Author: Qihao Ye
Andrew Dennehy have already introduced the concept of the discrete Fourier transform (DFT) to us in Lecture 18, but I would like to retake the path with more details, because there are some other concepts (which help for fully understanding) I would like to talk about.
We mainly talk about how fast Fourier transform (FFT) and inverse fast Fourier transform (IFFT) work, we sightly talk about the calculation error.
We will see how FFT and IFFT work from both the perspective of math and computer, along with their applications and some specific problems. Some problem may involve the number theoretic transform (NTT), which is recognized as the integer DFT over finite field.
We use Python3 for code examples, since we would not use version related feature, the specific version does not matter. (For instance, Python3.5.2 and Python3.8.1 are both ok.) We would call Python instead of Python3 in the following content. (If you do not install Python, there are many online interpreters that can run Python codes, for instance, Try It Online.) Recommend to view this page with computer for getting the best experience. Recommend to try the codes and solve some problems by yourself, which definitely would be challenging and interesting.
There are only 2 exercises in this lecture, other problems are interest based algorithm problems (no need to do as homework), which might be difficult to solve if you are not very familiar with the FFT and NTT in this form, but I will give hints to guide you.
Now let us start with an easy example.
Example 1: We consider two polynomials
Multiply them together (using distributive property), we would get
Definition 1 (coefficient representation): For a polynomial 
![[a_{0}, a_{1}, \ldots, a_{n}]](https://s0.wp.com/latex.php?latex=%5Ba_%7B0%7D%2C+a_%7B1%7D%2C+%5Cldots%2C+a_%7Bn%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
![P[k]](https://s0.wp.com/latex.php?latex=P%5Bk%5D&bg=FFFFFF&fg=000&s=0&c=20201002)


Use definition 1, we can write 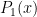
![[1, 2, 3, 4]](https://s0.wp.com/latex.php?latex=%5B1%2C+2%2C+3%2C+4%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
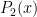
![[2, 3, 4, 5]](https://s0.wp.com/latex.php?latex=%5B2%2C+3%2C+4%2C+5%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

![[2, 7, 16, 30, 34, 31, 20]](https://s0.wp.com/latex.php?latex=%5B2%2C+7%2C+16%2C+30%2C+34%2C+31%2C+20%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
The naïve polynomial multiplication function is not hard to get:
def naive_poly_mul(P1, P2):
Q = [0] * (len(P1) + len(P2) - 1)
for i in range(len(P1)):
for j in range(len(P2)):
Q[i + j] += P1[i] * P2[j]
return Q
In the general case, i.e.,
it is easy to see that the complexity of the naïve polynomial multiplication function is 
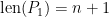

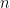
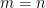

Definition 2 (degree of polynomial): The degree of a polynomial is the highest of the degrees of the polynomial’s monomials (individual terms) with non-zero coefficients.
In Example 1, 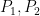

Definition 3 (value representation): Except representing a 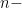
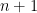
Exercise 1 : Prove that 

Back to Example 1, to get 
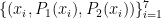
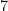

When the degree of 
However, at most time, we only need the coefficient representation, because it is more suitable to calculate the values in its domain. It is not hard to figure out we can do the multiplication in this way:
If we only consider the situation that we aim to multiply two
The naïve way to get the value representation of a coefficient represented polynomial cost at least
The essential idea is selecting specific points to reduce the calculation cost.
The straight thought would be looking at the parity of a function. Because for any odd function 
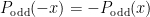


Actually, we can divide any polynomial into one odd function plus one even function. Take a look back to 
Notice that 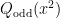

Note that 
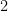
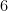
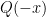
What we only need to do is recursive process 
However, we would encounter the problem that the symmetric property could not be maintained further (we can pair 

As we already see in the previous Lecture, we can use the roots of unity to solve this problem. Denote 

To make it easier to understand, we now only consider 
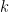
![[\omega_{n}^{0}, \omega_{n}^{1}, \ldots, \omega_{n}^{n - 1}]](https://s0.wp.com/latex.php?latex=%5B%5Comega_%7Bn%7D%5E%7B0%7D%2C+%5Comega_%7Bn%7D%5E%7B1%7D%2C+%5Cldots%2C+%5Comega_%7Bn%7D%5E%7Bn+-+1%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
![[\omega_{n}^{0}, \omega_{n}^{2}, \ldots, \omega_{n}^{n - 2}]](https://s0.wp.com/latex.php?latex=%5B%5Comega_%7Bn%7D%5E%7B0%7D%2C+%5Comega_%7Bn%7D%5E%7B2%7D%2C+%5Cldots%2C+%5Comega_%7Bn%7D%5E%7Bn+-+2%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
![[\omega_{n}^{0}, \omega_{n}^{4}, \ldots, \omega_{n}^{n - 4}]](https://s0.wp.com/latex.php?latex=%5B%5Comega_%7Bn%7D%5E%7B0%7D%2C+%5Comega_%7Bn%7D%5E%7B4%7D%2C+%5Cldots%2C+%5Comega_%7Bn%7D%5E%7Bn+-+4%7D%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

We pair each 
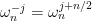

![[P(\omega_{n}^{0}), P(\omega_{n}^{1}), \ldots, P(\omega_{n}^{n - 1})]](https://s0.wp.com/latex.php?latex=%5BP%28%5Comega_%7Bn%7D%5E%7B0%7D%29%2C+P%28%5Comega_%7Bn%7D%5E%7B1%7D%29%2C+%5Cldots%2C+P%28%5Comega_%7Bn%7D%5E%7Bn+-+1%7D%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
![[P_{\text{even}}(\omega_{n}^{0}), P_{\text{even}}(\omega_{n}^{2}), \ldots, P_{\text{even}}(\omega_{n}^{n - 2})]](https://s0.wp.com/latex.php?latex=%5BP_%7B%5Ctext%7Beven%7D%7D%28%5Comega_%7Bn%7D%5E%7B0%7D%29%2C+P_%7B%5Ctext%7Beven%7D%7D%28%5Comega_%7Bn%7D%5E%7B2%7D%29%2C+%5Cldots%2C+P_%7B%5Ctext%7Beven%7D%7D%28%5Comega_%7Bn%7D%5E%7Bn+-+2%7D%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
![[P_{\text{odd}}(\omega_{n}^{0}), P_{\text{odd}}(\omega_{n}^{2}), \ldots, P_{\text{odd}}(\omega_{n}^{n - 2})]](https://s0.wp.com/latex.php?latex=%5BP_%7B%5Ctext%7Bodd%7D%7D%28%5Comega_%7Bn%7D%5E%7B0%7D%29%2C+P_%7B%5Ctext%7Bodd%7D%7D%28%5Comega_%7Bn%7D%5E%7B2%7D%29%2C+%5Cldots%2C+P_%7B%5Ctext%7Bodd%7D%7D%28%5Comega_%7Bn%7D%5E%7Bn+-+2%7D%29%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
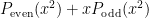
This leads to the naive FFT code:
from math import pi
from math import sin
from math import cos
def get_omega(n):
theta = 2 * pi / n
omega = cos(theta) + sin(theta) * 1j
return omega
def naive_FFT(P):
# P is the coefficient representation
# P = [a_{0}, a_{1}, ..., a_{n-1}]
# current we assume n = 2^{k}
n = len(P)
half_n = n // 2
if n == 1:
return P # constant function
omega = get_omega(n)
P_even, P_odd = P[::2], P[1::2]
V_even, V_odd = naive_FFT(P_even), naive_FFT(P_odd)
V = [0] * n # the value representation
for j in range(half_n):
V[j] = V_even[j] + omega ** j * V_odd[j]
V[j + half_n] = V_even[j] - omega ** j * V_odd[j]
return V
Feed 
Now we can apply Fourier transform to a coefficient representation to get the corresponding value representation, and the multiplication in the value representation form is easy to implement, what remains to solve is the inverse Fourier transform.
In the matrix-vector form for 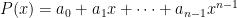
Note that the character table of 
To get the inverse Fourier transform, we can just use the inverse of the matrix:
Exercise 2: Check that the inverse DFT matrix is the inverse of the DFT matrix.
The difference between DFT and FFT is just the way of calculating these matrix-vector forms, where DFT uses the direct matrix-vector multiplication way in
The inverse DFT matrix leads to the naive IFFT code:
def naive_IFFT(V, is_outest_layer=False):
# V is the value representation
# w means omega_{n}
# V = [P(w^{0}), P(w^{1}), ..., P(w^{n-1})]
# current we assume n = 2^{k}
n = len(V)
half_n = n // 2
if n == 1:
return V # constant function
omega = 1.0 / get_omega(n) # omega_{n}^{-1}
V_even, V_odd = V[::2], V[1::2]
P_even, P_odd = naive_IFFT(V_even), naive_IFFT(V_odd)
P = [0] * n # the value representation
for j in range(half_n):
P[j] = P_even[j] + omega ** j * P_odd[j]
P[j + half_n] = P_even[j] - omega ** j * P_odd[j]
if is_outest_layer:
for j in range(n):
P[j] /= n
return P
Use
If we ignore the little error, this is just the coefficient representation of
The following materials might not be that clear and might not be easy to understand, but I will try my best. (Some material cannot be expanded too much, otherwise that would cost too much space and might confuse the main part.)
The lowest layer of Diagram 1 is just the bit-reversal permutation index and there is a neat code to generate:
def get_BRI(length):
# Bit-Reversal Index
n = 1
k = -1
while n < length:
n <<= 1
k += 1
BRI = [0] * n
for i in range(n):
BRI[i] = (BRI[i >> 1] >> 1) | ((i & 1) << k)
return BRI
It is more easy to see in a tabular (an example of 
Use this we can implement the Cooley–Tukey FFT algorithm, which is the most common FFT algorithm. Further, with proper manner of coding, we can devise an in-place algorithm that overwrites its input with its output data using only 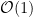
def FFT(X, length, is_inverse=False):
# X : input, either coefficient representation
# or value representation
# length : how much values need to evaluate
# is_inverse : indicate whether is FFT or IFFT
inverse_mul = [1, -1][is_inverse]
BRI = get_BRI(length)
n = len(BRI)
X += [0] * (n - len(X))
for index in range(n):
if index < BRI[index]: # only change once
X[index], X[BRI[index]] = X[BRI[index]], X[index]
bits = 1
while bits < n:
omega_base = cos(pi/bits) + inverse_mul * sin(pi/bits) * 1j
j = 0
while j < n:
omega = 1
for k in range(bits):
even_part = X[j + k]
odd_part = X[j + k + bits] * omega
X[j + k] = even_part + odd_part
X[j + k + bits] = even_part - odd_part
omega *= omega_base
j += bits << 1
bits <<= 1
if is_inverse:
for index in range(length):
X[index] = X[index].real / n
# only the real part is needed
return X[:length]
Note that we could ignore the return part, since 

Because we use the complex number to implement the FFT algorithm, we can see that the error is hard to eliminate. Even though the initial polynomial is integer based, apply FFT to it, then apply IFFT, we would get a decimal list with some calculation error.
If we do the FFT in the field 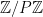
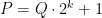


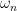
For arbitrary modulo 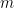

do NTT respectively on all 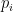
Note that during the NTT algorithm, the maximum intermediate value would not exceed 
We may say the FFT algorithm solves the convolution in the form of
in time
Back in Example 1, we have
(Not mandatory) Problem 1: Give the formula of Stirling numbers of the second kind:
Use the NTT with some modulo of the form 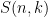
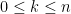
(Not mandatory) Problem 2: PE 537. Hint: If denote 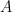

![A[n] = \sum_{x} [\pi(x) = n]](https://s0.wp.com/latex.php?latex=A%5Bn%5D+%3D+%5Csum_%7Bx%7D+%5B%5Cpi%28x%29+%3D+n%5D&bg=FFFFFF&fg=000&s=0&c=20201002)


![B[n] = \sum_{x, y} [\pi(x) + \pi(y) = n]](https://s0.wp.com/latex.php?latex=B%5Bn%5D+%3D+%5Csum_%7Bx%2C+y%7D+%5B%5Cpi%28x%29+%2B+%5Cpi%28y%29+%3D+n%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
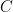

![C[n] = \sum_{x, y, z, w} [\pi(x) + \pi(y) + \pi(z) + \pi(w) = n]](https://s0.wp.com/latex.php?latex=C%5Bn%5D+%3D+%5Csum_%7Bx%2C+y%2C+z%2C+w%7D+%5B%5Cpi%28x%29+%2B+%5Cpi%28y%29+%2B+%5Cpi%28z%29+%2B+%5Cpi%28w%29+%3D+n%5D&bg=FFFFFF&fg=000&s=0&c=20201002)

There are bunch of similar algorithms, for example, fast Walsh–Hadamard transform (FWHT) and fast wavelet transform (FWT). FWHT can solve the general convolution
in time complexity 
Using FFT, we can do a lot of things for polynomials fast, for instance, for a polynomial 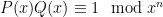




(Not mandatory) Problem 3: PE 258. Hint: Consider the Cayley–Hamilton theorem (
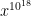

FFT is also used to transform the time domain to the frequency domain in the signal area, while IFFT is used to transform reverse.
In the artical [Machine Learning from a Continuous Viewpoint I] by Weinan E, the Fourier representation
can be considered as a two-layer neural network model with activation function 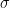

In the above figure, 


References
- https://www.nayuki.io/page/number-theoretic-transform-integer-dft
- https://www.geeksforgeeks.org/fast-fourier-transformation-poynomial-multiplication/
- Thomas H. Cormen, Charles E. Leiserson, and Ronald L. Rivest. Introduction to Algorithms CHAPTER 32: POLYNOMIALS AND THE FFT.
- https://jakevdp.github.io/blog/2013/08/28/understanding-the-fft/
- Polynomial Multiplication and Fast Fourier Transform: Yan-Bin Jia
- https://www.youtube.com/watch?v=h7apO7q16V0
- Weinan, E., Ma, C., & Wu, L. (2020). Machine learning from a continuous viewpoint, I. Science China Mathematics, 63(11), 2233-2266.
- Ceccherini-Silberstein. Discrete Harmonic Analysis Chapter 5.
- https://github.com/wcysai/FFT-and-Polynomial-Operations-slides-/blob/master/FFT%20and%20Polynomial%20Operations.pdf
- https://alan20210202.github.io/2020/08/07/FWHT/
- Pan, H., Dabawi, D., & Cetin, A. E. (2021). Fast Walsh-Hadamard Transform and Smooth-Thresholding Based Binary Layers in Deep Neural Networks. arXiv preprint arXiv:2104.07085.