?latex=%5BE_xE_y%5D%28z%29%3DE_x%28z%29E_y%28z%29%3D%5Cdelta_%7Bxz%7D%5Cdelta_%7Byz%7D%3D%5Cdelta_%7Bxy%7DE_x%28z%29.&bg=FFFFFF&fg=000&s=0&c=20201002)
 can be written as
can be written as



 are isomorphic.
are isomorphic. be a vector space basis of
be a vector space basis of  be the function algebra of this set, and define a linear transformation
be the function algebra of this set, and define a linear transformation
 , where
, where  is the elementary function corresponding to
is the elementary function corresponding to  . This is a vector space isomorphism, since it maps a basis of
. This is a vector space isomorphism, since it maps a basis of  is also an algebra homomorphism. Indeed, by Theorem 1.2 and linearity of
is also an algebra homomorphism. Indeed, by Theorem 1.2 and linearity of 
 Next,
Next,


 rather than
rather than  Thus,
Thus,
 so defined is an algebra isomorphism. Note that the Fourier transform on
so defined is an algebra isomorphism. Note that the Fourier transform on 

 The function
The function  is called the Fourier transform of the algebra element
is called the Fourier transform of the algebra element 
 is the product of
is the product of  is very simple, both conceptually and computationally.
is very simple, both conceptually and computationally.  of
of 
 is the smallest subalgebra of
is the smallest subalgebra of 
 are called central elements.
are called central elements. be any two central elements and
be any two central elements and  , we have
, we have


 .
.
 (maximally commutative, minimally noncommutative). Any algebra
(maximally commutative, minimally noncommutative). Any algebra  have the lowest commutativity index; such maximally noncommutative algebras are called
have the lowest commutativity index; such maximally noncommutative algebras are called  is the set of all elements in
is the set of all elements in 
 .
. is indeed a subalgebra of
is indeed a subalgebra of  are subalgebras of
are subalgebras of  then
then 
 and whose “largest” element is
and whose “largest” element is  , a relation on
, a relation on  of
of 
 to denote the membership of
to denote the membership of  in
in  For example, you are familiar with the notion of an
For example, you are familiar with the notion of an  with the following properties :
with the following properties : for all
for all  ;
; iff
iff  ;
; then
then  .
. for all
for all  and
and  then
then  ;
; and
and  then
then  .
. consisting of a set together with a partial order on it is called a
consisting of a set together with a partial order on it is called a  by definition means
by definition means  . Importantly, note the use of the adjective “partial” – Definition 2.3 allows for the possibility that there are pairs of elements
. Importantly, note the use of the adjective “partial” – Definition 2.3 allows for the possibility that there are pairs of elements  for which neither
for which neither  by inclusion:
by inclusion:
 , then
, then  subsets of
subsets of 

 is the largest subset of
is the largest subset of 

 is the smallest subset of
is the smallest subset of 
 set is the only subset of
set is the only subset of  . Similarly, the whole set
. Similarly, the whole set  is the only set satisfying
is the only set satisfying  to be the set of all vector subspaces of
to be the set of all vector subspaces of  is an
is an  as intersection, because the intersection of two subspaces is again a subspace. However, the union of two subspaces is not, and we have to modify the definition to
as intersection, because the intersection of two subspaces is again a subspace. However, the union of two subspaces is not, and we have to modify the definition to 
 , as the empty subset of
, as the empty subset of  to be the set of all subalgebras of
to be the set of all subalgebras of  is an induced subposet of
is an induced subposet of  of subalgebras of
of subalgebras of  into a lattice, because the span of the union
into a lattice, because the span of the union  of two subalgebras of
of two subalgebras of  , define
, define  to be the intersection of all subalgebras of
to be the intersection of all subalgebras of 
 be the set of all commutative subalgebras of
be the set of all commutative subalgebras of 
 This definition will fail if one of
This definition will fail if one of  with the following property: if
with the following property: if  , then
, then  .
.
 . If
. If  such that
such that  In this case, the algebra generated by
In this case, the algebra generated by  is a commutative subalgebra of
is a commutative subalgebra of  and this contradicts the maximality of
and this contradicts the maximality of  Then for a commutative subalgebra
Then for a commutative subalgebra  we have
we have
 (note that the conclusion of Problem 2.1 was used here) .
(note that the conclusion of Problem 2.1 was used here) .