Last lecture, we gave a definition of what it means for a Hilbert space to be finite-dimensional. Let be the category whose objects are finite-dimensional Hilbert spaces and whose morphisms are linear transformations. Note that we do not require maps in to interact with the scalar products on and in any particular way. This means that even though the objects in are both algebraic and geometric in nature, as described in Lecture 4, the morphisms of are only required to respect their algebraic structure.
Of course, we are free to consider special linear transformations in which do interact with the geometry of the source and target spaces. In particular, the following definition is quite important.
Definition 6.1. A transformation is said to be an isometry if for all
Thus an isometry is a linear transformation which preserves norms and hence distances.
Theorem 6.2. A transformation is an isometry if and only if for all
Proof: It is clear that if preserves scalar products it preserves norms. That the converse also holds follows from the fact that norms uniquely determine scalar products via polarization.
Proposition 6.3. If is an isometry then it is injective.
Proof: Suppose are such that . Then, and consequently
For any we define the kernel of by
Certainly you already know that is a subspace of . We will discuss subspaces in a systematic way soon. For now, let us simply note that in the course of the preceding argument we observed the following.
Proposition 6.4. A transformation is injective if and only if
Now let us discuss isomorphism in the category The general categorical definition is that two Hilbert spaces and are isomorphic if and only if there exists transformations and such that
where and are the identity operators on and , respectively. We showed already in a previous homework problem that is an isomorphism if and only if it is bijective. Here is a restatement of this as an extremal property of linear transformations.
Proposition 6.5. A transformation is an isomorphism if and only if its kernel is minimal and its image is maximal.
Now we come to the fact that dimension completely characterizes isomorphism in
Theorem 6.6. Two Hilbert spaces and are isomorphic if and only if they have the same dimension.
Proof: Suppose first that and are two Hilbert spaces of the same dimension, and let and be two orthonormal bases. Then Let be any bijective function (i.e. set isomorphism) and define a corresponding linear transformation
by
Since is a bijection from to , we also have
so that if and only if have the same coordinates relative to , in which case they are the same vector. Next, let be an arbitrary vector and let
be its coordinate expansion relative to the orthonormal basis . Then, the vector defined by
satisfies , whence is surjective as well as injective.
Conversely, suppose that and are linear transformations such that and where is the identity transformation of and is the identity transformation of Let be a basis of and consider the vectors in defined by
These vectors form the image of under in and we claim they are linearly independent. Indeed, suppose that
Then, applying to each side of this equation we get
whence for each Thus is a linearly independent set in of cardinality , so that . Applying exactly the same argument with in place of we get that We thus conclude
-QED
Having discussed isomorphisms in let us now consider isomorphisms which preserve geometric structure.
Definition 6.7. A transformation is called an isometric isomorphism if it is both an isometry and an isomorphism.
Isometric isomorphisms in are also referred to as unitary transformations. Since every isometry is injective we have the following.
Proposition 6.8. An isometry is an isomorphism if and only if it is surjective.
Having discussed isomorphisms of Hilbert spaces, we move on to automorphisms. As we have already seen, the automorphisms of any object in a locally small category form a group under composition. The automorphisms group of a Hilbert space is usually called the general linear group of and denoted Thus, automorphisms are linear bijections
Proposition 6.9. A transformation is bijective if and only if it is injective.
Proof: One direction is obvious: bijections are injective. Conversely, suppose that is an injective linear operator and let be a basis. Then, is also a basis of Indeed, injectivity insures that , and if are scalars such that
then by linearity we have
Since has minimal kernel this forces
which in turn implies for all because is a linearly independent set.
Automorphisms of are not required to preserve scalar products, but nevertheless there is a characterization of automorphisms which does involve the scalar product.
Theorem 6.10. An operator is an automorphism if and only if the function
defined by is a scalar product on
Proof: Suppose first that is a scalar product. Then if and only if Consequently, if and only if , hence is injective and thus also bijective by Proposition 6.9.
Now suppose . We have to check that is consistent with the scalar product axioms. First, observe that the set of vectors such that is exactly the kernel of which is minimal by hypothesis. Hermitian symmetry is clear,
Linearity in the second slot follows from the fact that is linear and is a scalar product.
Having discussed automorphisms we move on to isometric automorphisms, i.e. unitary operators. Let be set of operators such that for all
Proposition 6.11. The set is a subgroup of
The proof of Proposition 6.11 is straightforward and left as an exercise. You can also check for yourself that is not a normal subgroup of .
In Lecture 4 we covered the basic algebraic and geometric aspects of Hilbert space and Euclidean space. In this lecture we cover Descartes’ idea to encode points in such spaces as finite lists of numbers — the method of coordinates. A straightforward implementation of this idea only works when finitely many coordinates suffice, so we first need to introduce the notion of dimension, which is done using the concept of linear independence. This material will be mostly familiar from prior exposure to linear algebra, so several proofs are omitted (though I may fill them in later).
Let be a vector space.
Definition 5.1. A finite set is said to be linearly independent if the identity
holds precisely when for each
Remark that Definition 5.1 applies in the case where is the empty set, which is a finite set of cardinality zero.
Definition 5.2. We say that is finite-dimensional if there exists a nonnegative integer such that that contains a linearly independent set of cardinality , but does not contain a linearly independent set of cardinality In this case the number is called the dimension of
For example, the zero space is a finite-dimensional vector space of dimension zero.
Now let be a finite-dimensional vector space, fixed for the remainder of the lecture. Let be a linearly independent set such that
Theorem 5.3. (Coordinate Theorem) For every vector there are scalars such that
Moreover, if also
then for each
A set as in Theorem 5.3 is said to be a basis of
Now suppose is equipped with a scalar product, i.e. it is either a Hilbert space (scalar field ) or a Euclidean space (scalar field ).
Theorem 5.4. (Gram-Schmidt) There exists a linearly independent set of cardinality such that each satisfy
A set as in Theorem 5.4 is said to be an orthonormal basis of .
Theorem 5.5. (Cartesian Coordinates) Let be an orthonormal basis. Then, for ever we have
Proof: By the coordinate theorem, we have
and therefore
-QED
The scalar products are called the Cartesian coordinates of relative to the orthonormal basis .
Now suppose we choose an ordering (aka labeling, aka enumeration) of Then, is called an ordered orthonormal basis of and the Cartesian coordinates of any vector relative to can be stored as an ordered list,
i.e. as a spatial vector in where In this way abstract vectors in a Euclidean space or Hilbert space can be represented as spatial vectors once an ordered orthonormal basis is chosen. However, for most purposes it is not necessary to choose an ordering on and one may simply work directly with unordered Cartesian coordinates. For example, we have
for every pair of vectors and in particular
The use of Cartesian coordinates without imposing an ordering is a middle path between the asceticism of never using any coordinates and the indulgence of always using ordered coordinates. Another important computation is change of coordinates. Suppose that is a novel orthonormal basis generating its own Cartesian coordinates
To express the novel coordinates we compute
Thus, by uniqueness of coordinates in a given basis, we conclude that
holds for every This is how change-of-basis is done without ordering bases.
Definition 5.6. A function from one Hilbert space to another is said to be linear if and
For some reason, linear functions between Hilbert spaces are called linear transformations; they are generally denoted by capital letters and the usual brackets surrounding the argument to the function are omitted.
Previously, we discussed functions between finite sets and showed how these can be encoded as binary matrices (“one-hot encoding”). A non-trivial Hilbert space is an uncountably infinite set and functions between such objects can be very complicated. However, linear functions between finite-dimensional Hilbert spaces are not much more complicated than functions between finite sets: they are encoded by matrices whose entries may be any elements of the ground field.
Let and be two Hilbert spaces with specified orthonormal bases, and let be a linear transformation. For any we have
Thus, is uniquely determined by the vectors and for each of these we have
It follows that is uniquely determined by the scalar products
which we call the matrix elements of relative to and If one wishes, orderings and of and may be chosen and the matrix elements of may be arranged into the matrix with entries
but for most purposes it is not necessary to do this and one can work directly with the matrix elements of relative to two unordered orthonormal bases.
As an example, let us discuss change of basis. In the category of finite sets with functions the only thing that can occur is a relabeling of the points of and which will change the one-hot encoding of by permuting its rows and columns. For linear maps between Hilbert spaces and , in which and are sitting as orthonormal bases, we may consider genuinely different orthonormal basis and We then have
a formula which gives the new matrix elements in terms of the old ones and the Cartesian coordinates of relative to the original bases
Now let us consider linear transformations and where are Hilbert spaces with orthonormal bases respectively. Then, the composition is a function and you can (and should) check that it is a linear transformation. We compute the matrix elements of the composition transformation in terms of the matrix elements of its constituents as follows:
Definition 4.1. A Hilbert space is a complex vector space equipped with a scalar product: a function
satisfying:
with equality if and only if ;
;
The term “scalar product” indicates that is a rule for multiplying two vectors in such that the product is a complex number rather than a vector in Using these axioms you can check that the scalar product satisfies the following augmented FOIL identity from high school algebra, which is known as sesquilinearity:
Definition 4.1 is nonstandard in that it typically includes an extra analytic condition which we have omitted (this will be discussed further below). One may also see the pair referred to as a Hermitian space.
A vector space without a scalar product abstracts the familiar operations of addition and scaling of spatial vectors , which are standard in science and engineering. In particular you have already in your mind the image of vectors as directed line segments representing things like velocity or acceleration; these are added tail-to-tip and stretched or squished by scalar multiplication. The reason to generalize from spatial vectors to abstract vectors is that many other types of objects can be manipulated in the same way as spatial vectors, and we can study all such systems simultaneously through an axiomatic development of general vector spaces. The motivation behind allowing for scaling by arbitrary complex numbers instead of just real ones is a bit more involved, but one may point to the use of complex vector spaces in quantum mechanics as one reason. The role of the scalar product is to provide an axiomatic foundation for abstracting familiar geometric aspects of spatial vectors, such as the length of a vector and the angle between two vectors, to the setting of an arbitrary vector space.
Defintion 4.2. A normed vector space is a complex vector space equipped with a function
such that
if and only if ;
;
The norm abstracts the notion of vector length in a way which is compatible with our geometric intuition. The first axiom says that only the zero vector has zero length. The second says that scaling a vector and then measuring its length is the same thing as multiplying the original length measurement by the magnitude of the scaling. The third is the triangle inequality: it abstracts the fact that if we add two spatial vectors tail-to-tip we get a triangle with three directed sides and . Any normed vector space can be promoted to a metric space with distance defined by
We now claim that in a Hilbert space the scalar product gives us a norm defined by
To verify this claim, we have to check that the three conditions stipulated by Definition 4.2 do in fact hold. The first two are easy to check. The third is a bit more problematic: we compute
and we have to control the quantity Since the real part of any complex number is bounded by its modulus, where equality holds precisely for nonnegative real numbers, we have
with equality if and only if
Theorem 4.3. (Cauchy-Schwarz inequality) For any vectors we have
with equality if and only if for some
Problem 4.1. Prove the Cauchy-Schwarz inequality.
At this point we have shown that the scalar product on a Hilbert space gives rise to a genuine norm defined by and hence to a genuine metric defined by . The reason Definition 4.1 is nonstandard is that at this stage one typically includes an extra clause: the metric space must be complete. We are not going to make metric completeness part of our definition of Hilbert space because we will for the most part not need to take limits of sequences of vectors in Hilbert space — that would be analysis, and our focus is algebra. Furthermore, we will soon define a notion of dimension for Hilbert spaces and then restrict our study to the finite-dimensional ones, where metric completeness is automatic.
Although we are working over the complex numbers, one may just as well consider real vector spaces equipped with a scalar product: these are called Euclidean spaces because these are indeed the most elementary and natural setting in which to carry out an axiomatic abstraction of Euclidean geometry. So far, everything we have said about Hilbert spaces holds verbatim for Euclidean spaces. However, differences between the two cases will now start to emerge. Let us begin with the fact that in both Euclidean space and Hilbert space the scalar product can be recovered from the norm, but the recipe is a bit different depending on whether one is working over the real or complex numbers.
Theorem 4.4. (Euclidean Polarization) For any vectors in a Euclidean space we have
Proof: We have
and
Subtracting the second expression from the first, we obtain
-QED
Theorem 4.5. (Hermitian Polarization) For any vectors in a Hilbert space we have
Proof: Same as above: expand the right hand side and simplify.
-QED
In both Euclidean space and Hilbert space, two vectors are said to be orthogonal if and in this case we have the following.
Theorem 4.6. (Pythagorean Theorem) For any orthogonal vectors we have
Proof: Expand and simplify using orthogonality.
-QED
Observe that the above argument also shows that we have for orthogonal vectors. If we drop orthogonality, the correct statement is the following, which is again the same in Euclidean and Hilbert space.
Theorem 4.7 (Parallelogram Law) For any two vectors in Euclidean space or Hilbert space, we have
Proof: We have
and
Adding these two expressions gives the stated identity.
-QED
Orthogonality is an abstraction of the notion of perpendicularity for spatial vectors. Now let us consider the notion of angles in general Euclidean spaces and Hilbert spaces. In both settings the definition is based on the Cauchy-Schwarz inequality, which implies
Definition 4.8. The Euclidean angle between nonzero vectors is the unique such that
The definition of the Euclidean angle between two vectors is valid in both Euclidean space and Hilbert space. In Euclidean space, the scalar product is real so we just write
This indeed corresponds to the intuitive notion of angle: if are orthogonal then and if then when and when However, while definition 4.6 is logically valid for vectors in Hilbert space, it produces counterintuitive results: for example, if then and so even though is a scalar multiple of We therefore introduce a different notion of angle measure as follows.
Definition 4.9. The Hermitian angle between nonzero vectors is the unique such that
The Hermitian angle concept is much better adapted to complex scalars than the Euclidean angle: in particular the Hermitian angle between and is zero. On the other hand, we now see a different kind of counterintuitive behavior in that the Hermitian angle between and $-v$ is also zero. The explanation for this phenomenon is that i.e. in complex geometry a ray is a real plane and and point in the same “direction.” In other words, there are no obtuse angles in complex geometry because the real concept of rotating a vector is a special case of complex scaling. This is a feature, not a bug.
Theorem 4.10. (Euclidean Law of Cosines) For any vectors we have
where is the Euclidean angle between and
Proof: We have
and the result now follows from the definition of the Euclidean angle between and
– QED
Theorem 4.11 (Hermitian Law of Cosines) For any vectors in a Hilbert space we have
where is the Hermitian angle between and
The following corollary of Theorem 4.9 is useful in the applied context of phase retrieval problems.
Corollary 4.12 (Best Phase Law) For any unit vectors in a Hilbert space we have
where is the Hermitian angle between and
Problem 4.2. Prove the Hermitian Law of Cosines for vectors in Hilbert space. Hint: modify the proof of the Euclidean case.
A lingering question is whether we could use some other class of normed vector spaces apart from Euclidean and Hilbert spaces to axiomatically develop real and complex geometry. The following nice result says that the answer is no.
Theorem 4.13. Let be either a real or complex normed vector space in which the parallelogram law holds. Then, there exists a scalar product on such that
Let us consider how one would prove Theorem 4.13, say in the real case. The basic idea is to define a polarization-inspired function
by
and show that this is a scalar product which induces the given norm. Indeed, we have
and since is a norm we immediately get that the first scalar product axiom holds. Symmetry is also straightforward,
Problem 4.3. Complete the proof of Theorem 4.13 in the real case. Hint: one strategy is to first prove additivity,
using the Parallelogram Law as your main tool. From here you can show that for Then think about how to bootstrap this to scalars in and finally in If you want to be a hero, adapt your argument to the complex setting as an optional add-on.
Here is a brief recap of Week 1. We defined combinatorics to be the branch of mathematics which studies the category whose objects are finite sets and whose morphisms are functions. We noted that a function can be encoded as a matrix over This is done by choosing a labeling of a labeling of , and building the matrix with entries
In data science, the matrix is referred to as a one-hot encoding of the function The one-hot encoding of a function depends on a labeling of the points of its domain and codomain: a relabeling of will cause to be right-multiplied by an permutation matrix, while a relabeling of requires us to left-multiply by an permutation matrix. Also note that if and then So we see that combinatorics can be encoded in terms of structured matrices defined over
We next defined linear algebra to be the study of the category whose objects are finite-dimensional complex vector spaces equipped with a scalar product, which we refer to these as Hilbert spaces, and whose morphisms are linear transformations between Hilbert spaces. We defined the quantization functor
which sends each finite set to the Hilbert space of functions equipped with the pointwise operations and scalar product
The Hilbert space has an orthonormal basis consisting of the elementary functions
Any function can be written as a linear combination of elementary functions,
where
Here we noted an alternative notation favored by algebraists: we simply write instead of , so that becomes the space of formal -linear combinations of elements of
This saves us one layer of indexing, and it is a good notation for many purposes. When thought of in this way, is referred to as the free vector space on the set and sits inside as an orthonormal basis. We will mostly use this formal notation going forward, although in other contexts (mostly analysis) the original functional notation is a better fit.
It remains to stipulate how transports morphisms in to morphisms in i.e. how transforms functions between finite sets into linear transformations between Hilbert spaces. The recipe is so simple that it looks tautological: sends a given function to the transformation defined by
Thus, if we choose an ordering of and an ordering of so that and become ordered orthonormal bases of and , the matrix of the linear transformation relative to these bases is simply the one-hot encoding of the original function
The reason that this apparently tautological translation of a set function into a linear transformation is useful is that it gives us many, many more matrix representations. Indeed, the only operations we could perform on the one-hot encoding are permuting its rows and columns. However, for the linear transformation we can multiply on the left and/or right by arbitrary invertible matrices to get new representations of the same function which are more advantageous and reveal properties of the function which are not apparent from the one-hot encoding. The fact that this can be done in a systematic way is the Singular Value Decomposition, which is in some sense the main theorem of Math 202A: it tells us we can always find orthonormal bases and such that the matrix of is real diagonal. The bases and are called the left singular vectors and the right singular vectors of respectively, and the nontrivial entries of the corresponding diagonal form of are called its singular values. In fact, this powerful result holds not just for transformations between Hilbert spaces which are functorial images of finite set functions, but for arbitrary linear transformations.
Next week, after a basic review of Hilbert spaces, we will move towards formulating and proving the SVD. In fact, for such a powerful result the proof is quite simple and straightforward, and in the case of linear transformations which come from set functions as above it has a nice interpretation in terms of bipartite graphs which is a good aid to intuition. We finish this week by introducing one more functor which transports us from the combinatorial category into a different part of mathematics.
Let be any set, not necessarily finite. Recall that a binary relation on is a subset of the Cartesian square of This is a very general concept, and the binary relations that arise in practice are more structured. For example, a function is a special type of binary relation on Also familiar are equivalence relations. Formally, we say that is an equivalence relation if it is:
Reflexive: for all we have
Symmetric: for all we have iff
Transitive: if are such that and , then
The simplest and most obvious example of an equivalence relation is equality,
A different type of equivalence relation generalizes our intuitive notion of inequality. A partial on is an relation which is reflexive and transitive, but antisymmetric rather than symmetric: and iff For partial orders, the notation is used to indicate that because it suggestively makes the antisymmetry into
A set equipped with a partial order is called a partially ordered set, often abbreviated to poset. If and are posets, a function is said to be order-preserving if
We can now give a categorical definition of one more branch of mathematics.
Definition 3.1.Order theory is the study of the category whose objects are posets and whose morphisms are order-preserving functions.
We now define a functor
as follows. First, for any set we declare
so is the power set of We equip with the partial order defined by set containment,
If I was allowed to assign problems on Fridays, I would ask you to verify that the above really is a partial order; this is easy but worth doing. In order for to be a functor, it remains to stipulate how it acts on morphisms in i.e. how it converts a function between sets into an order-preserving function . As with the functor , the recipe is extremely simple: if is a subset of we simply define
If not for the Friday ban I would ask you to verify that is an order-preserving function, but I don’t want to risk a civil rights case.
In fact, is a special kind of poset in which every pair of elements has both a least upper bound and a greatest lower bound defined by
A poset equipped with a sup and an inf is called a lattice. We define the category to be the full subcategory of whose objects are lattices, so that in fact
Next week, we will see an analogous functor from vector spaces to lattices.
In this lecture we formulate the basic organizing principle of Math 202A: linear algebra quantizes combinatorics. We will make this precise using the language of category theory, which we began to introduce in Lecture 1. In particular, we defined combinatorics as the study of the category whose objects are finite sets and whose morphisms are functions. It remains to give a corresponding definition of linear algebra.
Definition 2.1. Linear algebra is the study of the category whose objects are finite-dimensional complex vector spaces equipped with a scalar product, and whose morphisms are linear transformations.
We are going to call objects in “Hilbert spaces,” so that we don’t have to say “finite-dimensional complex vector spaces equipped with a scalar product” every time we reference such an object. However, you should be aware that in the world outside Math 202A the term Hilbert space is used in a broader sense and also includes infinite-dimensional complex inner product spaces which are complete for the norm induced by the scalar product. In the finite-dimensional case, completeness is automatic but for infinite-dimensional spaces it is an extra assumption. I repeat: in Math 202A the term Hilbert space exclusively refers to finite-dimensional complex vector spaces which come with a given scalar product. Note that two Hilbert spaces which have the same underlying vector space but different scalar products are distinct objects of but they are isomorphic with the identity transformation being a particular isomorphism. In particular, isomorphisms in are not required to preserve scalar products, but those which do (isometric isomorphisms) are particularly important and useful. Also note that we sometimes (often) reference Hilbert spaces without explicitly mentioning their scalar product.
Problem 2.1. Prove that two Hilbert spaces are isomorphic if and only if there exists a linear bijection between them.
We will commence a careful discussion of next week. Right now, we want to construct some sort of a mapping
which will justify our statement that linear algebra is quantized combinatorics. Therefore, we first need to introduce a the general notion of mapping from one category to another. As discussed in Lecture 1, categories generalize sets insofar as is just one example of a category, so mappings between categories generalize functions — they are called functors and defined as follows.
Let and be categories. A functor
is first of all a rule which assigns to each object a corresponding object Second, should map morphisms in to morphisms in in a way which is compatible with the composition laws in these categories. More precisely, we require that for any objects and morphisms and the corresponding morphisms and satisfy the equality
in
We are now ready to define a specific functor
which we will refer to as the quantization functor. The quantization of a given finite set is the Hilbert space whose vectors are functions with the vector space operations defined pointwise and the scalar product given by
We should verify that is in fact a finite-dimensional Hilbert space. First, this requires us to check that the putative scalar product introduced above really is one.
Problem 2.2. Prove that as defined above really is a scalar product on
Second, we need to show that really is a finite-dimensional vector space, and we do this by giving an explicit basis. For each define the corresponding Dirac function
Thus, is a set of functions in and in fact it is an orthonormal set,
So is a linearly independent set in and only one check remains.
Problem 2.3. Prove that spans
With Problem 2.3 in hand, we can introduce an alternative point of view for the space which is often favored by algebraists: we can think of it as the “space of formal linear combinations” of points in That is, elements of are linear combinations
where are scalars. This doesn’t really mean anything since we have no notion of scaling a point by a number , and such a formal linear combination is really just a shorthand for the coordinate decomposition
of a function with respect to the Diract basis
We are not yet done with defining the functor because we need to say how it assigns a linear transformation to a given set function Before doing this let us explain why we are referring as quantization. Consider the canonical finite set We can view this as the state space of a particle which can occupy any one position on a finite lattice of sites. Equivalently, you can think of being a ball which may be in any one of labeled boxes or, as probabilists like to say, “urns.” So is the state space of a classical particle, which is certain to be in one these boxes. On the other hand, is the state space of a quantum particle whose state is a superposition of classical states until a measurement is performed. More precisely, a (pure) quantum state is a unit vector , the physical meaning of which is that the probability to observe the quantum particle in state is given by the amplitude
Now to complete the definition of quantization as a functor from to it remains to say how a function between finite sets becomes a corresponding linear transformation between the corresponding Hilbert spaces. As in Lecture 1, let
of and , write and . Then, the function is encoded by a corresponding lookup table, namely the matrix whose -entry is if and otherwise. Now for any we simply define the corresponding linear transformation
to be the linear transformation whose matrix with respect to the bases and is the matrix of the original set function . That is,
In fact, we can give a coordinate free description of the linear transformation — for every function , the function is the pushforward of through
Problem 2.4. Show that
Now that we have justified our contention that linear algebra is quantized combinatorics, let us indicate briefly why this might be a useful functor to apply to a combinatorial problem. The first reason is that there are many more linear transformations between then there are functions Technically one says that the functor is not full, and while this sounds like a negative it is actually a good thing. Indeed if are two finite sets of combinatorial objects which we suspect have the same cardinality, then working in the category our only option is to demonstrate the existence of a bijection , and this could be hard. However, if we quantize our problem we now have the option of showing that there exists a linear isomorphism and this opens up a whole new realm of possibilities since we are allowed to map superpositions of objects in onto superpositions of objects in Another example comes from graph theory, where we can replace a graph with vertex set by the function space and encode the adjacency relation in as the operator
By thinking about the adjacency operator in different bases of we may be able to gain more insight into our graph. In particular, if we can find a superposition of vertices on which acts diagonally we have access to some very useful information, as we will discuss later in the course.
A few more remarks. First, every Hilbert space is isomorphic to a space of the form for some finite set Indeed, every vector space has a basis, and hence by the Gram-Schmidt procedure every Hilbert space has an orthonormal basis. Now, is isomorphic to for any set we use to label the elements of this ordered basis. Second, there is a different functor
worth mentioning. As the notation suggests this is closely related to the functor latex and indeed for every The difference is that we send a function to its pullback along , which is the linear transformation
defined by
Technically this does not match our definition of a functor given above, since it reverses arrows. Our initial definition in fact specifies the notion of a covariant functor, whereas this new construction is an example of a contravariant functor.
Problem 2.5. Show that the the matrix of the pullback of a set function is the adjoint of the lookup table of
As in common parlance, a mathematical category consists firstly of a collection of objects which are distinct but similar in some way. In category theory the relationships between the objects of are morphisms, and for each pair of objects we have a corresponding collection of morphisms Morphisms in are called endomorphisms, and the collection itself is denoted Morphisms can be composed: given objects and morphisms and we have a corresponding morphism Composition is both associative and unital. Associativity means that for any morphisms such that and both make sense, they in fact coincide. Unitarity means that for every pair of objects there exist morphisms and such that
holds for all morphisms We say that two objects are isomorphic if there exist morphisms and such that
We denote by the subcollection of consisting of isomorphisms. Thus, and are isomorphic if is a nonempty collection. Isomorphism is a weaker notion than equality, since may contain multiple isomorphisms. We write and call morphisms in automorphisms of
Problem 1.1. Show that is nonempty.
You might ask: what is the point of the category formalism introduced above? My preferred answer to this question is another question: what is the point of anything? This ontological response is sincere but runs the risk of being perceived as facetious. A more practical answer is that category theory is provides a very general and flexible way to organize objects and relationships, and is applied as such in the sciences. For more about this you can browse the Topos Institute website, or watch the short video below.
The fundamental example of a category is the category whose objects are sets and whose morphisms are functions. The law of composition in is composition of functions.
Problem 1.2. Prove that two sets are isomorphic if and only if there exists a bijective function
Looking at the category calls attention to the use of the term “collection” in the general definition of a category. This term is used because the collection of all sets is not itself a set and attempting to view it as such leads to paradoxes. Thus, in order to think about categories in general we need to consider aggregations of objects which are in some sense larger than sets, and we refer to these as collections. Here you may feel the urge to object that the term “collection” has not been clearly defined. However, unless you also took issue with the use of the word “set” during your undergraduate studies, you forfeited the right to this objection long ago and I will happily ignore it. Of course, Math 202A does not occupy all of reality and you are welcome to examine these foundational issues yourself in its complement.
Having pointed out that the collection of all sets is a somewhat subtle concept, let us point out that the collections which make up the morphisms are not so bad: they can be considered as sets without running into any foundational issues. Indeed, if you believe that and being sets is enough to certify
as a set, than there is no further issue because a function is by definition a subset with the property that contains exactly one point of the form for each Thus, the collection of all functions is contained in the collection of all subsets of the set and hence is contained in a set.
The upshot is that categories are more general than sets, with being just one example of a category. A helpful heuristic to have in mind is that categories are like directed graphs, possibly very large ones, with objects being vertices and morphisms being directed edges. Composing morphisms is analogous to concatenating arrows. A subcategory should then be like a subgraph, and a function from one category to another should be like a graph homomorphism. We will come back to this.
Definition 1.1: Combinatorics is the study of the category whose objects are finite sets and whose morphisms are functions.
From the general perspective of Definition 1, the typical problems of combinatorics can be formulated along the following lines. First there is the counting problem: given a finite nonempty set defined in some explicit but not transparent way (for example, the set of alternating sign matrices), what is the natural number such that is isomorphic to ? The study of questions of this kind is called enumerative combinatorics. Another type of question is: given two finite nonempty sets again defined in some explicit but non-transparent way, is nonempty? If so, can we explicitly describe an isomorphism ? This endeavor is usually called bijective combinatorics.
The category is a subcategory of . Hoping that the collection of all finite sets can be thought of as a set without running into paradoxes is a bit too optimistic (to see why, observe that for any set the set is finite…). However, the set of functions between two finite sets is finite, and more than this functions between finite sets can be efficiently encoded as matrices. Indeed, suppose and By definition, this means that there exist isomorphisms
and
It is natural to think of these isomorphisms as labelings of the elements of and writing
and
With these labelings in place, we can represent the function as the matrix whose -entry is if and if not. Thus, every is represented by an element of i.e. an matrix with entries in The cardinality of all such binary matrices in but the cardinality of is only because the matrix representation of a function has exactly one in each column. It is important to note that the matrix representation of a given function is not unique because it depends on the labelings In particular, the number of distinct matrix representations of a given function is at most
Since every finite set is a set, every object of is an object of Moreover, for any two finite sets the collection of morphisms is the same whether we view as objects of or as objects of We say that is a full subcategory of to indicate that no morphisms are lost. Contrast this with the category whose objects are finite sets and whose morphisms are injective functions; this is a subcategory of but not a full subcategory. Indeed, is not even a full subcategory of — it has the same collection of objects but a restricted collection of morphisms. One says that is a wide subcategory of
Problem 1.3. Verify that really is a category, i.e. obeys the axioms stipulated above. Calculate and
Continuing onward, most courses you took as an undergraduate can be defined as the study of a particular category. Here is another example.
Definition 1.2.Group theory is the study of the category whose objects are groups and whose morphisms are group homomorphisms.
Groups form an extremely important and fundamental category because they occur in every category, more or less. The “more or less” is due to the fact that a group is, by definition, a set. A category is said to be locally small if is a set for every pair of objects In particular, every subcategory of is a locally small category.
Problem 1.4. Prove that in any locally small category, is a group for every object
Thus, every locally small category gives us a group for each of its objects. The subject known as representation theory is concerned with reversing this observation by representing the elements of a given group as automorphisms in a preferred locally small category For any object we can consider actions of on which by definition are group homomorphisms
Now we can consider all ways in which can act on the objects of and assemble these into a new category whose objects are pairs as above. Such pairs are called representations of , and for every representation is a subgroup of Thus, we are representing the elements of as automorphisms of the object . This might result in losing some of the structure of since several group elements could map to the same automorphism of For example, the extreme case is the trivial representation where for every In the opposite extreme case, where is injective and is a subgroup of isomorphic to , the we say that is a faithful representation of
It remains to define the morphisms of our nascent category For any two representations and we define the corresponding set of morphisms to be the subset of consisting of so-called -equivariant morphisms . By definition, these are morphisms which intertwine the actions in the sense that
holds for every group element
Let us consider the above construction in the case where For a set the group is called the permutation group of and its elements are called permutations of Consequently, objects of are called permutation representations of Now, since a group is by definition a set, is itself an object of Furthermore, there is a canonical action
of on itself defined by where are elements of and is the product of these elements in This gives a permutation representation called the regular representation of
Problem 1.5. Prove that as defined above really is a group homomorphism, and that really is a set-theoretic automorphism of for every Finally, prove Cayley’s theorem: the groups and are isomorphic.
Cayley’s theorem is a very familiar result from elementary group theory which, in the language introduced above, says that every group has a faithful representation in the category of sets. Representations of groups on the category of vector spaces are called linear representations and we will study these in Math 202B. In Math 202A, we have a much more modest task, namely that of studying the category of vector spaces as is, without any group acting in the background.
Definition 1.3. Linear algebra is the study of the category whose objects are vector spaces and whose morphisms are linear transformations.
Technically, Definition 1.3 is incomplete because we must specify the field over which our vector spaces are defined. We will do this next lecture, where we further argue that finite-dimensional linear algebra can be viewed as a “quantization” of combinatorics.
Math 202A is the first quarter of a three-quarter applied algebra class. It is a PhD level course on linear algebra, and the assumption is that you know linear algebra at the undergraduate level. Furthermore, the way in which the material is delivered will probably cause Math 202 to feel quite different from a standard undergraduate lecture course. Below is a lecture schedule.
Here is a bit more detail on the topics we will cover. This is not exhaustive and is intended only as a broad outline of some of the main themes.
We will begin by introducing the rudiments of category theory and discuss its usefulness in organizing our existing knowledge and future endeavors. For us category theory is an organizational device, but it has applications in the sciences and is a branch of applied algebra in its own right.
We will discuss the categories of sets, groups, posets, and vector spaces in some detail, and give a category-theoretic definition of group representation theory. We will then consider the “quantization” functor which transports us from the category of finite sets to the category of finite-dimensional complex vector spaces, which is where we shall stay for most of the course.
We will study finite-dimensional complex vector spaces with a scalar product, which we call Hilbert spaces. Morphisms in this category are linear functions, which for historical reasons are called linear transformations. Any function between finite sets can be encoded as a matrix with entries in and any linear transformation between Hilbert spaces can be encoded as a matrix with entries in We prove the Singular Value Decomposition (SVD), which says that any linear transformation between Hilbert spaces can be represented as a diagonal matrix with real entries, this representation being unique up to signed permutations. This result is of fundamental importance in applications of linear algebra to the sciences.
A nice feature of the set of all linear transformations from one Hilbert space to another is that it is also a Hilbert space with a canonically defined scalar product called the Frobenius form. The Hilbert space structure on linear transformations plays a significant role in applications of linear algebra since it provides a way to discuss the magnitude of a matrix. There are many other useful matrix norms, and we will discuss a few of these from the point of view of the SVD.
After concluding our discussion of homomorphisms between Hilbert spaces we will concentrate on endomorphisms of a Hilbert space, which are called linear operators. Linear operators on a Hilbert space quantize self-maps on a finite set. For example, the quantization of an indicator function is an orthogonal projection and the quantization of a permutation is a unitary operator. Using the SVD, we establish the polar decomposition of an arbitrary operator and the spectral decomposition of a normal operator.
We then move on to a detailed study of the spectral decomposition of selfadjoint operators: the theory of eigenvalues. We will obtain many interesting results about eigenvalues, including results on dominance, interlacing, and perturbation. A very interesting class of selfadjoint operators are the adjacency operators of finite graphs, and we will discuss these in some detail and prove a few famous results on their eigenvalues, such as the Perron-Frobenius theorem on the largest eigenvalue and the Alon-Boppana theorem on the spectral gap.
It is natural to wonder what the spectrum of a typical selfadjoint operator looks like — what are the expected features of its eigenvalue distribution? This question motivates the subject of random matrix theory. We will prove the famous Wigner semicircle law which describes the expected eigenvalue distribution of large random Hermitian matrices.
Not all vector spaces which arise in practice have complex scalars. In particular, real coefficients seem more natural in applications though one should keep in mind that quantum mechanics tells us this is not really so. Throughout the course, we will regularly comment on when our Hilbert space results remain valid for real finite-dimensional vector spaces with scalar product, which are called Euclidean spaces. Typically this is quite straightforward. More significant differences occur when we move to the category of finite-dimensional vector spaces defined over a finite field. This category also has many important applications, and can be thought of as a different kind of quantization of the category of finite sets. We will spend a few lectures discussing this interesting category.
We will end with a discussion of the most important special function of a linear operator: the exponential function. For operators on a Hilbert space of dimension greater than one, it is not in general true that the exponential function converts addition into multiplication. The correct statement is the Campbell-Baker-Hausdorff formula, which is the first step down the road to Lie theory. We will present an elementary proof of this result due to Eichler.
This completes our rough outline of topics. There is no official textbook for the class and I will post typed notes following each lecture. However, while the course is running I recommend consulting the following books:
Seven Sketches in Compositionality: An Invitation to Applied Category Theory, by Brendan Fong and David Spivak. Just browse this one.
Lectures on Linear Algebra, by Israel Gelfand. Perhaps the best book on linear algebra ever written; I recommend reading the whole thing.
Matrix Analysis, by Charles Johnson and Roger Horn. Use this as a comprehensive reference.
Groups, Matrices, and Vector Spaces, by James B. Carrell. A nice book worth consulting regularly to broaden your horizons.
All the Mathematics You Missed but Need to Know for Graduate School, by Thomas Garrity. Read the chapter on linear algebra as a refresher. This book can be useful for qualifying exam study.
Your grade in Math 202A will be based on weekly problem sets (70%) and a final exam (30%). There is no midterm exam. Problem sets will typically be due on Sunday at 23:59, and will be submitted and returned via GradeScope (the course TA, Runqiu Xu, will send out an email during the first week of classes explaining this protocol in more detail). Your lowest problem set score will be dropped. The final exam is scheduled for 12/09/2025 at 15:00 in our regular lecture room, B412. I have no control over these coordinates, and if you cannot sit for the exam you should not take the course.

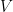







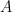



















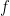

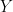






























































 for each
for each 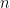 such that that
such that that  In this case the number
In this case the number  is a finite-dimensional vector space of dimension zero.
is a finite-dimensional vector space of dimension zero. 
 there are scalars
there are scalars  such that
such that

 for each
for each 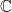 ) or a Euclidean space (scalar field
) or a Euclidean space (scalar field  ).
). satisfy
satisfy



 are called the Cartesian coordinates of
are called the Cartesian coordinates of 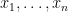 of
of  Then,
Then, ![[v] = \begin{bmatrix} \langle x_1,v \rangle \\ \vdots \\ \langle x_n,v\rangle \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5Bv%5D+%3D+%5Cbegin%7Bbmatrix%7D+%5Clangle+x_1%2Cv+%5Crangle+%5C%5C+%5Cvdots+%5C%5C+%5Clangle+x_n%2Cv%5Crangle+%5Cend%7Bbmatrix%7D%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 where
where  In this way abstract vectors in a Euclidean space or Hilbert space can be represented as spatial vectors once an ordered orthonormal basis is chosen. However, for most purposes it is not necessary to choose an ordering on
In this way abstract vectors in a Euclidean space or Hilbert space can be represented as spatial vectors once an ordered orthonormal basis is chosen. However, for most purposes it is not necessary to choose an ordering on 
 and in particular
and in particular 
 is a novel orthonormal basis generating its own Cartesian coordinates
is a novel orthonormal basis generating its own Cartesian coordinates


 This is how
This is how  from one Hilbert space to another is said to be linear if
from one Hilbert space to another is said to be linear if  and
and 


 and for each of these we have
and for each of these we have
 scalar products
scalar products 
 If one wishes, orderings
If one wishes, orderings  of
of 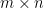 matrix
matrix ![[A]](https://s0.wp.com/latex.php?latex=%5BA%5D&bg=FFFFFF&fg=000&s=0&c=20201002) with entries
with entries ![[A]_{ij} = \langle y_j, Ax_i\rangle,](https://s0.wp.com/latex.php?latex=%5BA%5D_%7Bij%7D+%3D+%5Clangle+y_j%2C+Ax_i%5Crangle%2C&bg=FFFFFF&fg=000&s=0&c=20201002)
 which will change the one-hot encoding of
which will change the one-hot encoding of  and
and  We then have
We then have
 relative to the original bases
relative to the original bases 
 and
and  where
where  are Hilbert spaces with orthonormal bases
are Hilbert spaces with orthonormal bases  respectively. Then, the composition
respectively. Then, the composition  is a function
is a function  and you can (and should) check that it is a linear transformation. We compute the matrix elements of the composition transformation in terms of the matrix elements of its constituents as follows:
and you can (and should) check that it is a linear transformation. We compute the matrix elements of the composition transformation in terms of the matrix elements of its constituents as follows:

 with equality if and only if
with equality if and only if  ;
; ;
;
 in
in  is a complex number rather than a vector in
is a complex number rather than a vector in 
 referred to as a Hermitian space.
referred to as a Hermitian space. , which are standard in science and engineering. In particular you have already in your mind the image of vectors as directed line segments representing things like
, which are standard in science and engineering. In particular you have already in your mind the image of vectors as directed line segments representing things like  is that many other types of objects can be manipulated in the same way as spatial vectors, and we can study all such systems simultaneously through an axiomatic development of general vector spaces. The motivation behind allowing for scaling by arbitrary complex numbers instead of just real ones is a bit more involved, but one may point to the use of complex vector spaces in quantum mechanics as one reason. The role of the scalar product is to provide an axiomatic foundation for abstracting familiar geometric aspects of spatial vectors, such as the length of a vector and the angle between two vectors, to the setting of an arbitrary vector space.
is that many other types of objects can be manipulated in the same way as spatial vectors, and we can study all such systems simultaneously through an axiomatic development of general vector spaces. The motivation behind allowing for scaling by arbitrary complex numbers instead of just real ones is a bit more involved, but one may point to the use of complex vector spaces in quantum mechanics as one reason. The role of the scalar product is to provide an axiomatic foundation for abstracting familiar geometric aspects of spatial vectors, such as the length of a vector and the angle between two vectors, to the setting of an arbitrary vector space.
 if and only if
if and only if  ;
;
 abstracts the notion of vector length in a way which is compatible with our geometric intuition. The first axiom says that only the zero vector has zero length. The second says that scaling a vector and then measuring its length is the same thing as multiplying the original length measurement by the magnitude of the scaling. The third is the triangle inequality: it abstracts the fact that if we add two spatial vectors
abstracts the notion of vector length in a way which is compatible with our geometric intuition. The first axiom says that only the zero vector has zero length. The second says that scaling a vector and then measuring its length is the same thing as multiplying the original length measurement by the magnitude of the scaling. The third is the triangle inequality: it abstracts the fact that if we add two spatial vectors 
 . Any normed vector space can be promoted to a
. Any normed vector space can be promoted to a 


 Since the real part of any complex number is bounded by its modulus, where equality holds precisely for nonnegative real numbers, we have
Since the real part of any complex number is bounded by its modulus, where equality holds precisely for nonnegative real numbers, we have

 we have
we have
 for some
for some 
 and hence to a genuine metric defined by
and hence to a genuine metric defined by  . The reason Definition 4.1 is nonstandard is that at this stage one typically includes an extra clause: the metric space
. The reason Definition 4.1 is nonstandard is that at this stage one typically includes an extra clause: the metric space  must be
must be 




 and in this case we have the following.
and in this case we have the following.
 and simplify using orthogonality.
and simplify using orthogonality. for orthogonal vectors. If we drop orthogonality, the correct statement is the following, which is again the same in Euclidean and Hilbert space.
for orthogonal vectors. If we drop orthogonality, the correct statement is the following, which is again the same in Euclidean and Hilbert space.



![\theta \in [-\pi,\pi]](https://s0.wp.com/latex.php?latex=%5Ctheta+%5Cin+%5B-%5Cpi%2C%5Cpi%5D&bg=FFFFFF&fg=000&s=0&c=20201002) such that
such that
![\cos \theta = \frac{\langle v,w \rangle}{\|v\|\|w\|}, \quad \theta \in [-\pi,\pi].](https://s0.wp.com/latex.php?latex=%5Ccos+%5Ctheta+%3D+%5Cfrac%7B%5Clangle+v%2Cw+%5Crangle%7D%7B%5C%7Cv%5C%7C%5C%7Cw%5C%7C%7D%2C+%5Cquad+%5Ctheta+%5Cin+%5B-%5Cpi%2C%5Cpi%5D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 and if
and if  then
then  when
when  and
and  when
when  However, while definition 4.6 is logically valid for vectors in Hilbert space, it produces counterintuitive results: for example, if
However, while definition 4.6 is logically valid for vectors in Hilbert space, it produces counterintuitive results: for example, if  then
then  and
and  so
so  even though
even though  is a scalar multiple of
is a scalar multiple of 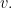 We therefore introduce a different notion of angle measure as follows.
We therefore introduce a different notion of angle measure as follows. ![\theta \in [0,\frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=%5Ctheta+%5Cin+%5B0%2C%5Cfrac%7B%5Cpi%7D%7B2%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002) such that
such that
 is zero. On the other hand, we now see a different kind of counterintuitive behavior in that the Hermitian angle between
is zero. On the other hand, we now see a different kind of counterintuitive behavior in that the Hermitian angle between  i.e. in complex geometry a ray is a real plane and
i.e. in complex geometry a ray is a real plane and  point in the same “direction.” In other words, there are no obtuse angles in complex geometry because the real concept of rotating a vector is a special case of complex scaling. This is a feature, not a bug.
point in the same “direction.” In other words, there are no obtuse angles in complex geometry because the real concept of rotating a vector is a special case of complex scaling. This is a feature, not a bug. 
 is the Euclidean angle between
is the Euclidean angle between 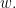







 is a norm we immediately get that the first scalar product axiom holds. Symmetry is also straightforward,
is a norm we immediately get that the first scalar product axiom holds. Symmetry is also straightforward,

 for
for  Then think about how to bootstrap this to scalars in
Then think about how to bootstrap this to scalars in  and finally in
and finally in  If you want to be a hero, adapt your argument to the complex setting as an optional add-on.
If you want to be a hero, adapt your argument to the complex setting as an optional add-on. whose objects are finite sets and whose morphisms are functions. We noted that a function
whose objects are finite sets and whose morphisms are functions. We noted that a function  can be encoded as a matrix over
can be encoded as a matrix over  This is done by choosing a labeling
This is done by choosing a labeling  a labeling
a labeling ![[f]](https://s0.wp.com/latex.php?latex=%5Bf%5D&bg=FFFFFF&fg=000&s=0&c=20201002) with entries
with entries![[f]_{ij} = \begin{cases} 1,\text{ if } f(x_j)=y_i \\ 0,\text{ otherwise}\end{cases}.](https://s0.wp.com/latex.php?latex=%5Bf%5D_%7Bij%7D+%3D+%5Cbegin%7Bcases%7D+1%2C%5Ctext%7B+if+%7D+f%28x_j%29%3Dy_i+%5C%5C+0%2C%5Ctext%7B+otherwise%7D%5Cend%7Bcases%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 The one-hot encoding of a function depends on a labeling of the points of its domain and codomain: a relabeling of
The one-hot encoding of a function depends on a labeling of the points of its domain and codomain: a relabeling of 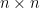
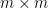 permutation matrix. Also note that if
permutation matrix. Also note that if  and
and  then
then ![[g \circ f]=[g] \circ [f].](https://s0.wp.com/latex.php?latex=%5Bg+%5Ccirc+f%5D%3D%5Bg%5D+%5Ccirc+%5Bf%5D.&bg=FFFFFF&fg=000&s=0&c=20201002) So we see that combinatorics can be encoded in terms of structured matrices defined over
So we see that combinatorics can be encoded in terms of structured matrices defined over 

 of functions
of functions  equipped with the pointwise operations and scalar product
equipped with the pointwise operations and scalar product 

 can be written as a linear combination of elementary functions,
can be written as a linear combination of elementary functions,

 instead of
instead of  , so that
, so that 
 transports morphisms in
transports morphisms in  defined by
defined by![[\mathcal{F}(f)]x = f(x), \quad x \in X.](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BF%7D%28f%29%5Dx+%3D+f%28x%29%2C+%5Cquad+x+%5Cin+X.&bg=FFFFFF&fg=000&s=0&c=20201002)
 , the matrix of the linear transformation
, the matrix of the linear transformation  relative to these bases is simply the one-hot encoding of the original function
relative to these bases is simply the one-hot encoding of the original function 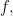
![[\mathcal{F}(f)] =[f].](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BF%7D%28f%29%5D+%3D%5Bf%5D.&bg=FFFFFF&fg=000&s=0&c=20201002)
 and
and  such that the matrix of
such that the matrix of  and
and  are called the left singular vectors and the right singular vectors of
are called the left singular vectors and the right singular vectors of  respectively, and the nontrivial entries of the corresponding diagonal form of
respectively, and the nontrivial entries of the corresponding diagonal form of  the
the  is a special type of binary relation on
is a special type of binary relation on  is an
is an 
 iff
iff 
 are such that
are such that  , then
, then 

 and
and  iff
iff  For partial orders, the notation
For partial orders, the notation  is used to indicate that
is used to indicate that 
 is called a
is called a 
 whose objects are posets and whose morphisms are order-preserving functions.
whose objects are posets and whose morphisms are order-preserving functions. 

 is the
is the 
 to be a functor, it remains to stipulate how it acts on morphisms in
to be a functor, it remains to stipulate how it acts on morphisms in  i.e. how it converts a function
i.e. how it converts a function  . As with the functor
. As with the functor  is a subset of
is a subset of  = f(S) = \{f(x) \colon x \in S\}.](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BP%7D%28f%29%5D%28S%29+%3D+f%28S%29+%3D+%5C%7Bf%28x%29+%5Ccolon+x+%5Cin+S%5C%7D.&bg=FFFFFF&fg=000&s=0&c=20201002)

 to be the full subcategory of
to be the full subcategory of 
 but they are isomorphic with the identity transformation being a particular isomorphism. In particular, isomorphisms in
but they are isomorphic with the identity transformation being a particular isomorphism. In particular, isomorphisms in  are not required to preserve scalar products, but those which do (isometric isomorphisms) are particularly important and useful. Also note that we sometimes (often) reference Hilbert spaces without explicitly mentioning their scalar product.
are not required to preserve scalar products, but those which do (isometric isomorphisms) are particularly important and useful. Also note that we sometimes (often) reference Hilbert spaces without explicitly mentioning their scalar product.
 is just one example of a category, so mappings between categories generalize functions — they are called
is just one example of a category, so mappings between categories generalize functions — they are called  and
and  be categories. A functor
be categories. A functor 
 a corresponding object
a corresponding object  Second,
Second,  and morphisms
and morphisms  the corresponding morphisms
the corresponding morphisms  satisfy the equality
satisfy the equality


 with the vector space operations defined pointwise and the scalar product given by
with the vector space operations defined pointwise and the scalar product given by
 as defined above really is a scalar product on
as defined above really is a scalar product on 

 is a set of
is a set of  and in fact it is an orthonormal set,
and in fact it is an orthonormal set,
 is a linearly independent set in
is a linearly independent set in 
 are scalars. This doesn’t really mean anything since we have no notion of scaling a point
are scalars. This doesn’t really mean anything since we have no notion of scaling a point  , and such a formal linear combination is really just a shorthand for the coordinate decomposition
, and such a formal linear combination is really just a shorthand for the coordinate decomposition
 with respect to the Diract basis
with respect to the Diract basis 
 as quantization. Consider the canonical finite set
as quantization. Consider the canonical finite set  We can view this as the state space of a particle
We can view this as the state space of a particle  which can occupy any one position on a finite lattice of
which can occupy any one position on a finite lattice of  whose state is a
whose state is a  , the physical meaning of which is that the probability to observe the quantum particle in state
, the physical meaning of which is that the probability to observe the quantum particle in state 
 between the corresponding Hilbert spaces. As in Lecture 1, let
between the corresponding Hilbert spaces. As in Lecture 1, let 
 and
and  . Then, the function
. Then, the function  -entry is
-entry is 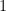 if
if  and
and  otherwise. Now for any
otherwise. Now for any 
 and
and  is the matrix of the original set function
is the matrix of the original set function 
 — for every function
— for every function  is the
is the 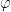 through
through  = \sum\limits_{x \in f^{-1}(y)} \varphi(x).](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BF%7D%28f%29%5Cvarphi%5D%28y%29+%3D+%5Csum%5Climits_%7Bx+%5Cin+f%5E%7B-1%7D%28y%29%7D+%5Cvarphi%28x%29.&bg=FFFFFF&fg=000&s=0&c=20201002)
 then there are functions
then there are functions  Technically one says that the functor
Technically one says that the functor 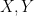 are two finite sets of combinatorial objects which we suspect have the same cardinality, then working in the category
are two finite sets of combinatorial objects which we suspect have the same cardinality, then working in the category  and this opens up a whole new realm of possibilities since we are allowed to map superpositions of objects in
and this opens up a whole new realm of possibilities since we are allowed to map superpositions of objects in  in
in 

 for every
for every  The difference is that we send a function
The difference is that we send a function  to its pullback along
to its pullback along 

 of a set function
of a set function  of
of  Morphisms in
Morphisms in  are called endomorphisms, and the collection
are called endomorphisms, and the collection  Morphisms can be composed: given objects
Morphisms can be composed: given objects  and morphisms
and morphisms  Composition is both associative and unital. Associativity means that for any morphisms such that
Composition is both associative and unital. Associativity means that for any morphisms such that  and
and  both make sense, they in fact coincide. Unitarity means that for every pair of objects
both make sense, they in fact coincide. Unitarity means that for every pair of objects  and
and  such that
such that
 We say that two objects
We say that two objects  such that
such that
 the subcollection of
the subcollection of  consisting of isomorphisms. Thus,
consisting of isomorphisms. Thus,  and call morphisms in
and call morphisms in  automorphisms of
automorphisms of 
 of all sets is not itself a set and attempting to view it as such leads to
of all sets is not itself a set and attempting to view it as such leads to 
 with the property that
with the property that  for each
for each  and hence is contained in a set.
and hence is contained in a set. such that
such that 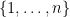 ? The study of questions of this kind is called enumerative combinatorics. Another type of question is: given two finite nonempty sets
? The study of questions of this kind is called enumerative combinatorics. Another type of question is: given two finite nonempty sets  again defined in some explicit but non-transparent way, is
again defined in some explicit but non-transparent way, is  ? This endeavor is usually called bijective combinatorics.
? This endeavor is usually called bijective combinatorics.  is finite…). However, the set
is finite…). However, the set  and
and  By definition, this means that there exist isomorphisms
By definition, this means that there exist isomorphisms



![[f] = [f]_{\lambda\mu}](https://s0.wp.com/latex.php?latex=%5Bf%5D+%3D+%5Bf%5D_%7B%5Clambda%5Cmu%7D&bg=FFFFFF&fg=000&s=0&c=20201002) whose
whose  i.e. an
i.e. an  The cardinality of all such binary matrices in
The cardinality of all such binary matrices in  but the cardinality of
but the cardinality of  is only
is only  because the matrix representation of a function has exactly one
because the matrix representation of a function has exactly one  In particular, the number of distinct matrix representations of a given function
In particular, the number of distinct matrix representations of a given function 
 Moreover, for any two finite sets
Moreover, for any two finite sets  We say that
We say that  whose objects are finite sets and whose morphisms are injective functions; this is a subcategory of
whose objects are finite sets and whose morphisms are injective functions; this is a subcategory of  and
and 
 whose objects are groups and whose morphisms are group homomorphisms.
whose objects are groups and whose morphisms are group homomorphisms. In particular, every subcategory of
In particular, every subcategory of 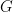 as automorphisms in a preferred locally small category
as automorphisms in a preferred locally small category  For any object
For any object 
 and assemble these into a new category
and assemble these into a new category  whose objects are pairs
whose objects are pairs  as above. Such pairs are called representations of
as above. Such pairs are called representations of  is a subgroup of
is a subgroup of  Thus, we are representing the elements of
Thus, we are representing the elements of  since several group elements could map to the same automorphism of
since several group elements could map to the same automorphism of  for every
for every  In the opposite extreme case, where
In the opposite extreme case, where  is a subgroup of
is a subgroup of 
 For any two representations
For any two representations  we define the corresponding set of morphisms to be the subset
we define the corresponding set of morphisms to be the subset  of
of  in the sense that
in the sense that
 For a set
For a set 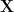 and its elements are called permutations of
and its elements are called permutations of  are called permutation representations of
are called permutation representations of  Now, since a group is by definition a set,
Now, since a group is by definition a set, 
 where
where  are elements of
are elements of  is the product of these elements in
is the product of these elements in  called the regular representation of
called the regular representation of  as defined above really is a group homomorphism, and that
as defined above really is a group homomorphism, and that  really is a set-theoretic automorphism of
really is a set-theoretic automorphism of  are isomorphic.
are isomorphic. whose objects are vector spaces and whose morphisms are linear transformations.
whose objects are vector spaces and whose morphisms are linear transformations. and any linear transformation between Hilbert spaces can be encoded as a matrix with entries in
and any linear transformation between Hilbert spaces can be encoded as a matrix with entries in  We prove the Singular Value Decomposition (SVD), which says that any linear transformation between Hilbert spaces can be represented as a diagonal matrix with real entries, this representation being unique up to signed permutations. This result is of fundamental importance in applications of linear algebra to the sciences.
We prove the Singular Value Decomposition (SVD), which says that any linear transformation between Hilbert spaces can be represented as a diagonal matrix with real entries, this representation being unique up to signed permutations. This result is of fundamental importance in applications of linear algebra to the sciences.