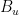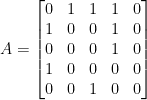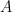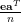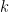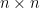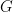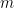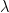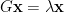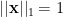The PageRank is a search algorithm based on the linkage structure of the web, which Larry Page and Sergey Brin introduced. They built the search engine Google to test the utility of PageRank for search. (Origin of the name “Google”)
The goal of this lecture is to construct Google matrix and explore how to find PageRank vector. Let’s start by making an adjacency matrix based on web linkage.
Let be a webpage, and let be the set of pages points to and be the set of pages that point to . Consider each webpage as vertices and link as directed edge. We can construct an adjacency matrix if there exist links from to , otherwise where are webpages. For example, if webpages have linkage in Figure 1, A is defined as follows.
Figure 1. A simple example consists of 5 webpages
We can observe that the last column of A is a zero vector because does not have forward links. We call such a node a dangling node.
Let be the number of links from . Then column normalized adjacency matrix of is defined by . denotes column corresponding page . In our example,
This matrix is not directly used in the PageRank. To compute PageRank vector, we will use the power method, an iterative procedure, has convergence problem. The procedure can cycle, or the limit may be dependent on the starting vector. To avoid this problem, we need to have a left stochastic matrix.
Like in our example, it can be possible that is not stochastic because of dangling nodes. Therefore, define stochastic matrix where is a vector of all ones, is the number of web pages, and if , otherwise .
When you do web surfing, though there are no forward links (dangling nodes), we may visit other new web pages. The matrix add the situation with uniform probability for all web pages.
Problem 1: Find for our example.
Then by the Gershgorin circle theorem, the largest eigenvalue of is less than or equal to 1. Since det, we know there is the largest eigenvalue . We want to find the dominant eigenvector of , which is PageRank vector. For finding eigenvector, PageRank uses Power Method.
Some of you may already realize, finding PageRank vector is finding stationary distribution (See Lecture 5, Lecture 6) of random walks on the web graph. However, if the stationary distribution vector is not unique, we cannot get the exact PageRank vector. This problem can be solved by Perron–Frobenius theorem. If is irreducible, eigenvector corresponding eigenvalue 1 is unique by Perron-Frobenius.
Definition 1: A matrix is primitive if it is non-negative and its th power is positive for some natural number .
Definition 2: An matrix is a reducible matrix if for some permutation matrix , such that is block upper triangular. If a square matrix is not reducible, it is said to be an irreducible matrix.
For more knowledge related to primitive and irreducible, see [6].
Problem 2: Every primitive matrix is irreducible.
We can construct a primitive matrix where and . In reality, Google use ([1], [7]). Since is primitive, so it is irreducible, we can get the unique PageRank vector by Power Method. We call this matrix as Google matrix. Such is called damping constant, this reflects a person who is randomly clicking on links will eventually stop clicking. In our example, is
when .
Here, we call the unique largest eigenvalue of as Perron root (for Google matrix ), and is Perron vector if and . has unique dominant eigenvalue implies that there is the unique PageRank vector. (If you want to check convergence, see [4], p. 179)
Finally, Power Method on ([2]), recursively compute , finds the limit of , say . This is PageRank vector. That is, PageRank of page is where is Perron vector and . Note that is a probability vector reflects the possibility of click each webpage.